













„ģ„ӄ唼
„ģ„ӄ唼øåŹŌ”£°ĶĮ³¤Č¤·¤ĘĘę¤ĪĀ椤„ׄķ„»„Ć„µ¤ĪĄµĀĪ¤Ė”¤“šĖÜ„Ę„¹„ȤĒ²ÄĒ½¤ŹøĀ¤źĒ÷¤Ć¤Ę¤ß¤æ
Ryzen Threadripper 1950X
Ryzen Threadripper 1920X
 |
””„ģ„ӄ唼Į°ŹŌ¤Ē¤Ļ”¤„Ž„ė„Į„¹„ģ„Ƅɤ¬Ķøś¤Ź„¢„ׄź„±”¼„·„ē„ó¤ņ¼Ā¹Ō¤¹¤ėøĀ¤ź”¤1950X¤¬2017ĒÆ8·īĆę½Ü»žÅĄ¤ĒĄ¤³¦ŗĒ¹āĄĒ½¤ņ»ż¤Ä¤³¤Č¤Č”¤1920X¤Ļʱ¤ø„愤„ß„ó„°¤Ė¤Ŗ¤±¤ėIntel¤ĪHEDT»Ō¾ģøž¤±ŗĒ¾å°Ģ„ā„Ē„ė¤Ē¤¢¤ė”ÖCore i9-7900X”×”Ź°Ź²¼”¤7900X”Ė¤Čøß³Ń¤Ī„Ž„ė„Į„¹„ģ„Ć„ÉĄĒ½¤ņ»ż¤Ä¤³¤Č¤ņ¤ŖÅĮ¤Ø¤·¤æ”£”ÖĒ椤¤«”©”פȤ¤¤¦µæĢä¤ĖĀŠ¤¹¤ė²óÅś¤āĮ°ŹŌ¤Ē¤ŖÅĮ¤ØŗѤߤŹ¤Ī¤Ē”¤Ģ¤ĘɤȤ¤¤¦æĶ¤Ļ¤¼¤Ņ°ģÅŁĘɤó¤Ē¤ā¤é¤Ø¤ģ¤Š¤Č»×¤¦”£
Ryzen Threadripper„ģ„ӄ唼Į°ŹŌ”£ø½»žÅĄ¤ĒĄ¤³¦ŗĒ¹ā¤Ī„Ž„ė„Į„¹„ģ„Ć„ÉĄĒ½¤ņ°ś¤Ć¤µ¤²”¤AMD¤¬„Ļ„¤„Ø„ó„É„Ē„¹„Æ„Č„Ć„×PC»Ō¾ģ¤Ų“Ō¤Ć¤Ę¤¤æ
””ŗ£²ó¤Ļ”¤Į°ŹŌ¤ĪŗĒøå¤ĒĶ½¹š¤·¤Ę¤¤¤æ¤Č¤Ŗ¤ź”¤¤ā¤¦¾Æ¤·„ß„Æ„ķ¤Ź»ėÅĄ¤«¤éRyzen Threadripper¤ĪĘĆĄ¤ņÄ“¤Ł”¤¤É¤Ī¤č¤¦¤Ź²ÄĒ½Ą¤ņ»ż¤ÄCPU¤Ź¤Ī¤«¤ņ¹Ķ¤Ø¤Ę¤ß¤ė¤³¤Č¤Ė¤·¤æ¤¤”£
CPU„³„¢¤Ī„ź„Ó„ø„ē„ó¤ä„¹„Ę„Ć„Ō„ó„°¤ĻRyzen 7„·„ź”¼„ŗ¤Čʱ°ģ¤«”©
 |
 |
””“ŹĆ±¤Ė¤Ŗ¤µ¤é¤¤¤·¤Ę¤Ŗ¤Æ¤Č”¤UMA¤ĻCPU¤¬„į„ā„ź¶õ“Ö¤ĖĀŠ¤·¤Ę°ģĪ§¤ĪĀ®ÅŁ¤äĆŁ±ä¤Ē„¢„Æ„»„¹¤Ē¤¤ė„·„¹„Ę„ą¤Ē”¤¤³¤ģ¤Ž¤Ē¤Ī„Ē„¹„Æ„Č„Ć„×øž¤±PC¤ĪCPU¤Ļ¤¹¤Ł¤Ę¤³¤ģ¤Ą”£
””°ģŹż”¤NUMA¤ĻŹ£æō¤ĪCPU¤¬¤½¤ģ¤¾¤ģ¼«Į°¤Ī„į„ā„ź„³„ó„Č„ķ”¼„é¤ņ»ż¤Į”¤„į„ā„ź¶õ“Ö¤ĖĀŠ¤·¤Ę°ģĪ§¤ĪĀ®ÅŁ¤äĆŁ±ä¤Ē¤Ļ„¢„Æ„»„¹¤Ē¤¤Ź¤¤„·„¹„Ę„ą¤Ē¤¢¤ė”£„Ž„ė„Į„½„±„ƄȤĪ„µ”¼„Š”¼µ”¤¬NUMA¤Īŵ·æ¤Ē”¤³Ę„½„±„ƄȤĪCPU¤Ļ¼«æȤ¬»ż¤Ä„į„ā„ź„³„ó„Č„ķ”¼„é¤ĖĄÜĀ³¤µ¤ģ¤æ„į„ā„ź¤ĖĀŠ¤·¤Ę¹āĀ®¤Ė„¢„Æ„»„¹¤Ē¤¤ė¤¬”¤Ā¾¤Ī„½„±„ƄȤĪCPU¤Ī„į„ā„ź„³„ó„Č„ķ”¼„é¤ĖĄÜĀ³¤µ¤ģ¤æ„į„ā„ź¤ĖĀŠ¤·¤Ę¤Ļ„¢„Æ„»„¹ĆŁ±ä¤¬Ąø¤ø¤ė”£
 |
””¤½¤·¤Ę¤ā¤¦1¤Ä”¤Ąč¹Ō¤·¤Ę»Ō¾ģ¤ĖÅŠ¾ģ¤·¤Ę¤¤¤ėRyzen 7”¦5”¦3¤Č”¤CPU„³„¢¼ž¤ź¤Ė²æ¤«°ć¤¤¤Ļ¤¢¤ė¤Ī¤«¤Ź¤¤¤Ī¤«¤āµ¤¤Ė¤Ź¤ė¤Č¤³¤ķ¤Ą”£
””¤Č¤¤¤¦¤ļ¤±¤Ē”¤¤Ž¤ŗ¤Ļ”ÖCPU-Z”×”ŹVerson 1.80”Ė¤Īɽ¼Ø¤«¤é³ĪĒ§¤·¤Ę¤ß¤ė¤Č”¤”ÖRevision”×Ķó¤¬Ryzen 7¤ČŹŃ¤ļ¤Ć¤Ę¤¤¤Ź¤¤¤³¤Č¤¬Ź¬¤«¤Ć¤æ”£²¼¤Ė¼Ø¤·¤æ¤Ī¤Ļ”¤1950X¤Č1920X”¤¤½¤·¤Ę”ÖRyzen 7 1800X”×”Ź°Ź²¼”¤1800X”Ė¤ĪCPU-Zɽ¼Ø¤Ą¤¬”¤”ÖFamily”פ«¤é”ÖRevision”פŽ¤Ē¤Ī¤¹¤Ł¤Ę¤ĒRyzen Threadripper¤ČRyzen¤Īɽµ¤Ļ¶¦ÄĢ¤Ą”£¤Ä¤Ž¤ź”¤Ryzen Threadripper¤Ļ”¤”ÖRyzen 7¤ņ”¤Infinity Fabric¤ĒMCM¤Č¤·¤Ę¼ĀĮõ¤·¤æĄ½ÉŹ”פȤ¤¤¦²ÄĒ½Ą¤¬¹ā¤Æ¤Ź¤ė”£¤Ē¤Ļ”¤ĖÜÅö¤Ė¤½¤¦¤Ź¤Ī¤«”©””¤³¤³¤ā„Į„§„Ć„Æ¤·¤Ę¤¤¤¤æ¤¤„Ż„¤„ó„ȤȤ¤¤¦¤³¤Č¤Ė¤Ź¤ė¤Ą¤ķ¤¦”£
””¤Ź¤Ŗ”¤Infinity Fabric”Ź¤äMCM”Ė¤Ė¤Ä¤¤¤Ę¤Ļ„ģ„ӄ唼Į°ŹŌ¤Ē¾Ņ²šŗѤߤŹ¤Ī¤Ē”¤”Ö¤Ź¤ó¤Ą¤Ć¤±”©”פȤ¤¤¦æĶ¤ĻĮ°ŹŌ¤ņ»²¾Č¤·¤Ę¤Ū¤·¤¤”£
 |
 |
 |
””¤Č¤¤¤¦¤ļ¤±¤Ē”¤¤µ¤Ć¤½¤Æ„Ę„¹„Č·ė²Ģ¤Ī¹Ķ»”¤ĖĘž¤Ć¤Ę¤¤¤¤æ¤¤”£
””„ģ„ӄ唼Į°ŹŌ¤ĒŗĘ»°¤ŖĆĒ¤ź¤·¤æ¤Č¤Ŗ¤ź”¤Ryzen Threadripper¤ĪĀߤ·½Š¤·“ü“Ö¤ĻĆ»¤Æ”¤É®¼Ō¤Ī¼źøµ¤Ė¤Ļ¤¹¤Ē¤Ė¤Ź¤¤”£„Ę„¹„Č„·„¹„Ę„ą¤ä“šĖÜĄßÄź¤ņŹŃ¹¹¤·¤Ę„Ę„¹„Ȥ¹¤ė¤³¤Č¤Ź¤É¤Ļ¤Ē¤¤ė¤Ļ¤ŗ¤ā¤Ź¤Æ”¤Ć»¤¤»īĶŃ“ü“Ö¤ĪĆę¤Ē”¤1950X¤Č1920X”¤¤½¤·¤ĘČę³ÓĀŠ¾Ż¤Ē¤¢¤ė1800X”¤7900X”¤¤½¤·¤Ę”ÖCore i7-7700K”×”Ź°Ź²¼”¤7700K”Ė¤ņĶѤ¤¤Ę½øĆęÅŖ¤Ė¼čĘĄ¤·¤æ„Ē”¼„æ¤Ī¤¦¤Į”¤Į°ŹŌ¤Ē·Ēŗܤ·¤Ę¤¤¤Ź¤¤¤ā¤Ī¤ņŗܤ»¤ė“¶¤ø¤Ė¤Ź¤ė”£
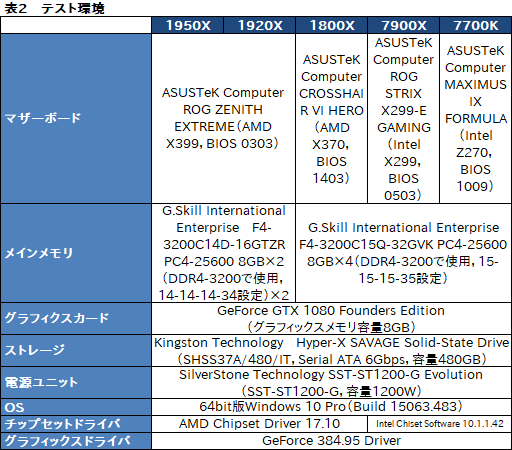
””¤Č¤¤¤¦¤ļ¤±¤Ē”¤5Ą½ÉŹ¤Ī¼ē¤Ź„¹„Ś„Ć„Æ¤Ļɽ1¤Ī¤Č¤Ŗ¤ź¤Ą”£
 |
””„Ę„¹„ȓĶ¤Ļɽ2¤Ī¤Č¤Ŗ¤ź¤Ē”¤¤³¤Į¤é¤ā¤ā¤Į¤ķ¤óĮ°ŹŌ¤ČŹŃ¤ļ¤é¤Ź¤¤”£
 |
Ryzen 7Čę¤ĒĢó2ĒܤĪĄĒ½¤ņ³ĪĒ§”£ø«¤«¤±¤Ī„į„ā„ź„Š„¹ĀÓ°čÉż¤ĻNUMA¤Ī¤Ū¤¦¤¬Āē¤¤¤”©
””°Ź²¼”¤Ę±¤ø„Ę„¹„Č¹ąĢܤĪ„Ę„¹„Č·ė²Ģ¤ņŹĀ¤Ł¤ė¾ģ¹ē¤Ē¤¢¤Ć¤Ę¤ā”¤æō»ś¤ĪƱ°Ģ¤¬°Ū¤Ź¤ė¤Ź¤É”¤¤½¤Ī¤Ž¤Ž1¤Ä¤Ī„°„é„Õ¤Ē·Ēŗܤ¹¤ė¤Čø«¤Å¤é¤Æ¤Ź¤ė¾ģ¹ē¤Ļ„°„é„Õ¤ņŹ£æō¤ĖŹ¬¤±¤ė¤³¤Č¤ņ¤ŖĆĒ¤ź¤·¤Ä¤Ä”¤„Ę„¹„Č·ė²Ģ¤ņ½ē¤Ėø«¤Ę¤¤¤¤æ¤¤”£
””¤Ž¤ŗ¤Ļ”¤FinalWareĄ½¤Ī„·„¹„Ę„ą„Į„§„Ć„Æ”õ„Ł„ó„Į„Ž”¼„Æ„Ä”¼„ė”ÖAIDA64”×”ŹVersion 5.92.4300”Ė¤Ē¤¢¤ė”£
””5.92.4300ČĒAIDA64”Ź¤ĪEngineer Edition”Ė¤Ļ”¤„Ę„¹„Č»žÅĄ¤Ė¤Ŗ¤¤¤ĘRyzen Threadripper¤ĪĀŠ±ž¤¬ėš¤ļ¤ģ¤Ę¤¤¤Ź¤¤¤¬”¤AIDA64¤Ī„Ł„ó„Į„Ž”¼„ÆÉō¤ĻøÅŵÅŖ¤Źx86¤Ŗ¤č¤Óx87ĢæĪį¤äSSE”¤AVX”¤AVX-2ĢæĪį¤ņ»ČĶѤ·¤Ę¤¤¤ė¤æ¤į”¤ĘĆŹĢ¤ŹĀŠ±ž¤ņ¹Ō¤¦¤Ž¤Ē¤ā¤Ź¤«¤Ć¤æ¤ź¤Ļ¤¹¤ė”£AIDA64¤Ī„¹„³„¢¤Ļ”¤”Ö½¾Ķč·æ¤ĪCPU”פȤ·¤Ę¤ĪĀ®ÅŁČę³ÓĶѤȤ·¤Ę°ÕĢ£¤ņ»ż¤Ä¤Č¹Ķ¤Ø¤Ę¤ā¤é¤Ø¤Š¤¤¤¤¤Ą¤ķ¤¦”£
””¤³¤³¤Ē¤Ī„Ę„¹„ȤĒ¤Ļ”¤Ryzen¤Ī”ÖPrecision Boost”פŖ¤č¤Ó”ÖXFR”×”¤Core¤Ī”ÖEnhanced Intel SpeedStep Technology”×”Ź°Ź²¼”¤EIST”Ė¤Ŗ¤č¤Ó”ÖIntel Turbo Boost Technology”×”Ź°Ź²¼”¤Turbo Boost”Ė¤Č”¤7900X¤Ē¤Ļ”ÖIntel Turbo Boost Max Technology 3.0”×”Ź°Ź²¼”¤TBMax3”Ė¤Č¤¤¤Ć¤æ”¤¼«Ę°¤ĪĘ°ŗī„Æ„ķ„Ć„ÆŹŃ¹¹µ”Ē½¤Ļ¤¹¤Ł¤ĘĶøś²½¤·¤æ”£
””¤Ž¤ŗ¤Ļ”¤PC„ę”¼„¶”¼¤¬¾ļĶѤ·¤Ę¤¤¤ė¾õĀÖ¤Ē”¤Ryzen Threadripper¤ČČę³ÓĀŠ¾Ż¤Ė¤É¤ĪÄųÅŁ¤Ī°ć¤¤¤¬¤¢¤ė¤Ī¤«¤ņø«¤Ę¤¤¤³¤¦¤Č¤¤¤¦¤ļ¤±¤Ą”£
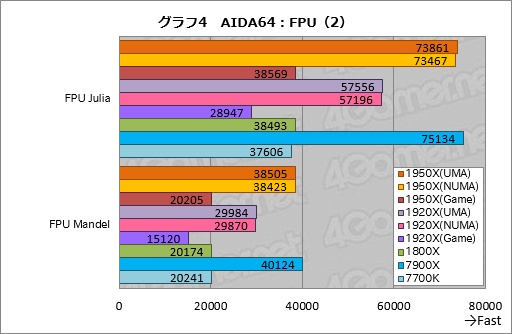
””¤Č¤¤¤¦¤ļ¤±¤Ē„°„é„Õ1¤Ļ”¤¼ē¤ĖĄ°æō±é»»¼ēĀĪ¤Ī„Ę„¹„Č·ė²Ģ¤«¤é”¤4¹ąĢܤņČ“¤½Š¤·¤æ¤ā¤Ī¤Ė¤Ź¤ė”£
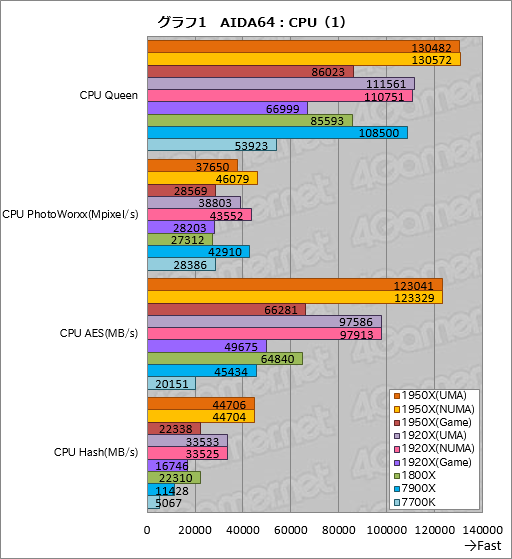 |
”””ÖCPU Queen”פĻ”¤øÅŵÅŖ¤ŹN„Æ„¤”¼„óĢäĀź”ŹN-Queens Problem”¤n
””·ė²Ģ¤ņø«¤ė¤Č”¤1950X¤ĪUMA¤ČNUMA¤Ļ¤Ū¤Üʱ¤ø„¹„³„¢¤Ē”¤7900X¤ĖĀŠ¤·¤ĘĢó20”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤·”¤ĢĄ¤é¤«¤Ėʬ°ģ¤ÄČ“¤±¤Ę¤¤¤ė”£Ę°ŗī„Æ„ķ„Ć„Æ¤¬°Ū¤Ź¤ė¤æ¤į”¤Ć±½ćČę³Ó¤Ļ¤Ē¤¤Ź¤¤¤ā¤Ī¤Ī”¤7900X¤ņCPU„³„¢æō¤Ē6“š¾å²ó¤ė1950X¤¬Ę²”¹¤Ī¾”Ķų¤Č¤¤¤Ć¤æ¤Č¤³¤ķ¤Ą¤ķ¤¦¤«”£
””1920X¤Ī¤Ū¤¦¤Ļ”¤ĀŠ7900X¤ĒUMA»ž¤ĖĢó3”ó”¤NUMA»ž¤ĖĢó2”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤æ”£¤Ŗ¤Ŗ¤ą¤ĶĘ±Åł„ģ„Ł„ė¤Ī„¹„³„¢¤Č¤¤¤¦Ķż²ņ¤Ē¤¤¤¤¤«¤Č»×¤¦”£
””1800X¤Ī„¹„³„¢¤¬7900X¤ĖĀŠ¤·¤ĘĢó79”ó¤Ē”¤¤Ū¤Ü„³„¢æōČę¤Ė¤Ź¤Ć¤Ę¤¤¤ė¤³¤Č¤ņ¹Ķ¤Ø¤ė¤Č”¤1950X¤Ŗ¤č¤Ó1920X¤Ī„¹„³„¢¤Ļ¤ā¤¦°ģĄ¼¤Ū¤·¤¤¤Č¤³¤ķ¤Ē¤Ļ¤¢¤ė”£¤³¤Ī„¹„³„¢¤«¤é¤Ļ”¤”ÖCPU Queen¤Ī¤č¤¦¤ŹĆ±½ć¤Ź„Ł„ó„Į„Ž”¼„ƤĒ¤¢¤Ć¤Ę¤ā”¤Inifinity Fabric¤ĒĮźøߥÜĀ³¤Č¤Ź¤ė2„Ą„¤¹½Ą®¤ĪRyzen Threadripper¤Ē„ź„Ė„¢¤ĖĄĒ½¤¬æ¤Ó¤ė¤ļ¤±¤Ē¤Ļ¤Ź¤¤”פ³¤Č¤ņĘɤ߼č¤ė¤Ł¤¤Ź¤Ī¤«¤ā¤·¤ģ¤Ź¤¤”£
””¤Ź¤Ŗ”¤UMA¤ČNUMA¤Ī°ć¤¤¤Ļ”¤CPU Queen¤Ė¤Ŗ¤¤¤Ę¤Ļ¤Ū¤Üøķŗ¹ČĻ°Ļ¤Ē°ģĆפČøĄ¤Ć¤Ę¤¤¤¤”£N„Æ„¤”¼„ó¤ĪƵŗ÷¤Č¤¤¤¦Čę³ÓÅŖ”¤„·„ó„ׄė¤ŹĢäĀź¤Ą¤ČNUMA¤Ī¤Ū¤¦¤¬ĶĶų¤Ė¤Ź¤ė¤«¤Č»×¤Ć¤Ę¤¤¤æ¤Ī¤Ē”¤¤ä¤ä°Õ³°¤Ą”£
””¤Ž¤æ”¤1950X¤Ī”ÖGame Mode”פČ1800X¤Č¤Ē”¤„¹„³„¢¤¬¤Ū¤Üʱ¤ø¤Ź¤Ī¤ĻĢĢĒņ¤¤”£8„³„¢16„¹„ģ„Ć„É²½¤·¤æ1950X¤ĪGame Mode¤Ļ”¤CPU Queen¤Ą¤Č1800X¤Č¤Ū¤ÜĘ±Åł¤ĪĄĒ½¤ņ»ż¤Ä¤Č¤¤¤¦¤³¤Č¤Ē¤¢¤ė”£
””Ā³¤Æ”ÖCPU PhotoWorxx”פĻ”¤Ą°æō±é»»¤ņ»Č¤Ć¤æ¼Ģææ¤Ī²Ć¹©½čĶż¤ņ¹Ō¤¦„Ę„¹„ȤĒ”¤AVX¤äAVX2”¤SSE¤Č¤¤¤Ć¤æSIMD±é»»¤ņĀæĶѤ¹¤ė”£
””¤“Ķ÷¤Ī¤Č¤Ŗ¤ź”¤¤³¤³¤Ē¤ĻUMA¤ČNUMA¤Ī°ć¤¤¤¬¤Ļ¤Ć¤¤ź½Š¤Ę¤Ŗ¤ź”¤1950X¤Ē¤ĻUMA¤ĖĀŠ¤·¤ĘNUMA¤Ī„¹„³„¢¤¬Ģó22”ó”¤1920X¤Ē¤Ļʱ12”ó¹ā¤¤¤Č¤¤¤¦·ė²Ģ¤Ą¤Ć¤æ”£²čĮü¤Ī„Ō„Æ„»„ė½čĶż¤Ź¤Ī¤Ē”¤„į„ā„ź„¢„Æ„»„¹ĆŁ±ä¤¬ĪߥŃÅŖ¤Ėøś¤¤¤Ę”¤ĆŁ±ä¾õ¶·¤ĒĶĶų¤ŹNUMA¤Ī„¹„³„¢¤¬¹ā¤Æ¤Ź¤Ć¤æ²ÄĒ½Ą¤Ļ¤¢¤ź¤½¤¦¤Ą”£
””°ģŹż”¤ĀŠ7900X¤Ą¤Č1950X¤ĪNUMA„ā”¼„ɤĻĢó7”ó”¤1920X¤ĪNUMA„ā”¼„ɤĻĢó1”ó¹ā¤¤„¹„³„¢¤Č¤Ź¤Ć¤Ę¤¤¤ė”£„³„¢æō¤Ī°ć¤¤¤ņ¹Ķ¤Ø¤ė¤Č„®„ć„ƄפĻĀē¤¤Æ¤Ź¤¤¤¬”¤1800X¤¬ĀŠ7900X¤ĒĢó64”ó¤ĖÄĄ¤ß”¤7700K¤ČČꤣ¤Ę¤ā¤ļ¤ŗ¤«¤ĖÄ椤„¹„³„¢¤ņ¼Ø¤·¤Ę¤¤¤ė¤³¤Č¤ņ¹Ķ¤Ø¤ė¤Č”¤Ryzen Threadripper¤Ļ¤«¤Ź¤ź·ņĘ®¤·¤Ę¤¤¤ė¤Č¤āøĄ¤Ø¤ė”£
””¤³¤³¤ĒRyzen Threadripper¤ĪGame Mode¤ĖĢܤņ°Ü¤¹¤Č”¤1950X¤ĻĢó5”ó”¤1920X¤ĻĢó3”󔤤½¤ģ¤¾¤ģ1800X¤č¤ź¹ā¤¤„¹„³„¢¤Ą¤Ć¤æ”£AIDA64¤ĪĀ¾¤ĪĄ°æō±é»»¤Ī„Ę„¹„ȤĒ¤Ļ1950X¤ĪGame Mode¤Ī„¹„³„¢¤¬1920X¤Ī¤½¤ģ¤ĖĀŠ¤·¤ĘĢó30”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤¹¤ā¤Ī¤Ī”¤CPU Photo Workxx¤Ē¤ĻĢó1”ó¤·¤«ŹŃ¤ļ¤Ć¤Ę¤¤¤Ź¤¤¤Ī¤āĢÜĪ©¤ÄÅĄ¤ČøĄ¤Ø¤ė¤Ą¤ķ¤¦”£
””ø¶°ų¤Ļ²æ¤Č¤āøĄ¤Ø¤Ź¤¤¤¬”¤Ryzen·Ļ¤Ī3„³„¢¤ä4„³„¢¤Ē¤Ļ¹ā¤¤Ą®ĄÓ¤¬ĘĄ¤é¤ģ¤Ź¤¤„Ę„¹„ȤĄ”¤¤Č¹Ķ¤Ø¤é¤ģ¤ė”£
”””ÖCPU AES”פĻAES°Å¹ę²½¤ņ¹Ō¤¦„Ę„¹„Č”¤”ÖCPU Hash”פĻ„Ļ„Ć„·„åĆĶ¤ņµį¤į¤ė„Ę„¹„ȤĒ”¤Į°¼Ō¤Ē¤ĻAES-NIĢæĪį¤ņ”¤¤Ž¤æøå¼Ō¤Ē¤ĻSHAĢæĪį¤ņ¤½¤ģ¤¾¤ģĶѤ¤¤æ¤ā¤Ī¤Č¤Ź¤ė”£
””¤³¤Ī„Ę„¹„ȤĒ¤Ļ²įµī¤Ė1800X¤¬¹ā¤¤„¹„³„¢¤ņĆ”¤½Š¤·¤Ę¤¤¤æ¤¬”¤1950X¤Č1920X¤āRyzen¤Ź¤Ī¤Ē”¤¤ä¤Ļ¤ź„¹„³„¢¤Ļ¤Č¤Ę¤ā¹ā¤¤”£UMA¤ČNUMA¤ĪĪ¾„ā”¼„ɤĖ¤Ŗ¤¤¤Ę„¹„³„¢¤Ļøķŗ¹ČĻ°Ļ¤Ē°ģĆפ·¤Ę¤¤¤ė¤æ¤į”¤ŗ£²ó¤Ļ¤Ņ¤Č¤Ž¤ŗUMA„ā”¼„ɤĪ„¹„³„¢¤ņ“š½ą¤Č¤¹¤ė¤¬”¤ĀŠ7900X¤Ē1950X¤ĻCPU AES¤ĒĢó2.7ĒÜ”¤CPU Hash¤ĒĢó3.9ĒÜ”¤1920X¤ā½ē¤ĖĢó2.1ĒÜ”¤2.9ĒܤȤ¤¤¦°µÅŻÅŖ¤ŹĀēŗ¹¤ņÉÕ¤±¤Ę¤¤¤ė¤Ī¤¬ø«¤Ę¤Č¤ģ¤č¤¦”£
””1800X¤ĖĀŠ¤·¤Ę”¤1950X¤¬90”Į100”óÄųÅŁ”¤1920X¤¬Ģó50”ó¤Č”¤¤Ŗ¤Ŗ¤č¤½„³„¢æōŹ¬¤ĪĄĒ½øž¾å¤¬ĘĄ¤é¤ģ¤Ę¤¤¤ė¤Ī¤āĢܤņ¼ę¤Æ”£
””CPU AES¤äCPU Hash¤Ļ°Å¹ę²½¤Č¤¤¤¦„·„ó„ׄė¤Ź„Ę„¹„ȤĄ¤«¤é¤³¤½”¤„³„¢æōŹ¬¤ĪĄĒ½øž¾å¤¬ĘĄ¤é¤ģ¤ė¤Ī¤«¤ā¤·¤ģ¤Ź¤¤”£¤¤¤ŗ¤ģ¤Ė¤»¤čCPU AES¤ČCPU Hash¤Ī·ė²Ģ¤Ļ”¤„Ē„¹„Æ„Č„Ć„×PCĶŃÅÓ¤Ē¤Ļ¤¢¤Ž¤ź„į„ź„ƄȤ¬¤Ź¤¤¤ā¤Ī¤Ī”¤¤³¤Īæō»ś¤Ļ”¤Ryzen Threadripper¤Č“šĖÜÅŖ¤Ė¤Ļʱ¤øĄß·×¤Ī„µ”¼„Š”¼øž¤±CPU¤Ē¤¢¤ėEPYC¤Ė¤Č¤Ć¤Ę”¤ĮźÅö¤Ź¶Æ¤ß¤Ė¤Ź¤ė¤Ą¤ķ¤¦”£
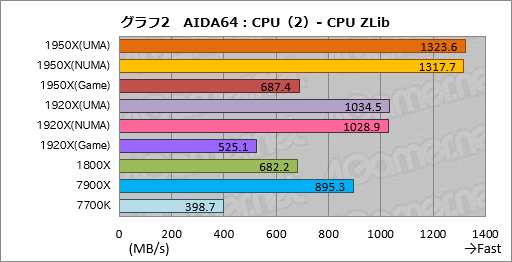
””Ą°æō±é»»·Ļ„Ę„¹„ȤĪ¤¦¤Į”¤„°„é„Õ2¤Ė¤Ž¤Č¤į¤æ¤Ī¤Ļ”¤øÅŵÅŖ¤Źx86ĢæĪį¤Ī¤ß¤ņ»Č¤Ć¤Ę„Ē”¼„æ¤Ī°µ½Ģ¤Ŗ¤č¤ÓÅø³«¤ņ¹Ō¤¦„Ę„¹„Č”ÖCPU Zlib”פĪ·ė²Ģ¤Ą”£
””1950X¤Č1920X¤Ē”¤UMA¤ČNUMAĪ¾„ā”¼„ɤĪ„¹„³„¢ŗ¹¤Ļøķŗ¹ÄųÅŁ”£°ģ±ž”¤UMA„ā”¼„ɤĪ¤Ū¤¦¤¬¤ļ¤ŗ¤«¤Ė¹ā¤¤·¹øž¤Ļø«¤»¤Ę¤¤¤ė¤ā¤Ī¤Ī”¤¤Ū¤Üʱ¤ø¤ČøĄ¤Ć¤Ę¤¤¤¤¤Ļ¤ŗ¤Ē¤¢¤ė”£
””ĀŠ7900X¤Ą¤Č”¤1950X¤Ī„¹„³„¢¤ĻĢó148”ó”¤1920X¤Ą¤ČĢó116”󔣄ź„Ė„¢¤Ē¤Ļ¤Ź¤¤¤ā¤Ī¤Ī”¤„³„¢æō¤Ė±ž¤ø¤æ„¹„³„¢¤¬ĘĄ¤é¤ģ¤Ę¤¤¤ė¤³¤Č¤ĻŹ¬¤«¤ė”£1800X¤¬7900X¤ĖĀŠ¤·¤ĘĢó76”ó”¤7700K¤ĖĀŠ¤·¤Ę¤ĻĢó171”ó¤Ī„¹„³„¢¤Č¤¤¤¦¤Č¤³¤ķ¤«¤é¤·¤Ę¤ā”¤”ÖRyzen„·„ź”¼„ŗ¤ĻøÅŵÅŖ¤Źx86ĢæĪį¤ņ¶ģ¼ź¤Ė¤·¤Ę¤¤¤Ź¤¤”פČøĄ¤¤ĄŚ¤Ć¤Ę¤¤¤¤¤č¤¦¤Ė»×¤ļ¤ģ¤ė”£
 |
””Ā³¤¤¤Ę¤ĻAIDA64¤«¤é”¤ÉāĘ°¾®æōÅĄ±é»»¤ņ»Č¤¦„Ę„¹„ȤĪ·ė²Ģ¤Ą”£¤Ž¤ŗ¤Ļ6¹ąĢÜĆę4¹ąĢܤĪ·ė²Ģ¤ņ„°„é„Õ3¤Ė¼Ø¤·¤æ”£
””¤³¤Ī¤¦¤Į”ÖFPU VP8”פĻVP8·Į¼°¤Ī„Ø„ó„³”¼„ɤņ¼Ā¹Ō¤¹¤ė„Ę„¹„ȤŹ¤Ī¤Ą¤¬”¤7900X¤Ī„ģ„ӄ唼»ž¤ČʱĶĶ¤Ė”¤ŗ£²ó¤ā¤Ū¤Č¤ó¤É²£ŹĀ¤Ó¤Ė¤Ź¤Ć¤Ę¤·¤Ž¤Ć¤æ”£Ryzen”¤Core¤Č¤ā”¤„³„¢æō¤Ė±ž¤ø¤æĄĒ½¤Ī°ć¤¤¤¬¤Ū¤ÜĄø¤ø¤Ę¤¤¤Ź¤¤¤Č¤¤¤¦ÉŌ»×µÄ¤Ź·ė²Ģ¤Ē¤¢¤ź”¤¤³¤³¤«¤é²æ¤«¤ņæäĀ¬¤¹¤ė¤Ī¤ĻČņ¤±¤æ¤Ū¤¦¤¬¤¤¤¤¤Ą¤ķ¤¦”£
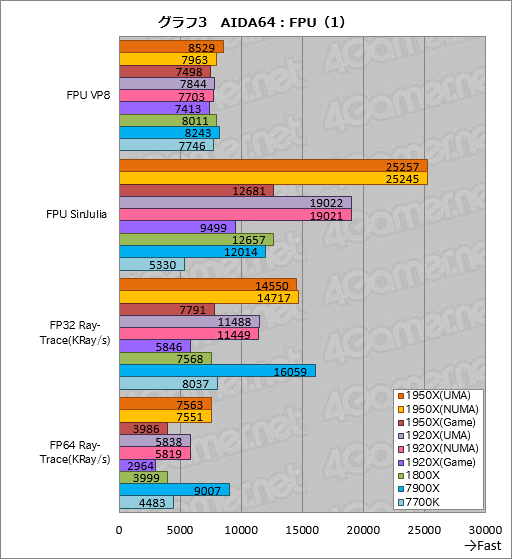 |
”””ÖFPU SinJulia”פĻ”¤øÅŵÅŖ¤Źx87ĢæĪį„»„ƄȤņ»Č¤¤”¤IEEEÉø½ą¤Ī80bit³ČÄ„ĄŗÅŁÉāĘ°¾®æōÅĄ±é»»¤Ē„ø„å„ź„¢½ø¹ē”ŹJulia set”¤Ź£ĮĒŹæĢĢ¾å¤Ē¤¢¤ė¾ņ·ļ¤ņĖž¤æ¤¹ÅĄ¤Ī½ø¹ē¤Ī¤³¤Č”Ė¤ņ·×»»¤¹¤ė„Ę„¹„ȤĒ¤¢¤ė”£
””1950X¤Č1920X¤Ē”¤UMA¤ČNUMAĪ¾„ā”¼„ɤĪ°ć¤¤¤Ļ¤Ź¤¤¤ČøĄ¤¤ĄŚ¤Ć¤ĘĢäĀź¤Ź¤¤”£ĀŠ7900X¤Ą¤Č1950X¤ĻĢó2.1ĒÜ”¤1920X¤ĻĢó1.58ĒܤȔ¤„³„¢æōČę¤ņĶ¤Ø¤æ„¹„³„¢ŗ¹¤ņ¶„¹ēĄ½ÉŹ¤ĖĀŠ¤·¤ĘÉÕ¤±¤Ę¤¤¤ė”£¤½¤ā¤½¤ā”¤8„³„¢16„¹„ģ„Ć„ÉĀŠ±ž¤Ī1800X¤¬10„³„¢20„¹„ģ„Ć„ÉĀŠ±ž¤Ī7900X¤č¤ź¼ć“³¤Ź¤¬¤é¹ā¤¤¤ļ¤±¤Ē”¤¤³¤Ī·ė²Ģ¤ĻĒ¼ĘĄ¤ČøĄ¤Ć¤Ę¤¤¤¤”£Ryzen¤ĻøÅŵÅŖ¤Źx87ĢæĪį„»„ƄȤņĘĄ°Õ¤Č¤·¤Ę¤¤¤ė¤ļ¤±¤Ą”£
””Ā³¤Æ”ÖFP32 Ray-Trace”פĻ”¤32bitƱĄŗÅŁÉāĘ°¾®æōÅĄ±é»»¤ņ»Č¤Ć¤Ę„ģ„¤„Č„ģ”¼„·„ó„°¤ņ¼Ā¹Ō¤¹¤ė„Ł„ó„Į„Ž”¼„ƤĒ”¤AVX·Ļ¤ĪSIMD±é»»¤äFMAĢæĪį¤ņ»ČĶѤ¹¤ė”£
””1950X¤Ē¤ĻNUMA„ā”¼„ɤĪ¤Ū¤¦¤¬UMA„ā”¼„ɤĖĀŠ¤·¤Ę¤ļ¤ŗ¤«¤Ė¹ā¤¤„¹„³„¢¤ņ»Ä¤·¤Ę¤¤¤ė¤ā¤Ī¤Ī”¤”Ö¤Ū¤Č¤ó¤É°ģĆהפČøĄ¤Ć¤Ę¤āŗ¹¤·»Ł¤Ø¤Ź¤¤ÄųÅŁ¤Ī°ć¤¤¤Ą”£
””ĀŠ7900X¤Ą¤Č”¤1950X¤Ļ91”Į92”óÄųÅŁ”¤1920X¤Ļ71”Į72”ó¤Ī„¹„³„¢¤Ē”¤„³„¢æō¤ņ¹Ķ¤Ø¤ė¤Č¤«¤Ź¤źŹ¬¤¬°¤¤”£1800X¤Ī„¹„³„¢¤Ė»ź¤Ć¤Ę¤ĻĢó47”ó¤Ē¤·¤«¤Ź¤Æ”¤7700K¤č¤ź¤āÄ椤„¹„³„¢¤Ą¤Ć¤æ¤ź¤ā¤¹¤ė¤Ī¤Ē”¤¤³¤Ī„Ę„¹„ȤĻRyzen¤Ė¤Č¤Ć¤ĘÉŌĶų¤Ź¤č¤¦¤Ē¤¢¤ė”£
””Į°½Ņ¤Ī¤Č¤Ŗ¤ź”¤Ryzen·Ļ¤ĻAVX-2¤Ī„¹„ė”¼„ׄƄȤ¬¤¢¤Ž¤ź¤č¤ķ¤·¤Æ¤Ź¤¤¤Ī¤Ē”¤FP32 Ray-Trace¤Ļ¤½¤ģ¤ņČæ±Ē¤·¤æ¤ā¤Ī¤Č¤¤¤¦¤³¤Č¤Ą¤ķ¤¦”£x87ĢæĪį„»„ƄȤņĮ°¤Ė¤·¤æ¤Č¤¤ĪĢµĮŠ¤Ö¤ź¤Č¤ĻĀŠ¾ŻÅŖ¤Ą”£
””64bitĒÜĄŗÅŁÉāĘ°¾®æōÅĄ±é»»¤ņĶѤ¤¤Ę„ģ„¤„Č„ģ”¼„·„ó„°¤ņ¹Ō¤¦”ÖFP64 Ray-Trace”פāFP32 Ray-Trace¤Č¤µ¤Ū¤ÉŹŃ¤ļ¤é¤Ź¤¤·ė²Ģ¤Ē”¤UMA¤ČNUMA¤Ī°ć¤¤¤Ļ¤Ū¤Ü¤Ź¤¤¤ČøĄ¤Ć¤Ę¤¤¤¤¤Ą¤ķ¤¦”£
””ĀŠ7900X¤Ą¤Č1950X¤¬Ģó84”ó”¤1920X¤¬Ģó65”ó”£1800X¤¬7700K¤ĖĘĻ¤¤¤Ę¤¤¤Ź¤¤ÅĄ¤ā”¤FP32 Ray-Trace¤ČŹŃ¤ļ¤é¤Ź¤¤”£
””„°„é„Õ4¤ĻÉāĘ°¾®æōÅĄ±é»»¤ņ»Č¤¦„Ę„¹„ȤĪ»Ä¤ź2¹ąĢܤĖ¤Ŗ¤±¤ė„¹„³„¢¤ņ¤Ž¤Č¤į¤æ¤ā¤Ī¤Ė¤Ź¤ė¤¬”¤”ÖFPU Julia”פĻĄč¤Ū¤É¾Ņ²š¤·¤æ„ø„å„ź„¢½ø¹ē¤Ī·×»»¤ņ32bitƱĄŗÅŁ¤Ē¹Ō¤¦¤ā¤Ī¤Ē”¤¤³¤Į¤é¤āSIMD±é»»¤äFMA¤ņ»ČĶѤ¹¤ė”£¤Č¤¤¤¦¤ļ¤±¤Ē”¤„¹„³„¢·¹øž¤ĻFPU Mandel¤Č¤Ū¤Č¤ó¤Éʱ¤ø¤Ą”£°ģ±žæؤģ¤Ę¤Ŗ¤Æ¤Č”¤7900X¤ČČꤣ¤Ę1950X¤Ī„¹„³„¢¤ĻĢó98”ó”¤1920X¤Ļ76”Į77”óÄųÅŁ¤Č¤¤¤Ć¤æ¤Č¤³¤ķ¤Ē¤¢¤ė”£
”””ÖFPU Mandel”פĻ64bitĒÜĄŗÅŁÉāĘ°¾®æōÅĄ±é»»¤Ē„Ž„ó„Ē„ė„Ö„ķ½ø¹ē”ŹMandelbrot set”¤„ø„å„ź„¢½ø¹ē¤ČʱĶĶ¤ĖŹ£ĮĒŹæĢĢ¾å¤Ē¤¢¤ė¾ņ·ļ¤ņĖž¤æ¤¹ÅĄ¤Ī½ø¹ē¤Ī¤³¤Č”Ė¤ņ¼Ā¹Ō¤¹¤ė„Ę„¹„ȤĒ”¤SIMD±é»»¤äFMA¤ņĀæĶѤ¹¤ė”£
””1950X¤Č1920X¤Ē¤Ļ”¤¤¢¤Ø¤ĘøĄ¤Ø¤ŠUMA„ā”¼„ɤĪ¤Ū¤¦¤¬„¹„³„¢¤Ļ¹ā¤¤¤ā¤Ī¤Ī”¤¤Ū¤Üʱ¤ø¤Čø«¤ė¤Ł¤¤Ą¤ķ¤¦”£ĀŠ7900X¤Ą¤Č1950X¤¬Ģó96”ó”¤1920X¤¬Ģó75”ó¤Ē”¤„³„¢æō¤Ėø«¹ē¤Ć¤æ„¹„³„¢¤ĻĘĄ¤é¤ģ¤Ę¤¤¤Ź¤¤”£1800X¤Ī„¹„³„¢¤¬7700K¤ČʱÄųÅŁ¤Č¤¤¤¦ÅĄ¤«¤é¤·¤Ę¤ā”¤Ryzen¤¬SIMD±é»»”ŹAVX”Ė¤äFMA¤ņÉŌĘĄ¼ź¤Ė¤·¤Ę¤¤¤ė¤³¤Č¤Ļ¤Ū¤Üµæ¤¤¤č¤¦¤¬¤Ź¤¤”£
 |
””°Ź¾å”¤„Æ„ķ„Ć„Æ¤ņĀ·¤Ø¤ŗ¤Ė1950X¤Č1920X¤Ī„¹„³„¢¤ņø«¤Ę¤¤æ¤¬”¤Āē»ØĒĤĖ¤Ž¤Č¤į¤ė¤Ź¤é”¤øÅŵÅŖ¤Źx86ĢæĪį¤äx87ĢæĪį¤Ē¤Ļ„³„¢æō¤Ėø«¹ē¤¦ĄĒ½¤¬ĘĄ¤é¤ģ¤ė¤ā¤Ī¤Ī”¤AVX·Ļ¤äFMAĢæĪį„»„ƄȤ¬»Č¤ļ¤ģ¤ė¤ČRyzen¤ĻÉŌĶų¤Ė¤Ź¤ė¤Č¤¤¤¦·¹øž¤ņ”¤Ryzen Threadripper¤Ē¤ā³ĪĒ§¤Ē¤¤ė”£
””¤Ž¤æ”¤¤³¤³¤Ž¤Ē¤¢¤Ø¤Ę¾Æ¤·¤·¤«æؤģ¤Ź¤«¤Ć¤æ¤¬”¤1950X¤ĪGame Mode¤Ė¤Ŗ¤±¤ė„¹„³„¢¤Ļ”¤1800X¤ČĘ±Åł¤«¤éĢó5”ó¹ā¤į¤Č¤¤¤¦·¹øž¤¬½Š¤Ę¤¤¤ė”£
””1950X¤Č1800X¤Īøų¾Ī¤ĪĘ°ŗī„Æ„ķ„Ć„Æ¤Ļ¤Ū¤Č¤ó¤ÉŹŃ¤ļ¤é¤ŗ”¤Game Mode¤Ē¤Ļ1800XĮźÅö¤Ī8„³„¢16„¹„ģ„ƄɤĖ¤Ź¤ė”£1800X¤č¤ź”¤¤ä¤ä¹ā¤į¤Ī„¹„³„¢¤ņ½Š¤¹·¹øž¤«¤é¤¹¤ė¤ČCPU„³„¢¤Ė²æ¤é¤«¤Ī²žĪɤ¬Ęž¤Ć¤æ²ÄĒ½Ą¤¬ČŻÄź¤Ē¤¤Ź¤¤”£¤·¤«¤·”¤°ģŹż¤Ē1950X¤Ļ1800X¤č¤źĀĪĄŃ¤¬Āē¤¤Æ”¤¤č¤Ć¤ĘĒ®ĶĘĪĢ¤āĀē¤¤Æ¤Ź¤ė¤Ī¤Ē”¤1800X¤č¤ź„Æ„ķ„Ć„Æ¤¬¾å¤¬¤ź¤ä¤¹¤¤²ÄĒ½Ą¤Ļ¤¢¤ė¤Ą¤ķ¤¦”£Ģó5”󤏤é„Æ„ķ„Ć„Æ¤Ī„Ö„ģ¤ĪČĻ°ĻĘā¤Č¤¤¤¦ø«Źż¤ā²ÄĒ½¤Ē”¤CPU„³„¢¤Ė²žĪɤ¬Ęž¤Ć¤æ¤ČĀØĆĒ¤¹¤ė¤Ī¤Ļ“ķø±¤Ą¤Č¹Ķ¤Ø¤é¤ģ¤ė”£
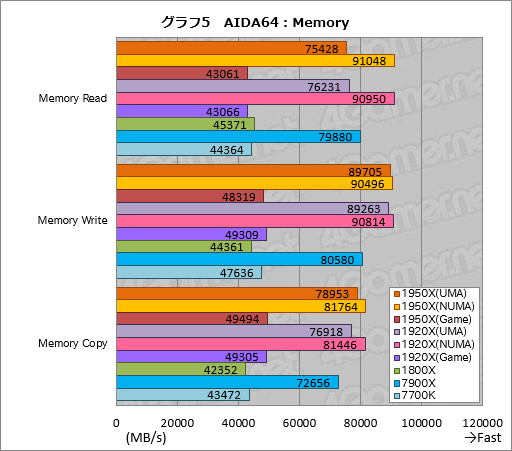
””¼”¤Ė„°„é„Õ5¤Ļ”¤”ÖMemory Read”×”ÖMemory Write”×”ÖMemory Copy”פȤ¤¤¦”¤„į„ā„ź“ŲĻ¢¤Ī„Ę„¹„Č·ė²Ģ¤ņ¤Ž¤Č¤į¤æ¤ā¤Ī¤Ė¤Ź¤ė”£
””¤³¤³¤Ē”Ö¤Ŗ¤ä”©”פȻפ¦¤«¤ā¤·¤ģ¤Ź¤¤”£1950X¤Č1920X¤Ē¤ĻNUMA„ā”¼„ɤĪ¤Ū¤¦¤¬UMA„ā”¼„ɤ褟¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤Ę¤¤¤ė¤«¤é¤Ą”£
””¶ńĀĪÅŖ¤Ėæō»ś¤ņø«¤Ę¤¤¤Æ¤Č”¤1950X¤ĒNUMA„ā”¼„ɤĻUMA„ā”¼„ɤĖĀŠ¤·¤ĘMemory Read¤ĒĢó21”ó”¤Memory Write¤ĒĢó1”ó”¤Memory Copy¤ĒĢó4”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤¹”£1920X¤ā½ē¤ĖĢó19”ó”¤Ģó2”ó”¤Ģó6”ó¹ā¤¤„¹„³„¢¤Ą”£”Ö„į„ā„ź„Š„¹ĀÓ°čÉż¤ĒĶĶų¤Ź¤Ī¤¬UMA”¤„į„ā„ź„¢„Æ„»„¹ĆŁ±ä¤ĒĶĶų¤Ź¤Ī¤¬NUMA”פȤ¤¤¦¤Ī¤¬AMD¤ĪøĄ¤¤Ź¬¤Ą¤¬”¤¤½¤ģ¤Č¤Ļ“°Į“¤ĖµÕ¤Ī·ė²Ģ¤Ē¤¢¤ė”£
 |
””¤Ź¤¼¤³¤ó¤Ź¤³¤Č¤Ė¤Ź¤Ć¤æ¤Ī¤«¤Ą¤¬”¤¤Ŗ¤½¤é¤Æ”¤AIDA64¤Ī„į„ā„ź„Ę„¹„Ȥ¬„Ž„ė„Į„¹„ģ„Ć„É²½¤µ¤ģ¤Ę¤¤¤ė¤³¤Č¤Ėø¶°ų¤¬¤¢¤ė¤Č”¤É®¼Ō¤Ļ¹Ķ¤Ø¤Ę¤¤¤ė”£
””NUMA„ā”¼„ɤĒ¤Ļ„Ę„¹„Č„¹„ģ„Ƅɤ¬ĘĆÄź¤ĪNUMA„Ī”¼„ɤĖ³ä¤źÅö¤Ę¤é¤ģ¤ė¤¬”¤UMA„ā”¼„ɤĒ¤ĻŹŖĶżÅŖ¤ŹNUMA„Ī”¼„ɤņĢµ»ė¤·¤Ę³ä¤źÅö¤Ę¤ė¤³¤Č¤Ė¤Ź¤ė”£¤½¤Ī·ė²Ģ¤Č¤·¤Ę”¤UMA„ā”¼„ɤĄ¤ČInifinity Fabric¤ņ²š¤·¤æ„į„ā„ź„¢„Æ„»„¹¤¬ČÆĄø¤·”¤Inifinity Fabric¤ĪķÕķŌ¤Ź¤É¤¬„į„ā„źĀÓ°č¤ņ°µĒ÷¤·¤æ¤Ī¤Ē¤Ļ¤Ź¤¤¤Ą¤ķ¤¦¤«”£¤½¤¦¤Ą¤Č¤¹¤ģ¤Š”¤„Ž„ė„Į„¹„ģ„ƄɤĒ„į„ā„ź¤Ė„¢„Æ„»„¹¤¹¤ė¾ģ¹ē¤Ļ”¤ĀÓ°čÉż¤Ē¤āNUMA¤¬ĶĶų¤Ė¤Ź¤ė¤«¤ā¤·¤ģ¤Ź¤¤”£
””1950X¤Č1920X¤ĪGame Mode¤Ē”¤„¹„³„¢¤¬1800X¤Čʱ¤ø¤«¤ä¤ä¹ā¤¤ÄųÅŁ¤ĖĪ±¤Ž¤ė¤Ī¤ā”¤AIDA64¤Ī„į„ā„ź„Ę„¹„Ȥ¬„Ž„ė„Į„¹„ģ„Ć„É²½¤µ¤ģ”¤Įķ¹ēĄĒ½¤ņø«¤Ę¤¤¤ė¤Č¤¹¤ģ¤Š”¤Ē¼ĘĄ¤Ē¤¤ė¤ā¤Ī¤ČøĄ¤Ø¤ė¤Č»×¤¦”£
””¤Ź¤Ŗ”¤¤³¤³¤Ē¤Ļ¤ā¤¦1¤Ä”¤1950X¤Č1920X¤Ī„¹„³„¢¤¬Ę±¤ø4ch„į„ā„ź„¢„Æ„»„¹»ÅĶĶ¤Ē¤¢¤ė7900X¤ņ¤Ŗ¤Ŗ¤ą¤Ķ¾å²ó¤ė¤³¤Č¤Ė¤āĆķĢܤĒ¤¤ė”£ŗŁ¤«¤Æø«¤ģ¤ŠUMA¤Ī1950X¤Ŗ¤č¤Ó1920X¤Ą¤ČMemory Read¤Ē7900X¤ņ²¼²ó¤ė¤¬”¤¤½¤ģ°Ź³°¤Ī„¹„³„¢¤ĻĶ„½Ø¤Ą”£
””Ryzen·Ļ¤Ē¤Ļ1800X¤ā”¤„鄤„Š„ė¤Ī7700K¤ĖĀŠ¤·¤ĘAIDA64¤Ī„į„ā„ź„Ę„¹„ȤĒ¹„Ą®ĄÓ¤ņ¾å¤²¤Ę¤¤¤ė”£„į„ā„ź¤ĪĘɤ߽Š¤·¤Ŗ¤č¤Ó½ń¤¹ž¤ß¤ĪĀÓ°čÉż¤Ē¤Ļ”¤1800X¤ĪĶ„½Ø¤µ¤ņ¤½¤Ī¤Ž¤ŽRyzen Threadripper¤¬¼õ¤±·Ń¤¤¤Ē¤¤¤ė¤Č¤¤¤¦Ķż²ņ¤Ē¤¤¤¤¤Ą¤ķ¤¦”£
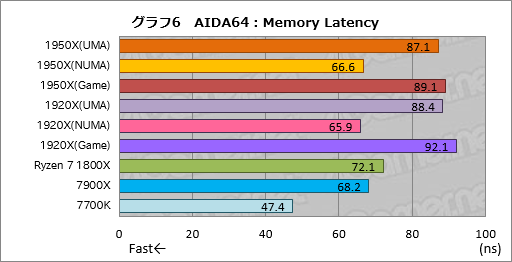
””ʱ¤ø„į„ā„ź“ŲĻ¢¤Ī„Ę„¹„Ȥ«¤é”¤„°„é„Õ6¤Ļ„į„ā„ź„¢„Æ„»„¹ĆŁ±ä¤ņø«¤ė”ÖMemory Latency”פĪ·ė²Ģ¤Ą”£¤³¤Į¤é¤ĻAMD¤ĪøĄ¤¤Ź¬¤É¤Ŗ¤ź”¤1950X¤Ē¤ā1920X¤Ē¤āNUMA„ā”¼„ɤĪ¤Ū¤¦¤¬UMA„ā”¼„ɤČČꤣ¤Ę20ns°Ź¾åĆ»¤¤¤Č¤¤¤¦„¹„³„¢¤¬½Š¤Ę¤¤¤ė”£ÉÕ¤±²Ć¤Ø¤ė¤Ź¤é”¤NUMA„ā”¼„ɤĪRyzen Threadripper¤Ļ1800X¤č¤ź¤āĶ„½Ø¤Ą”£
””°ģŹż¤Ēµ¤¤Ė¤Ź¤ė¤Ī¤ĻGame Mode¤Ī„¢„Æ„»„¹ĆŁ±ä¤Ē”¤„¹„³„¢¤Ļ¤Ź¤ó¤Č”¤UMA„ā”¼„ɤ褟Āē¤¤¤”£Game Mode¤Ļ„²”¼„ąøž¤±¤ĖĶŃ°Õ¤µ¤ģ¤Ę¤¤¤ė„ā”¼„ɤĖ¤ā“Ų¤ļ¤é¤ŗ”¤„į„ā„ź¤Ī„¢„Æ„»„¹ĆŁ±ä¤¬Āē¤¤¤¤Č¤Ź¤ė¤ČĪɹ„¤Ź„²”¼„ąĄĒ½¤¬ĘĄ¤é¤ģ¤Ź¤¤²ÄĒ½Ą¤¬¹ā¤Æ¤Ź¤Ć¤Ę¤·¤Ž¤¦”£
 |
””1¤Äµ¤¤Ė¤Ź¤Ć¤Ę¤¤¤ė¤Ī¤Ļ”¤„ģ„ӄ唼Į°ŹŌ¤Ē½Ņ¤Ł¤æ¤č¤¦¤Ė”¤É®¼Ō¤¬»īĶѤ·¤æ»žÅĄ¤Ē¤ĻAMDĄ½¤Ī„Į„唼„Ė„ó„°ĶŃ„½„Õ„Č„¦„§„¢”ÖRyzen Master Utility”×”Ź°Ź²¼”¤Ryzen Master”Ė¤¬Ģ¤“°Ą®¤Ē”¤Ryzen Master¤«¤éUMA¤ČNUMA¤ņĄŚ¤źĀŲ¤Ø¤ė¤³¤Č¤¬¤Ē¤¤Ź¤«¤Ć¤æÅĄ¤Ą”£
””¤ā¤·¤«¤¹¤ė¤Č”¤”ÖRyzen Master¤ĒGame Mode¤ņĮŖĀņ¤Ŗ¤č¤ÓŬĶѤ·¤æ¤Č¤¤ĖUMA¤«¤éNUMA¤ĖøĒÄź¤µ¤ģ¤ė¤Ļ¤ŗ¤¬”¤ŗ£²ó¤Ļµ”Ē½¤·¤Ę¤¤¤Ź¤«¤Ć¤æ”פȤ¤¤¦²ÄĒ½Ą¤Ļ¼Ī¤Ę¤¤ģ¤Ź¤¤”£
””ɾ²Į„„ƄȤĻÉ®¼Ō¤Ī¼źøµ¤ņµī¤Ć¤Ęµ×¤·¤¤¤æ¤į”¤¤ā¤Ļ¤ä³ĪĒ§¤·¤č¤¦¤ā¤Ź¤¤¤Ī¤Ą¤¬”¤É®¼Ō¤ĪæäĀ¬¤¬Ąµ¤·¤¤¤Č¤¹¤ė¤Č”¤Game Mode»ž¤Ī„į„ā„źĄĒ½¤Ļ¤ā¤Ć¤Č¾å¤¬¤Ć¤Ę¤ā¤Ŗ¤«¤·¤Æ¤Ļ¤Ź¤¤”£
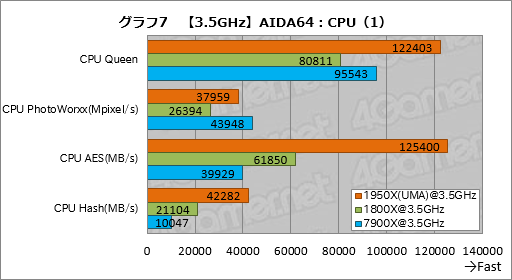
””¤µ¤Ę”¤¤³¤³¤Ž¤Ē¤ĻCPU¤ĪÄź³Ź„Æ„ķ„Ć„Æ¤ņĄßÄź¤·”¤ŗĒ¹āĄĒ½¤ņ“üĀŌ¤Ē¤¤ė¾õĀÖ¤Ē5¤Ä¤ĪCPU¤ņø«¤Ę¤¤æ¤¬”¤¤³¤³¤«¤é¤Ļ»²¹Ķ¤Ž¤Ē¤ĖĮ“„³„¢¤ĪĘ°ŗī„Æ„ķ„Ć„Æ¤ņ3.5GHz¤ĒøĒÄź¤·¤æ¾õĀÖ¤Ī„¹„³„¢¤āø«¤Ę¤Ŗ¤¤æ¤¤”£
””¤æ¤Ą¤·”¤Į°ŹŌ¤«¤éŗĘ»°¤Ī·«¤źŹÖ¤·¤Ē潤·Ģõ¤Ź¤¤¤¬”¤¤Č¤Ė¤«¤Æ»ž“Ö¤¬Ā¤ź¤Ź¤«¤Ć¤æ¤æ¤į”¤ŗ£²ó3.5GHzĄßÄź¤ņ¹Ō¤Ć¤æ¤Ī¤Ļ1950X¤ĪUMA„ā”¼„ɤČ1800X”¤7900X¤Ī¤ß¤Ą”£1950X¤ĪUMA„ā”¼„ɤČ1800X¤Ē¤ĻPrecision Boost¤Ŗ¤č¤ÓXFR¤ņĢµøś²½”¤7900X¤Ē¤ĻEIST¤ČTurbo Boost”¤TBMax 3.0¤ņĢµøś²½¤·¤Ę¤Ę¤¤¤ė”£
””„°„é„Õ7”¤8¤Ļ”¤AIDA64¤Ė¤Ŗ¤±¤ėĄ°æō±é»»„Ł„ó„Į„Ž”¼„ƤĪ·ė²Ģ¤Ą”£ĀŠ1800X¤Ēø«¤ė¤Č”¤1950X¤Ī„¹„³„¢¤ĻCPU Queen¤ĒĢó51”ó”¤CPU PhotoWorxx¤ĒĢó44”ó¹ā¤¤”£Ć±½ć¤ŹĆµŗ÷¤ņĀææō¤Ī„¹„ģ„ƄɤĒ½čĶż¤¹¤ėCPU Queen¤Ē¤Ļ”¤„³„¢æōŹ¬¤ĪĄĒ½øž¾å¤¬¤ā¤¦¾Æ¤·ĘĄ¤é¤ģ¤Ę¤ā¤¤¤¤µ¤¤Ļ¤¹¤ė¤ā¤Ī¤Ī”¤ĄĒ½¤¬¾å¤¬¤ė¤«¤É¤¦¤«¤Ļ„³”¼„ɤĪ½ń¤Źż¤Ė¤ā¤č¤ė¤æ¤į”¤¤Ź¤ó¤Č¤āøĄ¤Ø¤Ź¤¤”£
””CPU Queen¤Ą¤Č”¤„³„¢æō¤ĪĪĻ¤Ē1950X¤¬7900X¤ņ¾å²ó¤ė¤ā¤Ī¤Ī”¤SIMD±é»»¤¬ĀæĶѤµ¤ģ¤ėCPU PhtoWorkxx¤Ą¤Č1950X¤¬ÉŌĶų¤Ź¤ė¤Č¤¤¤Ć¤æ¶ń¹ē¤Ė”¤ĘĄ¼źÉŌĘĄ¼ź¤¬¤Ļ¤Ć¤¤źŹ¬¤«¤ģ¤Ę¤¤¤ė”£
””°ģŹż”¤CPU AES¤äCPU Hash¤Ē¤Ļ„³„¢æōŹ¬¤Ī¤¤ģ¤¤¤ŹĄĒ½øž¾å¤ņ³ĪĒ§¤Ē¤¤æ”£1950X¤Ī„¹„³„¢¤ĻĮ°¼Ō¤ĒĢó103”ó”¤øå¼Ō¤ĒĢó100”ó¹ā¤¤¤Ī¤Ē”¤”Ö¤¤Ć¤Į¤ź2ĒܔפȤ¤¤¦¤³¤Č¤Ė¤Ź¤ė”£
””Ʊ½ć¤Ź„Ę„¹„ȤĄ¤«¤é¤³¤½CPU„³„¢æō¤¬ĒܤĖ¤Ź¤Ć¤æ¤Ą¤±¤ĪĄĒ½øž¾å¤¬ĘĄ¤é¤ģ¤ė¤ļ¤±¤Ą¤¬”¤¤æ¤Ą”¤Inifinity Fabric¤ĪĮĒĄ¤ĪĪɤµ¤¬¤Ź¤±¤ģ¤Š¤³¤¦¤Ź¤é¤Ź¤¤¤Ī¤ā³Ī¤«¤Ą”£AMD¤¬Zen„Ž„¤„Æ„ķ„¢”¼„„Ę„Æ„Į„ć¤Īø°¤Č¤·¤Ę¤¤¤ėInifinity Fabric¤Ī¼ĀĪĻ¤¬¤ā¤æ¤é¤·¤æ·ė²Ģ¤Čø«¤Ę¤¤¤¤¤Ą¤ķ¤¦”£
 |
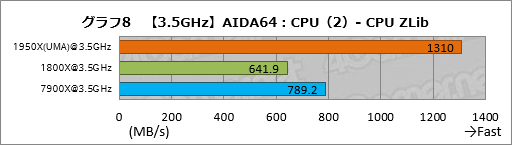 |
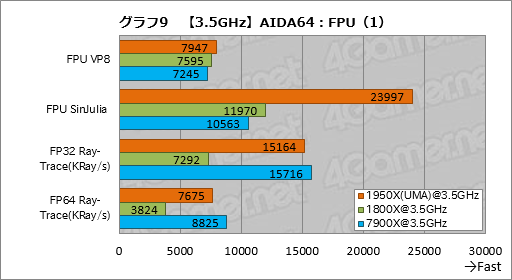
””ÉāĘ°¾®æōÅĄ±é»»„Ł„ó„Į„Ž”¼„ƤĪ·ė²Ģ¤Ļ„°„é„Õ9”¤10¤Ī¤Č¤Ŗ¤ź”£FPU VP8¤Ī„Ę„¹„Č·ė²Ģ¤Ļ¤³¤³¤Ē¤ā¤¢¤Ž¤źÅö¤Ę¤Ė¤Ź¤é¤Ź¤¤”£
””ĆķĢܤ·¤æ¤¤¤Ī¤Ļ”¤»Ä¤ė¤¹¤Ł¤Ę¤Ī„Ę„¹„Č¹ąĢܤĒ”¤1800X¤ĖĀŠ¤·¤Ę1950X¤Ī„¹„³„¢¤¬¤¤ģ¤¤¤ĖĢó2ĒܤĖ¤Ź¤Ć¤Ę¤¤¤ė¤³¤Č¤Ą”£„³„¢æōŹ¬¤ĪĄĒ½øž¾å¤¬ĘĄ¤é¤ģ¤Ę¤¤¤ė¤Ī¤Ļø«»ö¤Ē¤¢¤ė”£
””°ģŹż”¤7900X¤ČČꤣ¤ė¤Č”¤øÅŵÅŖ¤Źx87ĢæĪį¤ņ»Č¤¦FPU SinJulia¤Ē1950X¤¬Ģó127”ó¹ā¤¤¤Č¤¤¤¦°µÅŻÅŖ¤Ź„¹„³„¢¤ņĆ”¤½Š¤·¤Ę¤¤¤ė¤Ī¤ņ½ü¤±¤Š”¤¤Ŗ¤Ŗ¤ą¤Ķøß³Ń¤«¤¢¤Č°ģŹā¤Č¤¤¤¦“¶¤ø¤Ė¤Ź¤Ć¤Ę¤¤¤ė”£¶ńĀĪÅŖ¤Ź„Ń”¼„»„ó„Ę”¼„ø¤ņ¼Ø¤¹¤Č”¤FP32 Ray-Trace¤ĒĢó96”ó”¤FP64 Ray-Trace¤ĒĢó87”ó”¤FPU Julia¤ĒĢó99”ó”¤FPU Mandel¤ĒĢó98”ó”£AVX·Ļ¤ĪĢæĪį„»„ƄȤĒSIMD±é»»¤ņøņ¤Ø¤ė¤Č„Æ„ķ„Ć„Æ¤¢¤æ¤ź¤ĪĄĒ½¤ĒRyzen·Ļ¤¬¾ł¤ė¤ā¤Ī¤Ī”¤1950X¤Ļ„³„¢æō¤Ē¤½¤ģ¤ņÄ·¤ĶŹÖ¤·¤Ę”¤7900X¤Č¤Ŗ¤Ŗ¤ą¤ĶøŖ¤ņŹĀ¤Ł¤ė¤Č¤¤¤Ć¤æ·¹øž¤¬¤·¤Ć¤«¤ź¤Č±®¤Ø¤ė”£
 |
 |
Sandra 2017¤Ē¤ĻUMA¤ČNUMAĪ¾„ā”¼„ɤĪ°ć¤¤¤¬¾Æ¤·½Š¤Ę¤Æ¤ė
””Ā³¤¤¤Ę¤Ļ”¤SiSoftwareĄ½¤Ī„·„¹„Ę„ąø”ŗŗ”õ„Ł„ó„Į„Ž”¼„Æ„Ä”¼„ė¤Ē¤¢¤ė”ÖSandra”×”ŹVersion 2017.06.24.27”¤°Ź²¼ Sandra 2017”Ė¤Ī·ė²Ģ¤āø«¤Ę¤Ŗ¤¤æ¤¤”£¤Ž¤ŗ¤ĻAIDA64¤Čʱ¤ø¤č¤¦¤Ė”¤¾ļĶѓĶ¤Ė¤Ŗ¤±¤ė·ė²Ģ¤«¤é¤Ž¤Č¤į¤Ę¤¤¤³¤¦”£
””„°„é„Õ11¤ĻCPU¤Ī±é»»ĄĒ½¤ņø«¤ė”ÖProcessor Arithmetic”פĪĮķ¹ē„¹„³„¢”ÖAggregate Native Performance”פĄ”£
””1950X¤Č1920X¤Ē”¤UMA¤ČNUMAĪ¾„ā”¼„ɤĪ„¹„³„¢ŗ¹¤Ļ¤Ū¤Ü¤Ź¤¤¤ČøĄ¤Ć¤Ę¤¤¤¤”£ĀŠ7900X¤Ą¤Č1950X¤ĻĢó32”ó”¤1920X¤Ļ3”Į4”óÄųÅŁ¹ā¤¤„¹„³„¢¤Ē”¤¤³¤Ī·ė²Ģ¤«¤é¤Ļ”Ö„³„¢¤¢¤æ¤ź¤ĪĄĒ½¤ĒRyzen Threadripper¤Ļ7900X¤ĖµŚ¤Š¤Ź¤¤¤¬”¤„³„¢æō¤Ē²”¤·ĄŚ¤Ć¤æ”פ³¤Č¤ņ³ĪĒ§¤Ē¤¤ė”£
””¤Ž¤æ”¤1950X¤ĪGame Mode¤Ė¤Ŗ¤±¤ė„¹„³„¢¤Ļ1800X¤ĪĢó99”ó¤Ē”¤¤Ū¤Üʱ¤ø¤Č¤¤¤¦·ė²Ģ¤Ė¤Ź¤Ć¤Ę¤¤¤ė”£Game Mode¤ĖĄŚ¤ź“¹¤Ø”¤8„³„¢16„¹„ģ„Ć„ÉĀŠ±ž¤Č¤Ź¤Ć¤æ1950X¤Ī±é»»ĄĒ½¤Ļ1800X¤Č¤Ū¤Ü°ģĆפ¹¤ė¤Č¤¤¤¦”¤AIDA64¤Čʱ¤ø·¹øž¤Ą”£
 |
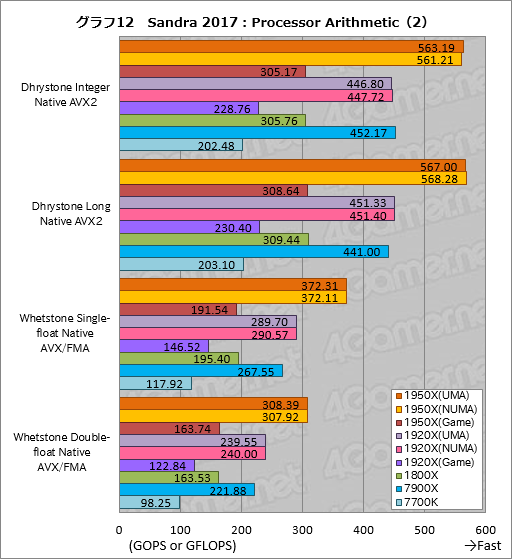
””Processor Arithmetic¤ĪøÄŹĢ„¹„³„¢¤ņ¤Ž¤Č¤į¤æ¤Ī¤¬„°„é„Õ12¤Č¤Ź¤ė”£Ryzen Threadripper¤Ī2Ą½ÉŹ¤ĒUMA¤ČNUMA¤ĪĪ¾„ā”¼„ɤĖ°ć¤¤¤¬ø«¤é¤ģ¤Ź¤¤¤Ī¤ĻĮķ¹ē„¹„³„¢¤Čʱ¤ø”£1950X¤ĪGame Mode¤Ė¤Ŗ¤±¤ė„¹„³„¢¤¬1800X¤Č¤Ŗ¤Ŗ¤ą¤Ķ°ģĆפ¹¤ė¤Ī¤āʱ¤ø¤Ą”£
””ĀŠ7900X¤Ī¶ńĀĪÅŖ¤Ź„¹„³„¢¤ņø«¤Ę¤ß¤ė¤Č”¤1950X¤Ļ”ÖDhrystone Integer Native AVX2”פĒĢó25”󔤔ÖDhrystone Long Native AVX2”פĒĢó29”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤Ę¤¤¤ė¤Ī¤ĖĀŠ¤·¤Ę”¤”ÖWhetstone Single-float Native AVX/FMA”פȔÖWhetstone Double-float Native AVX/FMA”פĒ¤ĻĢó39”ó¹ā¤¤„¹„³„¢¤Ą”£
””1920X¤āʱ¤ø·¹øž¤Ē”¤Dhrystone Integer Native AVX2¤Ą¤ČĢó1”óÄ椤„¹„³„¢”¤Dhrystone Long Native AVX2¤Ē¤ĻĢó2”ó¹ā¤¤„¹„³„¢¤Ī¤Č¤³¤ķ”¤Whetstone Single-float Native AVX/FMA¤Ē¤ĻĢó9”ó”¤Whetstone Double-float Native AVX/FMA¤Ē¤ĻĢó8”󔤤½¤ģ¤¾¤ģ¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤Ę¤¤¤ė”£
””AVX¤äFMA¤¬ŗ®¤¶¤ė¤ČRyzen¤ĒŹ¬¤¬°¤¤¤Č¤¤¤¦·¹øž¤¬AIDA64¤Ē¤Ļø«¤é¤ģ¤æ¤ļ¤±¤Ą¤¬”¤¾Æ¤Ź¤Æ¤Č¤āSandra 2017¤ĪProcessor Arithmetic¤Ą¤Č”¤¤½¤¦¤¤¤¦·ė²Ģ¤Ļ½Š¤Ę¤Ŗ¤é¤ŗ”¤Ą°æō±é»»„Ę„¹„ȤĒ¤¢¤ėDhrystone¤č¤ź”¤ÉāĘ°¾®æōÅĄ±é»»„Ę„¹„ȤĒ¤¢¤ėWhetstone¤Ī¤Ū¤¦¤¬„¹„³„¢¤Ļ¹ā¤¤”£ĶפĻ„Ę„¹„ȤĖ¤č¤ė¤Č¤¤¤¦¤³¤Č¤Ą¤ķ¤¦¤«”£
 |
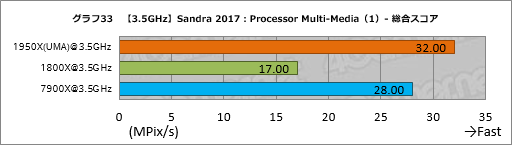
””Ā³¤¤¤Ę¤Ļ„Ž„ė„Į„į„Ē„£„¢½čĶżĄĒ½¤ņø«¤ė”ÖProcessor Multi-Media”פĄ”£Processor Multi-Media¤Ē¤ĻÉ®¼Ō¤Ī„ß„¹¤Ė¤č¤ź”¤1920X¤ĪGame Mode»ž¤Ė¤Ŗ¤±¤ė„Ē”¼„æ¤ņ¾å½ń¤¤·¤Ę¼ŗ¤Ć¤Ę¤·¤Ž¤Ć¤æ”£¤½¤ģ¤ę¤Ø”¤Åö³ŗ¾ņ·ļ¤Ī„¹„³„¢¤¬N/A¤Č¤Ź¤ėÅĄ¤Ļ¤ŖĻĶ¤Ó¤·¤Ä¤Ä¤ŖĆĒ¤ź¤·¤Ę¤Ŗ¤¤æ¤¤”£
””¤µ¤Ę”¤Sandra 2017¤ĪProcessor Multi-Media¤Ą¤¬”¤¤³¤Ī„Ę„¹„ȤĒ¤Ļ”¤„Ē„¹„Æ„Č„Ć„×PCøž¤±¤Č¤·¤ĘCore X„ׄķ„»„Ć„µ¤Ē½é¤į¤Ę„µ„Ż”¼„Ȥ¬»Ļ¤Ž¤Ć¤æ³ČÄ„ĢæĪį”ÖAVX-512”פ¬ĀæĶѤµ¤ģ¤Ę¤¤¤ė”£
””7900X¤Ī„ģ„ӄ唼¤Ē¤āæؤģ¤æ¤č¤¦¤Ė”¤AVX-512¤ņ»Č¤¦°ģČĢ„ę”¼„¶”¼øž¤±„¢„ׄź„±”¼„·„ē„ó¤Ļ¤Ū¤Č¤ó¤ÉĀøŗߤ·¤Ź¤¤”£Įķ¹ē„¹„³„¢¤Ė¤¢¤æ¤ė”ÖAggregate Multi-Media Native Performance”פņø«¤ė„°„é„Õ13¤Ą¤Č”¤AVX-512¤Ī¤Ŗ¤«¤²¤Ē7900X¤¬¤Ū¤«¤ņ°µÅŻ¤·¤Ę¤·¤Ž¤¦¤¬”¤¤³¤³¤Ē7900X¤ČČę³Ó¤¹¤ė¤³¤Č¤Ė¤¢¤Ž¤ź°ÕĢ£¤Ļ¤Ź¤¤¤³¤Č¤ņ”¤¤Ž¤ŗ¤Ļ²”¤µ¤Ø¤Ę¤ā¤é¤Ø¤ģ¤Š¤Č»×¤¦”£
””¤Č¤¤¤¦¤ļ¤±¤Ē1950X¤Č1920X¤Ą¤¬”¤UMA¤ČNUMA¤ĪĪ¾„ā”¼„ɤĒ„¹„³„¢ŗ¹¤Ļ¤Ū¤Č¤ó¤É¤Ź¤Æ”¤¤Ū¤Ü°ģĆפ·¤Ę¤¤¤ė¤Č½Ņ¤Ł¤Ę¤¤¤¤”£1800X¤Č¤ĪČę³Ó¤Ė¤Ŗ¤¤¤Ę”¤1950X¤Ī„¹„³„¢¤ĻĢó83”ó”¤1920X¤Ī„¹„³„¢¤Ļ41”Į42”óÄųÅŁ¤½¤ģ¤¾¤ģ¹ā¤¤¤Ī¤Ē”¤„³„¢æō¤Ī°ć¤¤¤Ė±ž¤ø¤æ„¹„³„¢¤¬¤Ŗ¤Ŗ¤č¤½½Š¤Ę¤¤¤ė¤Č¤āøĄ¤Ø¤ė¤Ą¤ķ¤¦”£
””¤ā¤Į¤ķ¤ó”¤4„³„¢8„¹„ģ„Ć„ÉĀŠ±ž¤Ī7700K¤ņĮź¼ź¤Ė¤·¤Ź¤¤„¹„³„¢¤āĘĄ¤é¤ģ¤Ę¤¤¤ė¤Ī¤Ē”¤AVX-512¤Č¤¤¤¦”¤ø½»žÅĄ¤Ē¤ĻĢ“ŹŖøģ¤Ē¤·¤«¤Ź¤¤ĢæĪį„»„ƄȤĪ»ÅĶĶ¤ņ½ü¤±¤Š”¤„Ž„ė„Į„į„Ē„£„¢·Ļ¤Ī½čĶż¤Ē¤āRyzen Threadripper¤Ē¹ā¤¤ĄĒ½¤¬ĘĄ¤é¤ģ¤ė“üĀŌ¤¬»ż¤Ę¤ė¤³¤Č¤Ė¤Ź¤ė”£
””¤Ź¤Ŗ”¤1950X¤ĪGame Mode¤Ė¤Ŗ¤±¤ė„¹„³„¢¤Ļ”¤1800X¤Č¤³¤³¤Ē¤ā¤Ū¤Ü°ģĆפ·¤æ”£
 |
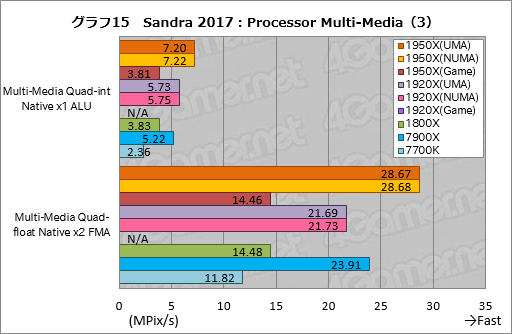
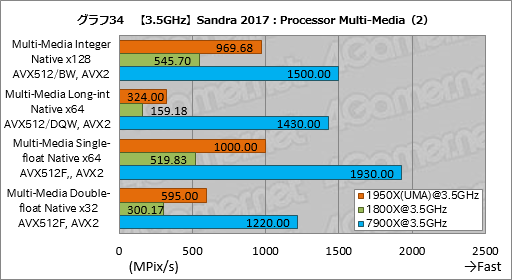
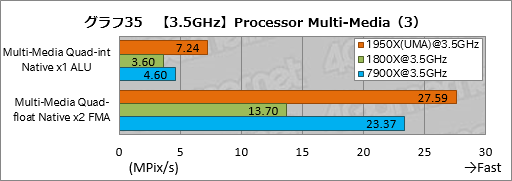
””Processor Multi-Media¤ĪøÄŹĢ„¹„³„¢¤Ļ„°„é„Õ14”¤15¤Ī¤Č¤Ŗ¤ź¤Ą”£Įķ¹ē„¹„³„¢¤ČʱĶĶ”¤1950X¤Č1920X¤Ī¤¤¤ŗ¤ģ¤ā”¤UMA¤ČNUMA¤Ī„¹„³„¢ŗ¹¤Ļøķŗ¹ČĻ°Ļ¤Č¤Ź¤Ć¤Ę¤¤¤ė”£¤Ž¤æ”¤1950X¤ĪGame Mode¤Č1800X¤Ī„¹„³„¢ŗ¹¤ā¤Ū¤Ü¤Ź¤¤”£
””ŗŁ¤«¤Æ„Į„§„Ć„Æ¤¹¤ė¤Č”¤Ć±ĄŗÅŁÉāĘ°¾®æōÅĄ±é»»¤ņ»Č¤Ć¤Ę²čĮü¤Ī„Ō„Æ„»„ė½čĶż¤ņ¹Ō¤¦”ÖMulti-Media Single-float Native x64 AVX512F, AVX2”פĪ¤ß”¤1950X¤¬1800XČę¤ĒĢó98”ó¤Č”¤„®„ć„Ƅפ¬¼ć“³Āē¤¤Æ¤Ź¤Ć¤Ę¤¤¤ė¤ā¤Ī¤Ī”¤„Ö„ģ¤ĪČĻ°Ļ¤Ą¤ČÉ®¼Ō¤Ļ¹Ķ¤Ø¤Ę¤¤¤ė”£
””øÄŹĢ„¹„³„¢¤Ē¶½Ģ£æ¼¤¤¤Ī¤Ļ”¤x86ĢæĪį¤Ī¤ß¤ņ»Č¤¦”ÖMulti-Media Quad-int Native x1 ALU”פĪ·ė²Ģ¤Ą”£AIDA64¤Ą¤Č”¤øÅŵÅŖ¤Źx86ĢæĪį¤ĒRyzen·Ļ¤¬°µÅŻÅŖ¤ŹĶ„°ĢĄ¤ņø«¤»¤Ę¤¤¤æ¤¬”¤¤³¤³¤Ē¤Ļ7900X¤ä7700K¤Č¤Ī“Ö¤Ė¤¢¤ė„³„¢æō¤Ī°ć¤¤¤ņʧ¤Ž¤Ø¤ė¤Ė”¤Ryzen Threadripper¤ĪĶ„°ĢĄ¤Ļ¤½¤ģ¤Ū¤ÉĄø¤ø¤Ę¤¤¤Ź¤¤”£¤ä¤Ļ¤ź¤³¤³¤Ļ„³”¼„ɤĪĘāĶʤĖ¤č¤ė¤Č¤¤¤¦¤³¤Č¤Ź¤Ī¤Ą¤ķ¤¦”£
 |
 |
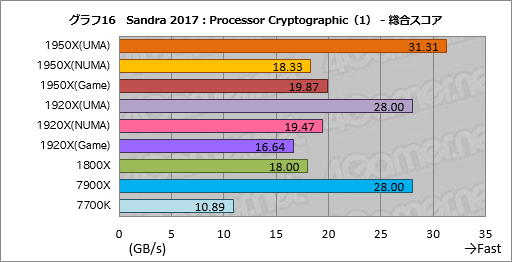
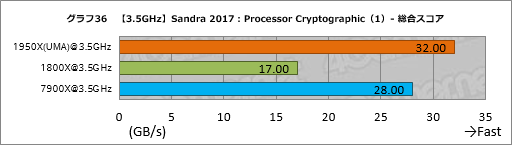
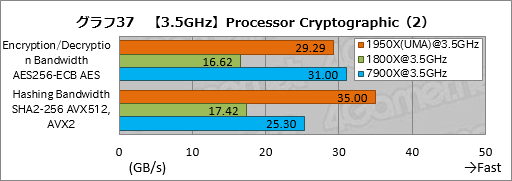
””CPU¤ņĶѤ¤¤æ°Å¹ę²½¤ĪĄĒ½¤ņÄ“¤Ł¤ė”ÖProcessor Cryptographic”פĪĮķ¹ē„¹„³„¢”ÖCryptographic Bandwidth”פņ„°„é„Õ16¤Ė¤Ž¤Č¤į¤æ”£
””¤³¤³¤ĒĆķĢܤ·¤æ¤¤¤Ī¤Ļ”¤Ryzen Threadripper¤Ė¤Ŗ¤¤¤Ę”¤NUMA„ā”¼„ɤČČꤣ”¤UMA„ā”¼„ɤ¬ĢĄ¤é¤«¤Ė¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤Ę¤¤¤ė¤Č¤³¤ķ¤Ē¤¢¤ė”£1950X¤ĻĢó71”ó”¤1920X¤Ē¤āĢó44”ó”¤UMA„ā”¼„ɤĪ¤Ū¤¦¤¬¹ā¤¤”£
””Sandra 2017¤ĪProcessor Cryptographic¤Ė¤Ļ”¤°Å¹ę²½¤Ī„¢„Æ„»„é„ģ”¼„·„ē„ó¤ņĶѤ¤¤ė„Ę„¹„Ȥ¬“Ž¤Ž¤ģ¤Ę¤¤¤ė¤æ¤į”¤„į„ā„ź„Š„¹ĀÓ°čÉż¤¬„¹„³„¢¤ņŗø±¦¤·¤ä¤¹¤Æ¤Ź¤ė”£ĮĒľ¤Ė¹Ķ¤Ø¤ģ¤Š”¤UMA„ā”¼„ɤĪ»ż¤Ä„į„ā„ź„¢„Æ„»„¹ĀÓ°čÉż¤Ī¹¤µ¤¬½Š¤æ¤Č¹Ķ¤Ø¤é¤ģ¤ė¤¬”¤øÄŹĢ„¹„³„¢¤ņ»²¾Č¤·¤ĘČ½ĆĒ¤¹¤Ł¤¤Ą¤ķ¤¦”£¤Ž¤æ”¤NUMA„ā”¼„ɤĒ¤Ļ1950X¤¬1920X¤č¤źÄ椤„¹„³„¢¤ņ½Š¤·¤Ę¤¤¤ė¤¬”¤¤½¤ĪĶżĶ³¤āøÄŹĢ„¹„³„¢¤ņø«¤ĘČ½ĆĒ¤·¤æ¤Ū¤¦¤¬¤č¤µ¤½¤¦¤Ą”£
””7900X¤Č¤ĪČę³Ó¤Ą¤Č”¤1950X¤ĪUMA„ā”¼„ɤĻĢó12”ó¹ā¤¤„¹„³„¢”¤1920X¤ĪUMA„ā”¼„ɤĻ¤Ō¤Ć¤æ¤źĘ±¤ø„¹„³„¢¤ņ¤½¤ģ¤¾¤ģ¼Ø¤·¤æ”£¤¤¤ŗ¤ģ¤ā¤Ž¤ŗ¤Ž¤ŗ¤ČøĄ¤Ć¤æ¤Č¤³¤ķ¤«”£
””¤Į¤Ź¤ß¤Ė”¤1950X¤ĪGame Mode¤Ļ1800X¤ČČꤣ¤ĘĢó10”ó¹ā¤¤¤¬”¤¤³¤ģ¤Ļŗ£²ó¤Ī„Ę„¹„ȤĖ¤Ŗ¤¤¤Ę”¤Game Mode¤Ė¤Ŗ¤±¤ėUMA„ā”¼„ɤ¬Ķøś¤Ė¤Ź¤Ć¤Ę¤¤¤ė¤æ¤į¤Ą¤Č»×¤ļ¤ģ¤ė”£
 |
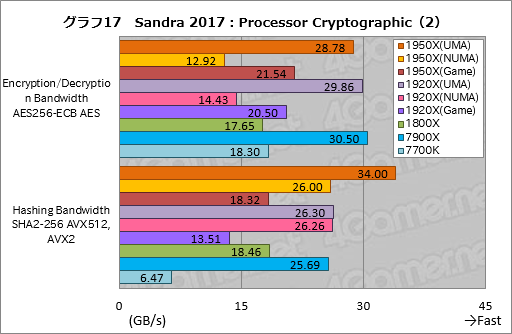
””Processor Cryptographic¤ĪøÄŹĢ„¹„³„¢¤¬„°„é„Õ17¤Ē”¤UMA¤ČNUMAĪ¾„ā”¼„ɤĪ„¹„³„¢ŗ¹¤¬¤č¤źø²Ćų¤Ė½Š¤Ę¤¤¤ė¤Ī¤Ļ„¢„Æ„»„é„ģ”¼„·„ē„ó¤ņ»Č¤¦”ÖEncryption/Decryption Bandwidth AES256-ECB AES”פĪ¤Ū¤¦¤Ą¤Č¤¤¤¦¤³¤Č¤¬¤č¤ÆŹ¬¤«¤ė”£1950X¤Ą¤Č”¤NUMA„ā”¼„ɤĖĀŠ¤·¤ĘUMA„ā”¼„ɤĪ„¹„³„¢¤ĻĢó123”ó”¤1920X¤Ē¤āĢó107”ó¹ā¤Æ”¤¤¤¤ŗ¤ģ¤ā2ĒÜ°Ź¾å¤Ą”£
””¤Ž¤æ”„”ÖEncryption/Decryption Bandwidth AES256-ECB AES”פĻUMA”¤NUMA¤ĪĪ¾„ā”¼„ɤĒ1950X¤č¤ź¤ā¤ą¤·¤ķ1920X¤Ī¤Ū¤¦¤¬¤ä¤ä¹ā¤¤„¹„³„¢¤Ė¤Ź¤Ć¤Ę¤¤¤ė”£„¢„Æ„»„é„ģ”¼„·„ē„ó¤ņ¹Ō¤¦AESĢæĪį¤ņ»Č¤¦„Ę„¹„ȤŹ¤Ī¤Ē”¤AES¤Ī„¢„Æ„»„é„ģ”¼„·„ē„ó¤Ē¤Ļ„³„¢æō¤Ė±ž¤ø¤æĄĒ½øž¾å¤¬ĘĄ¤é¤ģ¤Ź¤¤”¤¤Č¤¤¤¦²ÄĒ½Ą¤¬¤¢¤ė”£
””„¢„Æ„»„é„ģ”¼„·„ē„ó¤ņ»ČĶѤ·¤Ź¤¤”ÖHashing Bandwidth SHA2-256 AVX512, AVX2”פĖĢܤņ°Ü¤¹¤Č”¤NUMA„ā”¼„ɤĒ¤Ļ1950X¤Č1920X¤Ī„¹„³„¢¤¬¤Ū¤ÜŹŃ¤ļ¤é¤Ź¤¤¤Ī¤ĖĀŠ¤·”¤UMA„ā”¼„ɤĄ¤Č1920X¤ĖĀŠ¤·¤Ę1950X¤ĒĢó29”ó¹ā¤¤„¹„³„¢¤¬ĘĄ¤é¤ģ¤Ę¤¤¤ė”£NUMA„ā”¼„ɤĒ„³„¢æō¤Ė±ž¤ø¤æĄĒ½¤¬ĘĄ¤é¤ģ¤Ź¤¤ĶżĶ³¤ĻæäĀ¬¤Ī°č¤ņ½Š¤Ź¤¤¤¬”¤NUMA„Ī”¼„ɤĖ„¹„ģ„Ƅɤņ½øĆꤵ¤»¤ė“Ų·ø¤ĒĶ·¤ó¤Ē¤¤¤ėCPU„³„¢¤¬¤Ē¤¤Ę¤¤¤ė¤Ī¤«¤ā¤·¤ģ¤Ź¤¤”£
””°ģŹż”¤ĀŠ7900X¤Ą¤ČRyzen·Ļ¤ĻEncryption/Decryption Bandwidth AES256-ECB AES¤¬¤¤¤Ž1¤Ä¤Ē”¤„¢„Æ„»„é„ģ”¼„·„ē„ó¤ņ»ČĶѤ·¤Ź¤¤”ÖHashing Bandwidth SHA2-256 AVX512, AVX2”פĪ¤Ū¤¦¤¬Ą®ĄÓ¤¬¤¤¤¤”£
””AESĢæĪį¤Ē¹ā¤¤ĄĒ½¤ņ»ż¤Ä¤č¤¦¤Ą¤Č¤¤¤¦AIDA64¤Ī”ÖCPU AES”פĪ·ė²Ģ¤ČĄµµÕ¤Ą¤¬”¤¤½¤ĪĶżĶ³¤ĻĄµÄ¾”¤ÉŌĢĄ¤Ą”£
 |
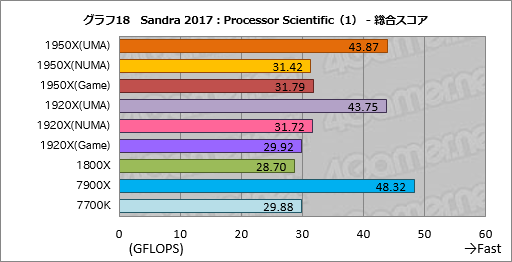
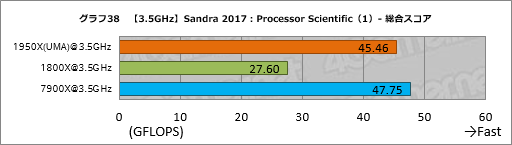
””„°„é„Õ18¤Ļ”¤²Ź³Ųµ»½Ń·×»»¤ņ¹Ō¤¦”ÖProcessor Scientific”פĪĮķ¹ē„¹„³„¢¤Ė¤¢¤æ¤ė”ÖAggregate Scientific Performance”פņ¤Ž¤Č¤į¤æ¤ā¤Ī¤Ą”£¤³¤³¤Ē¤ā”¤Ryzen Threadripper¤Ē¤ĻUMA„ā”¼„ɤĪ„¹„³„¢¤¬¤¤¤¤”£ĀŠNUMA„ā”¼„ɤĒ1950X¤ĻĢó40”ó”¤1920X¤ĻĢó38”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤æ”£
””1950X¤Č1920X¤Ī„¹„³„¢¤¬¤Ū¤Č¤ó¤ÉŹŃ¤ļ¤é¤Ź¤¤¤Ī¤āĘĆħ¤Ą¤¬”¤¤½¤ĪĶżĶ³¤ĻøÄŹĢ„¹„³„¢¤ņø«¤ĘČ½ĆĒ¤¹¤Ł¤¤Ą¤ķ¤¦”£
””ĀŠ7900X¤ĒRyzen Threadripper¤¬æ¶¤ė¤ļ¤Ź¤¤¤Ī¤āĘĆħ¤Ē”¤UMA„ā”¼„ɤĒø«¤Ę¤ā1950X”¤1920X¤Č¤āĢó91”ó¤Č¤¤¤¦„¹„³„¢¤Ė¤Ź¤Ć¤Ę¤¤¤ė”£
 |
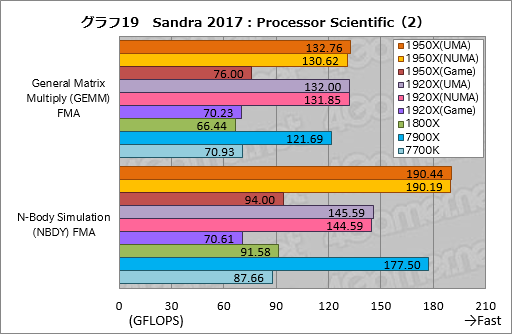
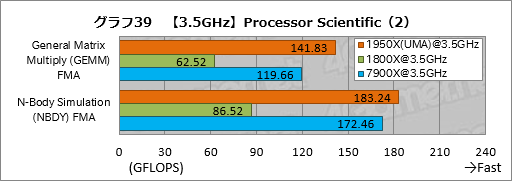
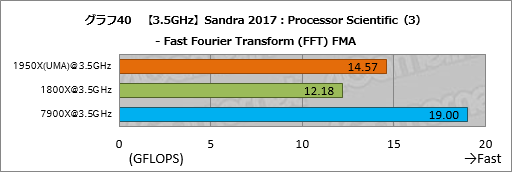
””¤½¤Īø¶°ų¤ĻøÄŹĢ¤Ī„¹„³„¢¤ņø«¤ė¤Č¤Ļ¤Ć¤¤ź¤¹¤ė”£„°„é„Õ19”¤20¤Ė¼Ø¤·¤æ¤Ī¤¬¤½¤ģ¤Ą¤¬”¤„°„é„Õ20¤Ī”ÖFast Fourier Transform (FFT) FMA”×”Ź°Ź²¼”¤FFT”Ė¤Ė¤Ŗ¤±¤ė„Ę„¹„Č·ė²Ģ¤Ļ¤«¤Ź¤ź¶ĖĆ¼¤Ē”¤¤³¤ģ¤¬Įķ¹ē„¹„³„¢¤ņĀē¤¤Æŗø±¦¤·¤æ¤ČøĄ¤Ø¤½¤¦¤Ą”£
””FFT¤Ē¤Ļ”¤¤Ž¤ŗUMA„ā”¼„ɤČNUMA„ā”¼„ɤĪ°ć¤¤¤¬”ÖGeneral Matrix Multiply (GEMM) FMA”פä”ÖN-Body Simulation (NBDY) FMA”פĖČꤣ¤ė¤ČĮźÅö¤ĖĀē¤¤¤”£ĀŠNUMA„ā”¼„ɤĒ”¤UMA„ā”¼„ɤĪ„¹„³„¢¤Ļ1950X¤¬Ģó92”ó”¤1920X¤¬Ģó90”󤽤ģ¤¾¤ģ¹ā¤¤¤Č¤¤¤Ć¤æ¶ń¹ē¤Ē¤¢¤ė”£
””¤Ž¤æ”¤1950X¤ĪUMA„ā”¼„ɤČ1920X¤ĪUMA„ā”¼„ɤĪ„¹„³„¢ŗ¹¤¬¤Ū¤Č¤ó¤É¤Ź¤¤¤³¤Č¤«¤é”¤CPU„³„¢æō¤Ė±ž¤ø¤æĄĒ½¤Īøž¾å¤¬ĘĄ¤é¤ģ¤Ę¤¤¤Ź¤¤¤³¤Č¤āø«¤Ę¤Č¤ģ¤ė”£
””¤Į¤Ź¤ß¤Ė7900X¤Č¤Ī„¹„³„¢ŗ¹¤ĻĀē¤¤Æ”¤UMA„ā”¼„ɤĖ¤Ŗ¤±¤ė1950X¤Ī„¹„³„¢¤Ļ7900XČę¤ĒĢó76”ó”¤1920X¤Ē¤ĻĢó66”ó¤Ė¤Ź¤Ć¤Ę¤·¤Ž¤Ć¤Ę¤¤¤ė”£
 |
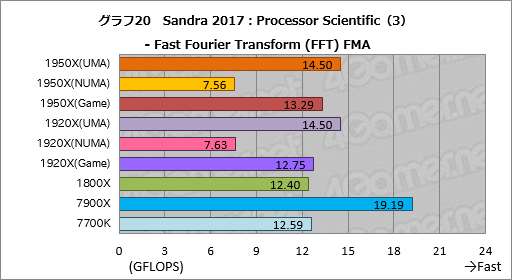 |
””²æøĪ¤³¤¦¤Ź¤ė¤«¤Ą¤¬”¤FFT¤Ī°ģČĢÅŖ¤Ź„¢„ė„“„ź„ŗ„ą¤Ą¤Čʱ¤ø„Ē”¼„æ¤ĖÉŃ²ó¤Ī„¢„Æ„»„¹¤¬ČÆĄø¤¹¤ė”£¤½¤Ī¤æ¤į”¤”Ö„„ć„Ć„·„å¤ä„į„ā„ź¤ĪĀÓ°čÉż¤¬ŗĒ½ŖÅŖ¤ŹĄĒ½¤ņŗø±¦¤¹¤ėÅŁ¹ē¤¤”פ¬Āē¤¤¤”£
””NUMA„ā”¼„ɤĄ¤ČFFT¤Ī„¹„ģ„ƄɤĻ¤Ŗ¤½¤é¤ÆĘĆÄź¤ĪNUMA„Ī”¼„ɤĖ³ä¤źÅö¤Ę¤é¤ģ¤ė¤æ¤į”¤CPU¤¬Č¾Ź¬Ķ·¤Ö·Į¤Ė¤Ź¤ė¤Ą¤ķ¤¦”£¤Č¤Ź¤ģ¤ŠUMA¤¬¶Ė¤į¤Ę¹ā¤¤„¹„³„¢¤ņ»Ä¤·¤æ¤³¤Č¤¬Ē¼ĘĄ¤Ē¤¤ė”£
””7900X¤Č¤Ī„¹„³„¢ŗ¹¤¬Āē¤¤¤¤Ī¤Ļ”¤Ryzen Threadripperd¤Ēʱ°ģ„Ē”¼„æ¤Ų¤Ī„¢„Æ„»„¹„³„¹„Ȥ¬Inifinity Fabric¤Ī±Ę¶Į¤ĒĀē¤¤¤¤³¤Č¤¬±Ę¶Į¤·¤æ¤«”¤¤¢¤ė¤¤¤Ļ„„ć„Ć„·„å¤ĪĄĒ½ŗ¹¤¬½Š¤æ¤Č¤¤¤Ć¤æ¤Č¤³¤ķ¤Ē¤Ļ¤Ź¤¤¤«¤ČæäĀ¬¤·¤Ę¤¤¤ė”£
””Ā³¤¤¤Ę¤Ļ”¤AVX¤äFMA¤ņ»ČĶѤ·¤æ2D²čĮü¤Ī½čĶżĄĒ½¤ņø«¤ė”ÖProcessor Image Processing”פĄ”£
””¤³¤³¤Ē¤āÉ®¼Ō¤Ī„ß„¹¤Ė¤č¤ź”¤1950X¤ĪNUMA„ā”¼„É»ž¤Ė¤Ŗ¤±¤ė„Ę„¹„Č„Ē”¼„æ¤ņ¾å½ń¤¤·¤Ę¼ŗ¤Ć¤æ¤æ¤į”¤Åö³ŗ„¹„³„¢¤ĻN/A¤Č¤Ź¤ė”£¤³¤ĪÅĄ¤Ļ¤ŖĻĶ¤Ó¤·¤æ¤¤”£
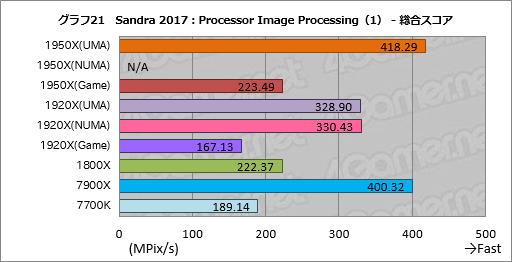
””¤µ¤Ę”¤„°„é„Õ21¤ĻĮķ¹ē„¹„³„¢¤Ė¤¢¤æ¤ė”ÖAggregate Image Processing Rate”פĄ¤¬”¤UMA¤ČNUMAĪ¾„ā”¼„ɤĪ°ć¤¤¤Ļ”¤1920X¤Ī„Ę„¹„Č·ė²Ģ¤ņø«¤ėøĀ¤ź¤Ū¤Č¤ó¤É¤Ź¤«¤Ć¤æ”£¤³¤³¤Ž¤Ē¤Ī„Ę„¹„Č·ė²Ģ¤«¤é¤¹¤ė¤Ė”¤1950X¤Ē¤āUMA¤ČNUMA¤ĒĀē¤¤Ź°ć¤¤¤ĻĄø¤ø¤Ę¤¤¤Ź¤¤¤Ļ¤ŗ¤Ē¤¢¤ė”£
””ĀŠ7900X¤Ą¤ČRyzen Threadripper¤Ļ涤ė¤ļ¤ŗ”¤1950X¤ĪUMA„ā”¼„ɤĻĢó104”ó”¤1920X¤ĪUMA„ā”¼„ɤĻĢó83”ó¤ĖĪ±¤Ž¤Ć¤Ę¤¤¤ė”£„³„¢æō¤ĪĪĻ¤Ē1950X¤¬¤č¤¦¤ä¤Æ7900X¤ĖøŖ¤ņŹĀ¤Ł¤Ę¤¤¤ė³Ź¹„¤Ą”£
 |
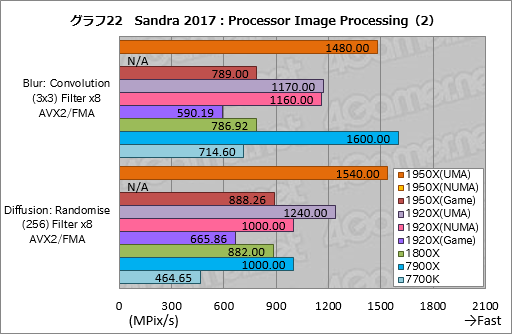
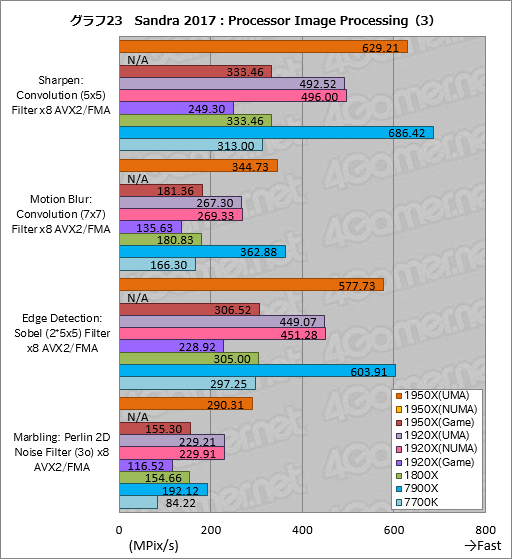
””Processor Image Processing¤Ļ3¤Ä¤Ī„°„é„Õ¤ĖŹ¬¤±¤æ¤¬”¤Į“ĀĪ¤Č¤·¤ĘRyzen Threadripper¤Ī„¹„³„¢¤Ļ”¤7900X¤ČČꤣ¤Ę½ŠĘž¤ź¤Ī·ć¤·¤¤¤ā¤Ī¤Č¤Ź¤Ć¤Ę¤¤¤ė”Ź„°„é„Õ22”¤23”¤24”Ė”£
””¶½Ģ£æ¼¤¤„¹„³„¢¤ņ½¦¤Ć¤Ę¤ß¤ė¤Č”¤¤Ž¤ŗ„°„é„Õ22¤Ė¤¢¤ė”ÖDiffusion: Randomise (256) Filter x8 AVX2/FMA”פĒ”¤1920X¤ĪUMA„ā”¼„ɤČNUMA„ā”¼„ɤņČę³Ó¤·¤æ¤Č¤”¤Į°¼Ō¤Ī¤Ū¤¦¤¬Ģó24”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤Ę¤¤¤ėÅĄ¤¬¶½Ģ£æ¼¤¤”£¤Ž¤æ”¤1920X¤ĪUMA„ā”¼„ɤĻ7900X¤ĖĀŠ¤·¤Ę¤āĢó24”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤¹”£1950X¤ĪUMA„ā”¼„ɤĖ»ź¤Ć¤Ę¤Ļ”¤ĀŠ7900X¤ĒĢó54”ó¹ā¤¤„¹„³„¢¤Ą”£
””¤Ź¤¼¤³¤¦¤Ź¤ė¤«¤ĻæäĀ¬¤Ī°č¤ņ½Š¤Ź¤¤¤¬”¤Diffusion: Randomise (256) Filter x8 AVX2/FMA¤Ļøķŗ¹³Č»¶¤ņ¹Ō¤¦„Ę„¹„ȤŹ¤Ī¤Ē”¤„Ž„ė„Į„¹„ģ„Ć„É²½¤¹¤ė¤ČŹ£æō¤Ī„¹„ģ„Ƅɤ¬Ę±°ģ¤Ī„Ē”¼„æ”Ź„į„ā„źĪĪ°č”Ė¤ņ»²¾Č¤¹¤ė¼ĀĮõ¤Ė¤Ź¤ė¤³¤Č¤¬¹Ķ¤Ø¤é¤ģ¤ė”£¤½¤Ī¾ģ¹ē”¤NUMA„ā”¼„ɤĄ¤Č„¹„ģ„ƄɤņNUMA„Ī”¼„ɤĖ³ä¤źæ¶¤ė¤æ¤į¤ĖCPU„³„¢¤¬Ķ·¤Ó¤ä¤¹¤Æ¤Ź¤ź”¤UMA„ā”¼„ÉĶĶų¤Ė¤Ź¤ė¤Ī¤«¤ā¤·¤ģ¤Ź¤¤”£
 |
 |
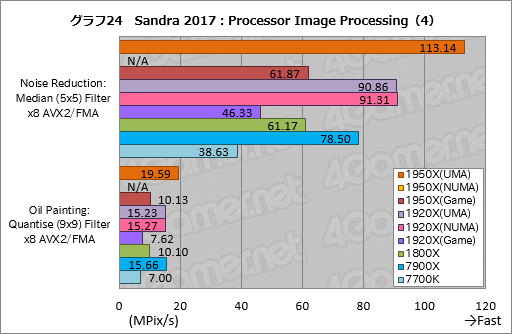 |
””¤½¤¦¤«¤Č»×¤Ø¤Š”¤„°„é„Õ22¤Ī”ÖBlur: Convolution (3x3) Filter x8 AVX2/FMA”פ䄰„é„Õ23¤Ī”ÖSharpen: Convolution (5x5) Filter x8 AVX2/FMA”פŹ¤É¤Ē¤Ļ”¤1950X¤ĪUMA„ā”¼„ɤĒ¤ā7900X¤ĖµŚ¤Š¤Ź¤¤·ė²Ģ¤Ė¤Ź¤Ć¤æ”£
””¤¤¤ŽĢ¾¤ņµó¤²¤æ2¤Ä¤Ī„Ę„¹„ȤĻ”¤Į°¼Ō¤¬¾ö¤ß¹ž¤ß¤ņ»Č¤Ć¤æ„Ü„«„·”¤øå¼Ō¤¬¾ö¤ß¹ž¤ß¤ņ»Č¤Ć¤æĄč±Ō²½¤Ē”¤ĮŠŹż¤Č¤āFMAĢæĪį¤¬¼ēĢņ¤Ė¤Ź¤ė½čĶż¤Ą”£Core X¤ČČꤣ¤Ę”¤Ryzen·Ļ¤ĻFMAĢæĪį¤ņ¶ģ¼ź¤Č¤·¤Ę¤¤¤ė²ÄĒ½Ą¤¬¹ā¤¤”£
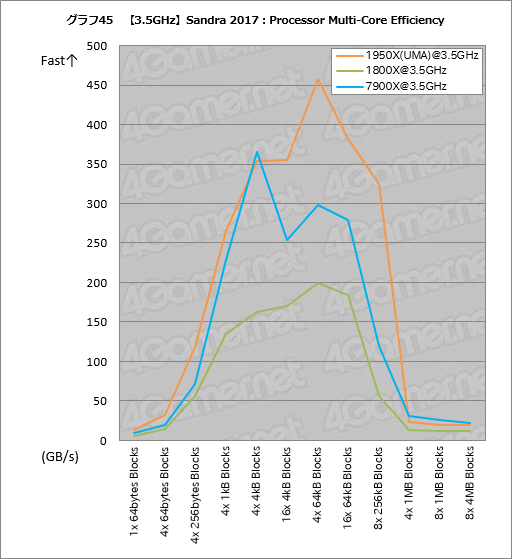
””„°„é„Õ25¤Ļ”¤CPU„³„¢“Ö¤Ī„Ē”¼„æžĮ÷¤ĪĀÓ°čÉż¤ņÄ“¤Ł¤ė”ÖProcessor Multi-Core Efficiency”פĪ·ė²Ģ¤Ą”£„°„é„Õ²čĮü¤ņ„Æ„ź„Ć„Æ¤¹¤ė¤Č”¤„¹„³„¢¤Ī¾ÜŗŁ¤ņ¤Ž¤Č¤į¤æɽ3¤ņɽ¼Ø¤¹¤ė¤č¤¦¤Ė¤·¤Ę¤¢¤ė¤Ī¤Ē”¤¤½¤Į¤é¤ā¤¼¤Ņ»²¹Ķ¤Ė¤·¤Ę¤Ū¤·¤¤”£
””„¹„³„¢¤ĒČó¾ļ¤ĖĢĢĒņ¤¤¤Ī¤Ļ”¤1950X¤¬7900X¤ĖĀŠ¤·”¤L2„„ć„Ć„·„å¤Ė¼ż¤Ž¤ėĶĘĪĢĀÓ¤Ē¤¢¤ė”Ö4x 64kB Blocks”פņĆęæ“¤Č¤·¤Ę”¤Āē¤¤Ź„³„¢“ÖĀÓ°čÉż¤ņ»ż¤Ć¤Ę¤¤¤ė¤Č¤¤¤¦ÅĄ¤Ą”£¶ńĀĪÅŖ¤ĖøĄ¤¦¤Č”¤”Ö4x 64kB Blocks”פĒ¤Ļ1950X¤¬7900XČę¤ĒĢó27”óĀē¤¤¤”£Infinity Fabric¤Ī»ż¤ÄĀÓ°čÉż¤¬¶Ė¤į¤ĘĀē¤¤¤¤³¤Č¤ņ¼Ø¤¹¤Č¤¤¤¦²ņ¼į¤Ē¤¤¤¤¤Ą¤ķ¤¦”£
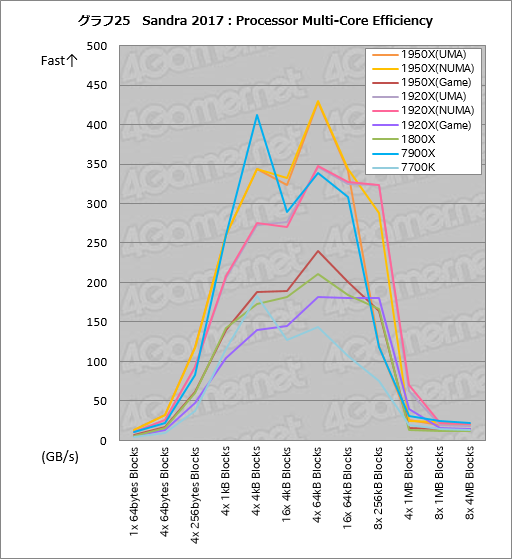 |
””1950X¤Ī„¹„³„¢¤ĖĆķĢܤ¹¤ė¤Č”¤NUMA„ā”¼„ɤĖČꤣ¤ĘUMA„ā”¼„ɤĒ¤Ļ”Ö8x 256kB Blocks”פĒ¤ä¤äĀē¤¤į¤ĪĶī¤Į¹ž¤ß¤¬ø«¤é¤ģ¤ė”£¤æ¤Ą”¤1920X¤Ē¤ĻʱĶĶ¤Ī·¹øž¤¬¤Ź¤¤¤Ī¤Ē”¤¤æ¤Ž¤æ¤Ž²æ¤«µÆ¤¤æ²ÄĒ½Ą¤ĻČŻÄź¤Ē¤¤Ź¤¤”£
””ÉÕ¤±²Ć¤Ø¤ė¤Č”¤1920X¤ĪNUMA„ā”¼„ɤĒ¤Ļ”Ö4x 1MB Blocks”פĪĀÓ°čÉż¤¬¤«¤Ź¤ź¹ā¤Æ½Š¤Ę¤¤¤ė¤Ī¤ĖĀŠ¤·¤Ę”¤UMA„ā”¼„ɤä1950X¤ĪUMA¤Ŗ¤č¤ÓNUMA„ā”¼„ɤĒ¤Ļ¤½¤¦¤Ē¤Ļ¤Ź¤¤¤Ź¤É”¤Ę±¤øRyzen Threadripper¤Ē¤ā„į„ā„ź„¢„Æ„»„¹„ā”¼„É¤äĄ½ÉŹ¤Ė¤č¤Ć¤Ę¤ä¤ä°Ū¤Ź¤ė·¹øž¤ņø«¤»¤ė¤Ī¤¬ĢĢĒņ¤¤”£²æøĪ¤³¤¦¤Ź¤ė¤Ī¤«¤Ļŗ£¤Ī¤Č¤³¤ķ¤č¤ÆŹ¬¤«¤é¤Ź¤¤¤¬”¤°ģ¶ŚĘģ¤Ē¤Ļ¤¤¤«¤Ź¤¤CPU¤Č¤¤¤¦°õ¾Ż¤Ļ¤¢¤ė”£
””„°„é„Õ26¤Ļ”¤„į„ā„ź„Š„¹ĀÓ°čÉż¤ņø«¤ė”ÖMemory Bandwidth”פĪĮķ¹ē„¹„³„¢¤ņ¤Ž¤Č¤į¤æ¤ā¤Ī¤Ą”£”ÖRyzen Threadripper¤ĻUMA„ā”¼„ɤ褟NUMA„ā”¼„ɤĪ¤Ū¤¦¤¬Ą®ĄÓ¤¬¤¤¤¤”פȤ¤¤¦ÅĄ¤Ē”¤AIDA64¤Ī„į„ā„ź„Ę„¹„ȤČʱ¤ø·¹øž¤Ė¤Ź¤Ć¤æ”£
””AIDA64¤Čʱ¤ø¤č¤¦¤Ė”¤Sandra 2017¤Ī„į„ā„ź„Ę„¹„Ȥā„Ž„ė„Į„¹„ģ„Ć„É²½¤µ¤ģ”¤NUMA„Ī”¼„ɤĖ„Ę„¹„Č„¹„ģ„Ƅɤ¬³ä¤źæ¶¤é¤ģ¤ė±Ę¶Į¤Ē¤Ļ¤Ź¤¤¤«¤ČæäĀ¬¤·¤Ę¤¤¤ė”£
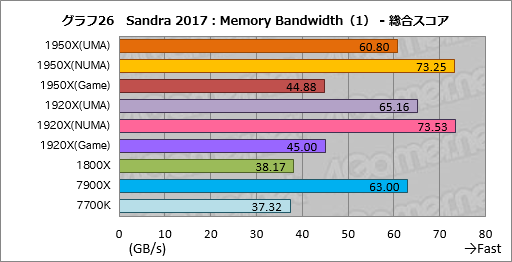 |
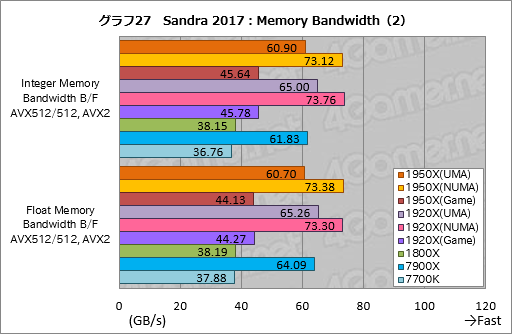
””¾å¤Ī„°„é„Õ26¤Ē1950X¤č¤ź1920X¤Ī¤Ū¤¦¤¬¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤Ę¤¤¤ė¤Ī¤Ėµ¤ÉÕ¤¤¤ææĶ¤ā¤¤¤ė¤Č»×¤¦¤¬”¤¤½¤Ī·¹øž¤ĻĄ°æō¤ņ»Č¤¦”ÖInteger Memory Bandwidth B/F AVX512/512, AVX2”פäÉāĘ°¾®æōÅĄæō¤ņ»Č¤¦”ÖFloat Memory Bandwidth B/F AVX512/512, AVX2”פĒ¤āŹŃ¤ļ¤é¤Ź¤¤”Ź„°„é„Õ27”Ė”£
””„į„ā„ź¼ž¤ź¤ĪĄßÄź¤Ļ1950X¤Č1920X¤Ē¤Č¤Æ¤ĖŹŃ¤Ø¤Ę¤¤¤Ź¤¤¤æ¤į”¤¤³¤Ī·ė²Ģ¤Ļ¤½¤ģ°Ź³°¤ĪĶ×°ų¤Ė¤č¤ė¤ā¤Ī¤Ą¤ķ¤¦”£„Ę„¹„Č„¹„ģ„Ƅɤ¬16„³„¢32„¹„ģ„ƄɤČĀē¤¤ÆĮż¤Ø¤Ę¤¤¤ė¤³¤Č¤¬ķÕķŌ¤ņ¾·¤¤¤æ¤Č¤«”¤¤½¤¦¤¤¤Ć¤æø¶°ų¤¬¤¢¤ė¤«¤ā¤·¤ģ¤Ź¤¤”£
””¤¤¤ŗ¤ģ¤Ė¤·¤Ę¤ā”¤1950X”¤1920X¤Č¤āĮķ¹ēÅŖ¤Ė¤Ļ7900X¤Ī„į„ā„ź„Š„¹ĀÓ°čÉż¤Ė°ś¤±¤ņ¼č¤é¤ŗ”¤NUMA„ā”¼„ɤĄ¤Č7900X¤ņĶ¤Ø¤ė„¹„³„¢¤¬ĘĄ¤é¤ģ¤æ”£¤æ¤Ą¤·”¤NUMA„ā”¼„ɤĒ¤Ļ”Ö2¤Ä¤ĪNUMA„Ī”¼„ɤĖ³ä¤źÅö¤Ę¤é¤ģ¤æ„Ę„¹„Č„¹„ģ„ƄɤĪ”¤Įķ¹ēÅŖ¤Ź„į„ā„ź„Š„¹ĀÓ°čÉż”פȤ¤¤¦°ÕĢ£¹ē¤¤¤Ė¤Ź¤ė¤Ī¤Ē”¤NUMA„Ī”¼„ɤ¬1¤Ä¤Ī¤ß¤Ē¤¢¤ė7900X¤Ī„į„ā„ź„Š„¹ĀÓ°čÉż¤Č¤ĻĄ¼Į¤¬°Ū¤Ź¤ė¤æ¤į”¤¤½¤ĪÅĄ¤Ė¤ĻĆķ°Õ¤¬É¬ĶפĄ¤ķ¤¦”£
 |
””„„ć„Ć„·„å¤Ŗ¤č¤Ó„į„ā„ź¤ĪĆŁ±ä¤ņ·×Ā¬¤¹¤ė”ÖCache & Memory Latency”פĪ·ė²Ģ¤¬„°„é„Õ28¤Ē¤¢¤ė”£¤³¤³¤Ē¤ā„°„é„Õ²čĮü¤ņ„Æ„ź„Ć„Æ¤¹¤ė¤Č”¤¾ÜŗŁ„Ē”¼„æ¤ņ¤Ž¤Č¤į¤æɽ4¤ņɽ¼Ø¤¹¤ė¤č¤¦¤Ė¤·¤Ę¤¢¤ė¤¬”¤ø«¤Ę¤ā¤é¤¦¤ČŹ¬¤«¤ė¤č¤¦¤Ė”¤Ryzen·Ļ¤Ē¤Ļ”ÖCPU Complex”×”Ź°Ź²¼”¤CCX”Ė¤¬»ż¤ÄĶĘĪĢ8MB¤Ī¶¦ĶL3„„ć„Ć„·„å°Ź¾å¤Ī„µ„¤„ŗ¤ĒĆŁ±ä¤¬Āē¤¤Æ¤Ź¤ė¤Ī¤¬ø«¤Ę¤Č¤ģ¤ė”£¤³¤ģ¤ĻRyzen Threadripper¤ČRyzen¤Ē¶¦ÄĢ¤Ī·¹øž¤Ą”£
””8MB¤Ź¤éRyzen Threadripper¤ĪL3¤ĪČĻ°Ļ¤Č»×¤¦¤«¤ā¤·¤ģ¤Ź¤¤¤¬”¤Ryzen Threadripper¤ĪL3¤Ļ2“š¤ĪCCX¤Ė8MB¤ŗ¤Ä¤Ē¹ē·×16MB¤Ą”£„Ę„¹„Č„Ö„ķ„Ć„Æ„µ„¤„ŗ¤¬8MB¤Ą¤Č”¤CCX¤¢¤æ¤ź8MB¤Č¤Ź¤ėL3„„ć„Ć„·„å¤Ī¹¹æ·¤¬ÉŃČĖ¤ĖČÆĄø¤¹¤ė¤æ¤į”¤„Ŗ”¼„Š”¼„Ų„Ƅɤ¬Āē¤¤Æ¤Ź¤ź”¤ĆŁ±ä¤Č¤Ź¤Ć¤Ęø½¤ģ¤ė¤ļ¤±¤Ē¤¢¤ė”£
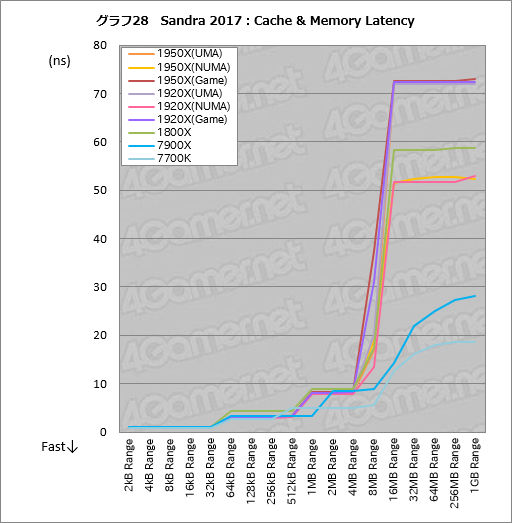 |
””UMA¤ČNUMAĪ¾„ā”¼„ɤĪ°ć¤¤¤Ļ”¤2“š¤¢¤ė„·„ź„³„ó„Ą„¤”Ź”įCCX
””¤Į¤Ź¤ß¤ĖNUMA„ā”¼„ɤĄ¤ČUMA„ā”¼„ɤĖĀŠ¤·¤ĘĢó20nsĪɹ„¤Ą¤Ć¤æ”£¤³¤³¤ĻAMD¤Ī„¢„Ź„¦„󄹤ɤŖ¤ź¤Č¤¤¤Ć¤æ¤Č¤³¤ķ¤Ē¤¢¤ė”£
””¤Ź¤Ŗ”¤”Ö32MB Range”×°Ź¾å¤Ī„µ„¤„ŗ¤Ē1950X¤Č1920X¤ĪNUMA„ā”¼„ɤĖ¤Ŗ¤±¤ėĆŁ±ä¾õ¶·¤¬1800X¤ĖĀŠ¤·¤ĘÄć¤Æ¤Ź¤Ć¤Ę¤¤¤ė¤Ī¤Ļ”¤„ģ„ӄ唼Į°ŹŌ¤Ē¤ŖĆĒ¤ź¤·¤æ¤Č¤Ŗ¤ź”¤„į„ā„ź„ā„ø„唼„ė¤Ī»ÅĶĶ¤¬°Ū¤Ź¤ė¤æ¤į¤Ē¤¢¤ė”£
””32MB Range°Ź¾å¤Ī„µ„¤„ŗ¤Ē¤ą¤·¤ķĆķĢܤ·¤æ¤¤¤Ī¤Ļ”¤IntelĄŖ¤ĖĀŠ¤·AMDĄŖ¤ĪĆŁ±ä¤¬Āē¤¤¤¤³¤Č¤Č”¤¤µ¤é¤Ė14-14-14-34¤Č¤¤¤¦¼Ā¤Ė„¢„°„ģ„Ć„·„Ö¤ŹĄßÄź¤Ī„į„ā„ź„ā„ø„唼„ė¤ņĮČ¤ß¹ē¤ļ¤»¤Ę¤¢¤ėRyzen Threadripper¤Ē¤¹¤é”¤7900X¤č¤źĮźÅöĀē¤¤ŹĆŁ±ä¾õ¶·¤Ė¤Ź¤Ć¤Ę¤¤¤ė¤³¤Č¤Ī¤Ū¤¦¤Ą”£AMD¤ā”ÖAGESA”פĪ²žĮ±¤Ź¤É¤Ė¤č¤ź„į„ā„ź„¢„Æ„»„¹ĆŁ±ä¤ņøŗ¤é¤¹ÅŲĪĻ¤ņ¤·¤Ę¤¤¤ė¤¬”¤ø½»žÅĄ¤Ą¤Č¤Ž¤ĄDDR4¤Ī°·¤¤¤Ē¤ĻIntel¤Ė°ģĘü¤ĪŤ¬¤¢¤ė¤Č¤¤¤¦¤³¤Č¤¬¤č¤ÆŹ¬¤«¤ė”£
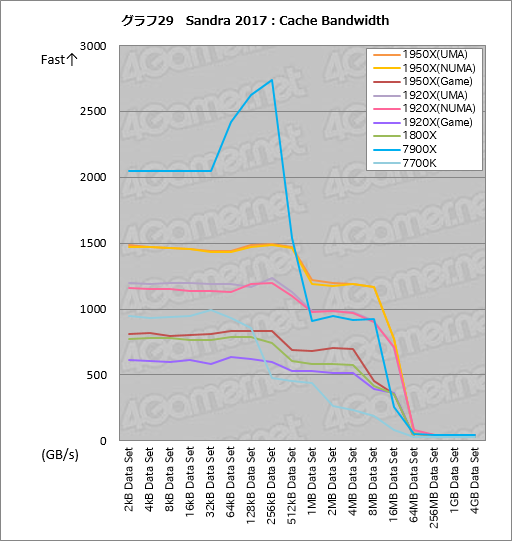
””¼”¤Ė„°„é„Õ29¤Ļ„„ć„Ć„·„弞¤ź¤ĪĀÓ°čÉż¤ņø«¤ė”ÖCache Bandwidth”פĪ„Ę„¹„Č·ė²Ģ¤Ē¤¢¤ė”£°ŹĮ°”¤Sandra 2017¤¬ĖÜ„Ę„¹„ȤĒ7900X¤ĪL3„„ć„Ć„·„å¤ņĒ§¼±¤·¤Ź¤¤¤³¤Č¤¬¤¢¤Ć¤æ¤æ¤į”¤ŗ£²ó¤Ļŗ£²ó¤Ļ„Ę„¹„Č„Ö„ķ„Ć„Æ„µ„¤„ŗ¤“¤Č¤ĖøÄŹĢĀÓ°č¤ņ„°„é„Õ¤Ė¤Ž¤Č¤į¤Ę¤¢¤ė”£„°„é„Õ²čĮü¤ņ„Æ„ź„Ć„Æ¤¹¤ė¤Č”¤¾ÜŗŁ„¹„³„¢¤Ī¤Ž¤Č¤Ž¤Ć¤æɽ5¤ņ»²¾Č¤·¤Ę¤ā¤é¤Ø¤ė¤Ī¤Ē”¤¤½¤Į¤é¤ā„Į„§„Ć„Æ¤·¤Ę¤Ū¤·¤¤”£
””·ė²Ģ¤ĒĢĢĒņ¤¤¤Ī¤Ļ”¤L2„„ć„Ć„·„å¤Ė¼ż¤Ž¤ė”Ö256kB Data Set”×°ŹĘā¤ĪĀÓ°č¤Ē7900X¤¬Ā¾¤ņ°µÅŻ¤¹¤ė°ģŹż”¤¤½¤ģ¤ņĶ¤Ø¤ė¤Č”¤”Ö16MB Data Set”פŽ¤Ē¤Ļ1950X¤ĪUMA¤Ŗ¤č¤ÓNUMA„ā”¼„ɤ¬Ā¾¤ņ°µÅŻ¤¹¤ė¤Č¤³¤ķ¤Ą”£¤Č¤Æ¤ĖCCX¤¬»ż¤ÄL3„„ć„Ć„·„å¤Ī¹ē·×ĶĘĪĢ¤ņĶ¤Ø¤ė”Ö16MB Data Set”פĪĀÓ°čÉż¤¬770GB/s¤ņĶ¤Ø¤Ę¤¤¤ė¤Ī¤¬Ģܤņ¼ę¤Æ”£
””Į°½Ņ¤Ī¤Č¤Ŗ¤ź”¤2“š¤ĪCCX¤¬»ż¤Ä¹ē·×16MB¤Ī„„ć„Ć„·„å¤Čʱ°ģ„µ„¤„ŗ¤Ī„Ę„¹„ȤĄ¤Č”¤Infinity Fabric¤ä„į„¤„ó„į„ā„ź¤ĪĀÓ°čÉż¤¬øś¤¤¤Ę¤Æ¤ė¤Ļ¤ŗ¤Ą”£¤³¤³¤Ž¤Ē¤ā²æÅŁ¤«æؤģ¤Ę¤¤¤ė¤Č¤Ŗ¤ź”¤Infnity Fabric¤Ļ¶Ė¤į¤Ę¹ā¤¤ĄĒ½¤ņ»ż¤Ä¤č¤¦¤Ē¤¢¤ė”£
 |
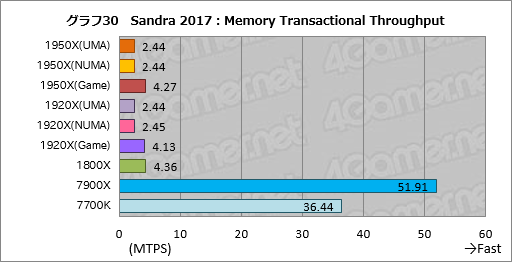
””„°„é„Õ30¤Ļ”Ö„Ž„ė„Į„¹„ģ„ƄɓĶ¤Ė¤Ŗ¤¤¤Ę”¤„¹„ģ„Ć„É“Ö¤Ē„į„ā„ź¤Ī¶„¹ē¤¬ČÆĄø¤·¤æ¾ģ¹ē”פĪ„į„ā„źĀ®ÅŁĄĒ½¤ņø«¤ė”ÖMemory Transaction Throughput”פĄ¤¬”¤°ģø«¤·¤æ¤Ą¤±¤ĒŹ¬¤«¤ė¤č¤¦¤Ė”¤TSXĢæĪį„»„ƄȤņ„µ„Ż”¼„Ȥ¹¤ėIntelĄŖ¤Ī°µ¾””£Ryzen·Ļ¤Ļ¤Ž¤Ć¤æ¤Æ¾”Éé¤Ė¤Ź¤Ć¤Ę¤¤¤Ź¤¤”£
””¤ā¤Į¤ķ¤ó”¤TSXĢæĪį„»„ƄȤĻ¤Ž¤ĄĄŃ¶ĖÅŖ¤Ė»Č¤ļ¤ģ¤Ę¤¤¤ė¤ļ¤±¤Ē¤Ļ¤Ź¤¤¤Ī¤Ē”¤„Ē„¹„Æ„Č„Ć„×PC¤Ē¤³¤ĪĄĒ½ŗ¹¤¬„Ļ„ó„Ē¤Ė¤Ź¤ė¤³¤Č¤Ļ¤Ź¤¤¤Ą¤ķ¤¦”£¤æ¤Ą”¤Intel¤Ļ„Ø„ó„攼„ׄ鄤„ŗøž¤±¤Ī„Ŗ„ó„į„ā„ź„Ē”¼„æ„Ł”¼„¹”ÖSAP HANA”פĖ¤Ŗ¤±¤ėTSXĢæĪį¤ĪøśĶѤņ„¢„Ō”¼„ė¤·»Ļ¤į¤Ę¤¤¤æ¤ź¤¹¤ė¤Ī¤Ē”¤„µ”¼„Š”¼øž¤±CPU¤Ē¤¢¤ėEPYC¤Ē¤Ļ”ÖTSXĢæĪį¤ņ„µ„Ż”¼„Ȥ·¤Ź¤¤¤³¤Č”פ¬„Ļ„ó„Ē„£„„ć„ƄפȤŹ¤ė²ÄĒ½Ą¤Ļ“¶¤ø¤ė”£
 |
””°Ź¾å”¤Sandra 2017¤Ī„¹„³„¢¤ņø«¤Ę¤¤æ¤¬”¤¼«Ę°„Æ„ķ„Ć„Æ„¢„Ƅ׵”Ē½¤¬Ķøś¤Ź¾õĀÖ¤Ē¤Ļ¤ä¤äŹ¬¤«¤ź¤Ė¤Æ¤¤¤Č¤³¤ķ¤¬¤¢¤ė”£¤½¤³¤ĒAIDA64¤Čʱ¤ø¤č¤¦¤Ė”¤1950X¤ĪUMA„ā”¼„ɤČ1800X”¤7900X¤Ī3Ą½ÉŹ¤ĒĮ“„³„¢¤ņ3.5GHz¤ĖøĒÄź¤·¤æ¤Č¤¤Ī„¹„³„¢¤ā»²¹Ķ¤Ž¤Ē¤Ė·Ēŗܤ·¤Ę¤Ŗ¤¤æ¤¤”£
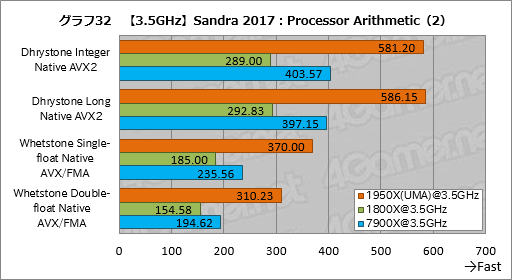
””„°„é„Õ31”¤32¤ĻProcessor Arithmetic¤Ī·ė²Ģ¤Ē¤¢¤ė”£1950X¤Č1800X¤ņČę³Ó¤¹¤ė¤Č”¤Įķ¹ē„¹„³„¢¤āøÄŹĢ„¹„³„¢¤ā¤¤ģ¤¤¤ĖĢó2ĒܤȤ¤¤¦ĄĒ½øž¾åĪؤ¬ĘĄ¤é¤ģ¤Ę¤¤¤ė”£¤Ž¤æ”¤„Æ„ķ„Ć„Æ¤ņĀ·¤Ø¤æ7900X¤ĖĀŠ¤·¤Ę”¤1950X¤¬Įķ¹ē„¹„³„¢¤ĒĢó50”ó”¤øÄŹĢ„¹„³„¢¤Ē44”Į59”óÄųÅŁ¹ā¤¤¤Č¤¤¤¦”¤„³„¢æō¤Č¤Ŗ¤Ŗ¤ą¤Ķø«¹ē¤¦ČęĪؤĪ·ė²Ģ¤¬½Š¤Ę¤¤¤ė¤Ī¤āø«¤É¤³¤ķ¤Ą”£
 |
 |
””Processor Multi-Media¤Ī„¹„³„¢¤Ļ„°„é„Õ33”Į35¤Ė¤Ž¤Č¤į¤æ”£
””Į°½Ņ¤Ī¤Č¤Ŗ¤ź7900X¤Ē¤ĻAVX-512¤¬»Č¤ļ¤ģ¤Ę¤·¤Ž¤¦¤æ¤į”¤1950X¤Ī7900X¤ĖĀŠ¤¹¤ė„¹„³„¢¤Ļ¤Ū¤Č¤ó¤É»²¹Ķ¤Ė¤Ź¤é¤Ź¤¤”£øÅŵÅŖ¤Źx86ĢæĪį¤ņ»Č¤¦Multi-Media Quad-int Native x1 ALU¤Ē”¤1950X¤¬Ģó57”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤·”¤¤Ž¤æAVX-512¤ņ»ČĶѤ·¤Ź¤¤”ÖMulti-Media Quad-float Native x2 FMA”פĒ18”ó¹ā¤¤„¹„³„¢¤ņ½Š¤·¤Ę¤¤¤ė¤Ī¤¬ø«¤É¤³¤ķ¤Ą¤ķ¤¦¤«”£
””ĀŠ1800X¤Ą¤Č1950X¤ĻĮķ¹ē„¹„³„¢¤ĒĢó92”ó¹ā¤¤„¹„³„¢¤ņĆ”¤½Š¤·”¤øÄŹĢ¤Ī„Ę„¹„ȤĒ¤ā78”Į104”ó¹ā¤¤„¹„³„¢¤ņ¼Ø¤·¤æ”£Processor Arithmetic¤Ū¤É¤Ī°ĀÄź“¶¤Ļ¤Ź¤¤¤ā¤Ī¤Ī”¤„³„¢æō¤Ė±ž¤ø¤æ„¹„³„¢¤Īøž¾å¤Ļ¤Ŗ¤Ŗ¤ą¤ĶĘĄ¤é¤ģ¤Ę¤¤¤ė¤Č¤¤¤¦Ķż²ņ¤Ē¤¤¤¤”£
 |
 |
 |
””Ā³¤¤¤Ę„°„é„Õ36”¤37¤ĻProcessor Cryptographic¤Ī·ė²Ģ¤Ē¤¢¤ė”£
””ĀŠ7900X¤Ē1950X¤ĻĮķ¹ē„¹„³„¢¤ĒĢó114”ó”¤AESĢæĪį¤Ė¤č¤ė„¢„Æ„»„é„ģ”¼„·„ē„ó¤ņ»Č¤¦Encryption/Decryption Bandwidth AES256-ECB AES¤ĒĢó94”ó”¤AVX-2ĢæĪį¤ņ»Č¤¦Hashing Bandwidth SHA2-256 AVX512, AVX2¤Ē¤ĻĢó138”ó¤Č¤¤¤¦„¹„³„¢¤Ė¤Ź¤Ć¤Ę¤¤¤ė”£„Æ„ķ„Ć„Æ¤ņĀ·¤Ø¤æ¾ģ¹ē¤Ē¤ā”¤AVX2¤ņ»Č¤¦øå¼Ō¤Ī¤Ū¤¦¤¬1950X¤ĪĄ®ĄÓ¤Ļ¤¤¤¤¤ļ¤±¤Ą”£
””ĀŠ1800X¤Ą¤Č”¤1950X¤Ī„¹„³„¢¤ĻHashing Bandwidth SHA2-256 AVX512, AVX2¤ĒĢó2ĒÜ”£Įķ¹ē„¹„³„¢¤Ē¤āĢó88”ó¹ā¤¤”£
 |
 |
””„°„é„Õ38”¤39”¤40¤ĻProcessor Scientific¤Ī·ė²Ģ¤Ą¤¬”¤¤ä¤Ļ¤źĘĆħÅŖ¤Ź¤Ī¤Ļ„°„é„Õ40¤ĪFFT¤Ą¤ķ¤¦”£1950X¤ĻĀŠ7700X¤ĒĢó77”ó”¤ĀŠ1800X¤Ē¤āĢó120”ó¤Ī„¹„³„¢¤ĖĪ±¤Ž¤ė”£ø¶°ų¤ĻĮ°½Ņ¤Ī¤Č¤Ŗ¤ź”¤FFT¤Ī„¢„ė„“„ź„ŗ„ą¤Ė¤¢¤ė¤Ļ¤ŗ¤Ą”£
 |
 |
 |
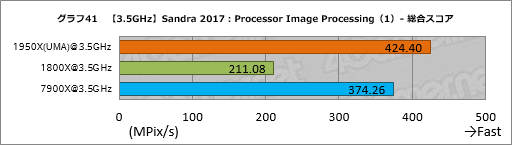
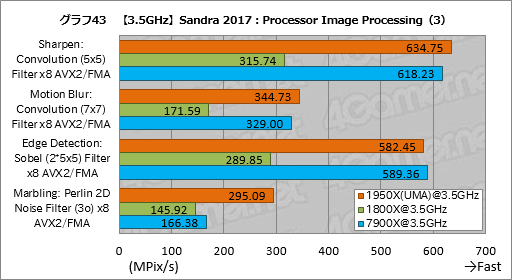
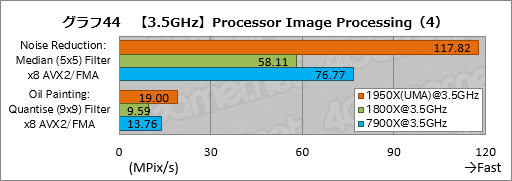
””Processor Image Processing¤Ī·ė²Ģ¤¬„°„é„Õ41”Į44¤Ą”£„Æ„ķ„Ć„Æ¤ņĀ·¤Ø¤Ę¤¤¤Ź¤¤¤Č¤¤Ī·ė²Ģ¤ņŹ¤¤¹„¹„³„¢¤Ļ½Š¤Ę¤¤¤Ź¤¤”£
””Diffusion: Randomise (256) Filter x8 AVX2/FMA¤Ē1.68ĒܤȤä¤äæ¤ÓĒŗ¤ą°Ź³°”¤1950X¤Ļ1800X¤ČČꤣ¤Ę¤Ū¤Ü2ĒܤĪ„¹„³„¢¤¬ĘĄ¤é¤ģ¤Ę¤¤¤ė”£
 |
 |
 |
 |
””Ę°ŗī„Æ„ķ„Ć„Æ3.5GHzĀ·¤Ø¤Ē¤Ī„Ę„¹„Č”¤ŗĒøå¤Ļ”ÖProcessor Multi-Core Efficiency”פĒ¤¢¤ė”Ź„°„é„Õ45”Ė”£¤³¤³¤Ē¤ā„°„é„Õ²čĮü¤ņ„Æ„ź„Ć„Æ¤¹¤ė¤Č„¹„³„¢¤Ī¾ÜŗŁ¤¬¤Ž¤Č¤Ž¤Ć¤æɽ6¤ņɽ¼Ø¤¹¤ė¤č¤¦¤Ė¤·¤Ę¤¢¤ė¤¬”¤Ąč¤Ī„°„é„Õ25¤ČČꤣ¤ė¤Č”¤Ę°ŗī„Æ„ķ„Ć„Æ¤¬Ā·¤Ć¤Ę¤¤¤ėŹ¬¤Ą¤±Ź¬¤«¤ź¤ä¤¹¤Æ¤Ź¤ź”¤”Ö4x 64kB Blocks¤ņĆę擤Ė1950X¤¬¶Ė¤į¤Ę¹¤¤ĀÓ°čÉż¤ņ»ż¤Ä”×·¹øž¤¬¤č¤ź¤Ļ¤Ć¤¤ź¤¹¤ė”£
 |
”””ĔĤ³¤³¤Ž¤Ē”¤Ä¹”¹¤ČSandra 2017¤Ī·ė²Ģ¤ņø«¤Ę¤¤æ”£UMA„ā”¼„ɤČNUMA„ā”¼„ɤĒĢĄ²÷¤Ź°ć¤¤¤¬½Š¤ė„±”¼„¹¤¬Āæ¤Æ”¤¤³¤Ī¤³¤Č¤¬AIDA64¤Č¤Ī°ć¤¤¤ČøĄ¤Ø¤ė¤Ī¤Ē¤Ļ¤Ź¤«¤ķ¤¦¤«”£
””¤Į¤Ź¤ß¤ĖWindows¤Ē¤Ļ”¤NUMA„Ī”¼„ɤ¬2“š°Ź¾å¤¢¤ė„ׄé„Ć„Č„Õ„©”¼„ą¤ĖĀŠ¤·¤Ę”¤ĘĆÄź¤ĪNUMA„Ī”¼„ɤĪ„į„ā„ź¤ņ³ä¤źÅö¤Ę¤ėAPI”ÖVirtual
””Ryzen Threadripper¤ĪNUMA„ā”¼„ɤĒ”¤¤³¤ģ¤é¤ĪAPI¤ņ»Č¤Ć¤Ę„¢„ׄź„±”¼„·„ē„ó¤ņŗĒŬ²½¤¹¤ģ¤Š”¤Ryzen Threadripper¤Ē¤µ¤é¤Ė¹ā¤¤ĄĒ½¤¬ĘĄ¤é¤ģ¤ė²ÄĒ½Ą¤Ļ¤¢¤ė”£¤æ¤Ą”¤¤³¤ģ¤é¤ĪAPI¤ņ»Č¤Ć¤æŗĒŬ²½¤Ļ¤³¤ģ¤Ž¤Ē”¤„µ”¼„Š”¼¤Ē¤·¤«¹Ō¤ļ¤ģ¤Ę¤¤¤Ź¤¤¤³¤Č¤Ļ”¤²”¤µ¤Ø¤Ę¤Ŗ¤ÆɬĶפ¬¤¢¤ė¤Ą¤ķ¤¦”£
”””ÖRyzen Threadripper¤¬ÅŠ¾ģ¤·¤æ¤«¤é¤Č¤¤¤Ć¤Ę”¤°ģČĢøž¤±¤Ī„¢„ׄź„±”¼„·„ē„ó¤ĒNUMA„Ī”¼„ɤņ°Õ¼±¤·¤æŗĒŬ²½¤¬¹Ō¤ļ¤ģ¤ė“üĀŌ¤Ļ¤¢¤Ž¤ź»ż¤Ę¤Ź¤¤¤«¤Ź”פȤ¤¤¦¤Ī¤¬”¤É®¼Ō¤Īø«Źż¤Ą”£¤ā¤Į¤ķ¤ó”¤ŗĒ½ŖÅŖ¤Ė¤Ļ¤³¤ģ¤«¤é¤ĪAMD¤ĪĘƤ¤«¤±¤Ė¤«¤«¤Ć¤Ę¤¤¤ė¤Ī¤Ą¤¬”£
¾ĆČńÅÅĪĻŹäĀ”§Åµ·æÅŖ¤Ź¾ĆČńÅÅĪĻ¤ņÄ“¤Ł¤Ę¤ß¤æ
””ŗĒøå¤ĪŗĒøå¤ĻŹäĀ¤Ē¤¢¤ė”£
””„ģ„ӄ唼Į°ŹŌ¤Ē”¤1950X¤Ŗ¤č¤Ó1920X¤Ī¾ĆČńÅÅĪĻ¤ņ·Ēŗܤ·¤æ”£4Gamer¤Ē¤Ļ”¤„Ł„ó„Į„Ž”¼„Æ„ģ„®„å„ģ”¼„·„ē„ó20.0¤Ē”¤¾ĆČńÅÅĪĻĀ¬Äź¤Ė¤¢¤æ¤Ć¤Ę¤ĻEPS12V¤ĪÅÅĪ®¤ņĀ¬Äź¤·”¤12¤ņ³Ż¤±¤ĘÅÅĪĻ“¹»»¤·¤æĆĶ¤ņ»Č¤¦¤³¤Č¤Ė¤·¤Ę¤¤¤ė¤¬”¤¤³¤Ī¤Č¤ŗĪĶѤ¹¤ėĆĶ¤Ļ“šĖÜÅŖ¤Ė”¤”Ö„¢„ׄź„±”¼„·„ē„ó¼Ā¹Ō»ž¤Ī„Ō”¼„ÆĆĶ”פȤ·¤Ę¤¤¤ė”£
””¤³¤ģ¤Ļ¤³¤ģ¤ĒĢµ°ÕĢ£¤Ź„Ē”¼„æ¤Ē¤Ļ¤Ź¤¤¤Ī¤Ą¤¬”¤EPS12V¤ĪÅÅĪ®¤Ļ”ÖCPU¤Ī„Ź„Ž¤Ī¾ĆČńÅÅĪĻ”פĖ¶į¤¤¤æ¤į”¤ŹŃĘ°¤¬¶Ė¤į¤ĘĀē¤¤¤”£¤½¤Ī¤æ¤į„Ō”¼„ƤĄ¤±¤ņø«¤ė¤Č°ģ¼ļ¤Ī°Ū¾ļĆĶ¤ņ½¦¤Ć¤Ę¤·¤Ž¤¦ĢäĀź¤¬¤¢¤ė”£¤Ä¤Ž¤ź”¤¤“¤Æ¤ļ¤ŗ¤«¤Ź²óæō¤·¤«Ā¬Äź¤µ¤ģ¤Ę¤¤¤Ź¤¤°Ū¾ļ¤Ź„Ō”¼„Ƥ¬ø½¤ģ¤æ¾ģ¹ē”¤¤½¤ģ¤¬„¹„³„¢¤Č¤·¤ĘŗĪĶѤµ¤ģ¤Ę¤·¤Ž¤¦·ēÅĄ¤¬¤¢¤ė¤ļ¤±¤Ą”£
””¼ĀŗŻ”¤„ģ„ӄ唼Į°ŹŌ¤Ē°Ū¾ļ¤Ą¤Ć¤æ¤Ī¤Ļ1800X¤Ī„¹„³„¢¤Ē”¤”ÖDxO OpticsPro 11”פņĶѤ¤¤æ„Ę„¹„ȤĪ¼Ā¹Ō»ž¤Ė”¤¤Ź¤ó¤Č210W¤Č¤¤¤¦”¤10„³„¢¤Ī7900X¤ĖĒ÷¤ė„Ō”¼„ƤņĆ”¤½Š¤·¤Ę¤·¤Ž¤Ć¤æ”£
””¤³¤ĪĢäĀź¤ņ²ņ·č¤¹¤ėĖÉŁ¤Ļ¤¤¤ķ¤¤¤ķ¹Ķ¤Ø¤é¤ģ”¤ŗĒ¤ā„·„ó„ׄė¤Ź²ņ·čŗö¤Ļ”ÖŹæ¶Ń¤ņ¼č¤ė”פȤŹ¤ė¤ļ¤±¤Ą¤¬”¤¼Ā¤Ī¤Č¤³¤ķ”ÖŹæ¶Ń¤ņ¼č¤ė¤Č”¤¤¢¤Ž¤źøųŹæ¤Ē¤Ź¤Æ¤Ź¤ė”פȤ¤¤¦ĢäĀź¤¬¤¢¤ė”£
””¤Č¤¤¤¦¤Ī¤ā”¤Ā¬Äź¤Ī³«»Ļ¤Č½ŖĪ»¤ņ¼źĘ°¤Ē¹Ō¤Ć¤Ę¤¤¤ė“Ų·ø¤Ē”¤³Ę„Ę„¹„ČĀŠ¾Ż¤Ē“°Į“¤ĖĀ·¤Ø¤ė¤Ī¤¬¤Ū¤ÜÉŌ²ÄĒ½¤Ą¤«¤é¤Ą”£¤½¤Ī¤æ¤į”¤¤¢¤ėCPU¤Ī„Ę„¹„ȤĒ¤Ļ„¢„ׄź„±”¼„·„ē„ó½ŖĪ»øå¤Ī„Ē”¼„æ5Ź¬¤Ö¤ó¤ā½ø·×¤·¤Ę¤¤¤ė¤¬”¤ŹĢ¤ĪCPU¤Ē¤Ļ3Ź¬¤·¤«½ø·×¤·¤Ę¤¤¤Ź¤¤¤Č¤¤¤¦„Š„é¤Ä¤¤¬Ąø¤ø¤ė”£
””øĄ¤¦¤Ž¤Ē¤ā¤Ź¤Æ”¤„¢„ׄź„±”¼„·„ē„󳫻ĻĮ°¤ä½ŖĪ»øå¤Ī„Ē”¼„æ·ļæō¤¬Ā椤CPU¤Ū¤É”¤Źæ¶Ń¤ņ¼č¤ė¤ČĶĶų¤Ė¤Ź¤Ć¤Ę¤·¤Ž¤¦”£”Ö„¢„ׄź„±”¼„·„ē„󤬤¤¤Ä»Ļ¤Ž¤ź”¤¤¤¤Ä½Ŗ¤ļ¤Ć¤æ¤«”פņ»Ä¤µ¤ģ¤æ„Ē”¼„椫¤éæäĀ¬¤¹¤ė¤Ī¤Ļ¤Č¤Ę¤āĘń¤·¤Æ”¤¤Ž¤æ”¤”Ö³«»Ļ½ŖĪ»¤ņæäÄź¤·¤Ę„Ē”¼„æ¤ņĄŚ¤ź½Š¤¹”פȤ¤¤¦ŹżĖ”¤ā”¤æäÄź¤Ī»ÅŹż¼”Āč¤Ē·ė²Ģ¤¬ŹŃ¤ļ¤Ć¤Ę¤·¤Ž¤¦¶²¤ģ¤¬¤¢¤ė”£
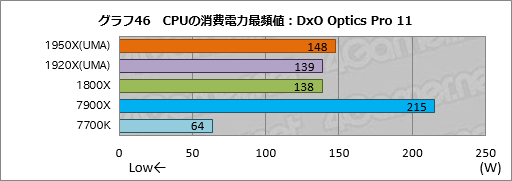
””¤½¤³¤Ēŗ£²ó¤Ļ”¤»Ä¤µ¤ģ¤æ„Ē”¼„æ¤ĪÉŃÅŁŹ¬ĄĻ¤ņ¹Ō¤¤”¤ŗĒ¤ā¹āÉŃÅŁ¤ĒĀ¬Äź¤µ¤ģ¤æ¾ĆČńÅÅĪĻ¤ņÄ“¤Ł¤Ę¤ß¤ė¤³¤Č¤Ė¤·¤æ”£¤¤¤ļ¤ę¤ė”ÖŗĒÉŃĆĶ”פņÄ“¤Ł¤Ę¤ß¤č¤¦¤Č¤¤¤¦¤ļ¤±¤Ą”£ŗĒÉŃĆĶ¤Ē¤¢¤ģ¤Š”¤°Ū¾ļ¤Ź„Ō”¼„ƤĄ¤±¤Ē¤Ź¤Æ”¤CPU¤¬„¢„¤„É„ė¾õĀÖ¤ŲĘž¤Ć¤æ¤Č¤¤ĪÄ椤¾ĆČńÅÅĪĻ¤ā„¹„³„¢¤«¤é¼č¤źµī¤ė¤³¤Č¤¬¤Ē¤”¤¤Ŗ¤Ŗ¤č¤½”Ö„¢„ׄź„±”¼„·„ē„ó¼Ā¹ŌĆę¤Īŵ·æÅŖ¤Ź¾ĆČńÅÅĪĻ”פņĘĄ¤ė¤³¤Č¤¬¤Ē¤¤ė¤Ī¤Ē¤Ļ¤Ź¤¤¤«”©
””¤Č¤¤¤¦¤ļ¤±¤Ēŗ£²óŹ¬ĄĻ¤¹¤ė¤³¤Č¤Ė¤·¤æ¤Ī¤ĻDxO Optics Pro 11¤Ē¤¢¤ė”£·ė²Ģ¤Ļ„°„é„Õ46¤Ī¤Č¤Ŗ¤ź¤Ē”¤¤Ž¤æ¤ā¤ä¶Ć¤¤Ī·ė²Ģ¤Č¤Ź¤Ć¤Ę¤·¤Ž¤Ć¤æ”£
””1950X¤ĪŗĒÉŃĆĶ¤Ļ148W”¤1920X¤Ą¤Č¤½¤ģ¤č¤źÄ椤139W”£¤Ä¤Ž¤ź”ÖDxO Optics Pro 11¤ņ¼Ā¹ŌĆꔤÅö³ŗ¾ĆČńÅÅĪĻ¤Ēæä°Ü¤·¤Ę¤¤¤ė»ž“Ö¤¬ŗĒ¤āŤ«¤Ć¤æ”פļ¤±¤Ą¤¬”¤16„³„¢32„¹„ģ„Ć„ÉĀŠ±ž”¤¤ā¤·¤Æ¤Ļ12„³„¢24„¹„ģ„Ć„ÉĀŠ±ž¤ĪCPU¤Č¤·¤Ę”¤Ryzen Threadripper¤Ī¾ĆČńÅÅĪĻŗĒÉŃĆĶ¤Ļ¤«¤Ź¤źÄ椤¤ČøĄ¤Ć¤Ę¤¤¤¤¤Ī¤Ē¤Ļ¤Ź¤«¤ķ¤¦¤«”£¤Č¤¤¤¦¤«”¤140W¤Č¤µ¤ģ¤ėTDP”ŹThermal Design Power”¤Ē®Ąß·×¾ĆČńÅÅĪĻ”Ė¤ņ¤Ļ¤ė¤«¤ĖĶ¤Ø¤ėæō»ś¤¬ŗĒÉŃĆĶ¤Č¤Ź¤Ć¤æ7900X¤ČČꤣ¤ė¤Č”¤Ryzen Threadripper¤Ī¾ĆČńÅÅĪĻĀŠĄĒ½Čę¤ĻĮĒĄ²¤é¤·¤¤¤ČøĄ¤Ć¤Ę¤¤¤¤”£
””ŗ£²ó4Gamer¤Ē»ī¤·¤æøÄĀĪ¤¬2øĤȤā”ÖÅö¤æ¤ź”פĄ¤Ć¤æ²ÄĒ½Ą¤ĻĒÓ½ü¤Ē¤¤Ź¤¤¤ā¤Ī¤Ī”¤Ryzen Threadripper¤¬7900X¤ČČꤣ¤Ę°·¤¤¤ä¤¹¤¤CPU¤Č¤¤¤¦¤³¤Č¤Ļ”¤øĄ¤¤ĄŚ¤Ć¤Ę¤·¤Ž¤Ć¤Ę¤ā¹½¤ļ¤Ź¤¤¤Č¹Ķ¤Ø¤Ę¤¤¤ė”£
 |
””„ģ„ӄ唼Į°ŹŌ¤Ē„Ō”¼„Ƥ¬°Ū¾ļ¤Ė¹ā¤«¤Ć¤æ1800X¤Ī„¹„³„¢¤Ļŗ£²ó”¤1920X¤Čʱ¤ø„ģ„Ł„ė¤Ė¼ż¤Ž¤Ć¤æ”£¤ā¤Ć¤Č¤ā”¤95W¤Č¤¤¤¦TDP¤Ī„¹„Ś„Ć„Æ¤«¤é¤¹¤ė¤Č¹ā¤į¤Ē”¤1800X¤ĻCPU¤ņ„Õ„ė¤Ė²ó¤·¤æ¤Č¤¤Ė¤«¤Ź¤ź¹ā¤¤¾ĆČńÅÅĪĻ¤ņµĻ椹¤ėĄ¼Į¤¬¤¢¤ė¤³¤Č¤Ļ“ְ椤¤Ź¤¤¤č¤¦¤Ą”£
””¤Ź¤Ŗ”¤Į°½Ņ¤Ī¤č¤¦¤Ė4Gamer¤Ī„Ł„ó„Į„Ž”¼„Æ„ģ„®„å„ģ”¼„·„ē„ó20.0¤Ē¤ĻĀ¬Äź¤µ¤ģ¤æ„Ō”¼„ƤĪ¾ĆČńÅÅĪĻ¤ņ„¢„ׄź„±”¼„·„ē„ó¼Ā¹Ō»ž¤Ī„¹„³„¢¤Č¤·¤ĘŗĪĶѤ·¤Ę¤¤¤ė¤¬”¤°Ū¾ļĆĶ¤ņ¼č¤źµī¤ė¤Č¤¤¤¦°ÕĢ£¤Ē”¤„Ō”¼„Æ°Ź³°¤Ī„Ē”¼„æ¤āŗĪĶѤ·¤Ę¤¤¤Æ·Į¤Ė²žĮ±¤¹¤ė¤³¤Č¤Ė¤Ź¤ź¤½¤¦¤Ą”£
””ŗĒÉŃĆĶ¤ņ¼č¤ė¤«”¤¤¢¤ė¤¤¤ĻĆę±ūĆĶ¤ņ¼č¤ė¤Ī¤«¤Ļø”ʤ¤ĪĶ¾ĆĻ¤¬¤¢¤ź¤½¤¦¤Ą¤¬”¤¤¤¤ŗ¤ģ²žÄź¤·¤æ„ģ„®„å„ģ”¼„·„ē„ó¤ņøų³«¤Ē¤¤ė¤Ī¤Ē¤Ļ¤Ź¤¤¤«¤Č»×¤¦”£
¤Ž¤Ą¤Ž¤ĄÄɵį¤Ē¤¤æµ¤¤¬¤·¤Ź¤¤Ryzen Threadripper
 |
””¤æ¤Ą”¤UMA¤ČNUMAĪ¾„ā”¼„ɤĪ涤ėÉń¤¤¤Ļ”¤¤Ž¤ĄĶż²ņ¤Ē¤¤æ¤Č¤ĻøĄ¤¤¤¬¤æ¤¤”£¤Č¤Æ¤ĖĢń²š¤Ź¤Ī¤¬”¤Éø½ą¤Ī„į„ā„ź„¢„Æ„»„¹„ā”¼„ɤĒ¤¢¤ėUMA¤Ē”¤ø«¤«¤±¤Ī„į„ā„źĘɤ߽Š¤·/½ń¤¹ž¤ßĀÓ°čÉż¤ĻNUMA¤č¤źĪō¤ė¾ģ¹ē¤¬¤¢¤ė°ģŹż”¤Sandra¤ĪFFT¤Ėø«¤é¤ģ¤æ¤č¤¦¤ĖUMA¤¬ĶĶų¤Ė¤Ź¤ė¾ģ¹ē¤ā¤¢¤ė”£
””ŗĒ¤āĀē¤¤ŹĶ×°ų¤Č¤·¤ĘæäĀ¬¤Ē¤¤ė¤Ī¤Ļ”¤NUMA„ā”¼„É»ž”¤ŹŖĶżÅŖ¤Ė¶į¤¤„į„ā„ź¤ņ³ä¤źÅö¤Ę¤ė¤æ¤į”¤CPU„³„¢¤ĪČ¾Ź¬¤¬Ķøś¤Ė»Č¤ļ¤ģ¤Ź¤¤¤«¤é”¤¤Č¹Ķ¤Ø¤é¤ģ¤ė¤¬”¤Ć»¤¤»īĶŃ“ü“Ö¤Ī“Ö¤ĒCPUÉé²ŁĪؤņÄ“¤Ł¤ė¤³¤Č¤¬¤Ē¤¤æ¤Ī¤Ļffmpeg¤ņ»Č¤Ć¤æ„Č„é„󄹄³”¼„É»ž¤Ī¤ß¤Ą”£¤½¤ĪĀ¾¤Ī„¢„ׄź„±”¼„·„ē„ó¤Ē¤ĻÄ“¤Ł¤é¤ģ¤Ę¤¤¤Ź¤¤”£
””ffmpeg¤ČʱĶĶ¤Ī¤³¤Č¤¬Āæ¤Æ¤Ī„Ž„ė„Į„¹„ģ„Ć„É„¢„ׄź„±”¼„·„ē„ó¤ĒČÆĄø¤¹¤ė¤Ī¤Ź¤é”¤UMA¤ņĮŖĀņ¤¹¤ė¤Ī¤¬ĢµĘń¤Č¤¤¤¦·ėĻĄ¤Ė¤Ź¤ė¤Ą¤ķ¤¦”£¤Č¤¤¤¦¤Ī¤ā”¤Sandra 2017¤Ī¹Ķ»””¤ŗĒøå¤Ī¤Č¤³¤ķ¤Ē¤ā½Ņ¤Ł¤æ¤Č¤Ŗ¤ź”¤NUMA„ā”¼„Éøž¤±¤ĪŗĒŬ²½¤¬„²”¼„ą¤ņ“Ž¤į¤æ°ģČĢ„ę”¼„¶”¼øž¤±„¢„ׄź„±”¼„·„ē„ó¤Ē¹¤Æ¼Āø½¤µ¤ģ¤ė¤³¤Č¤Ļ¹Ķ¤Ø¤Ė¤Æ¤¤¤«¤é¤Ē¤¢¤ė”£
””¤Į¤Ź¤ß¤ĖÉ®¼Ō¤¬Ķż²ņ¤·¤Ę¤¤¤ėøĀ¤ź”¤UMA„ā”¼„ɤĄ¤Č”¤”ÖCPU¤Ė¶į¤¤„į„ā„ź¤ņ°ÕæŽÅŖ¤Ė³ä¤źÅö¤Ę¤ė”פȤ¤¤Ć¤æ”¤Ryzen Threadripper¤ĪĘĆĄ¤Ė¹ē¤ļ¤»¤æ„¢„ׄź„±”¼„·„ē„ó¤ĪŗĒŬ²½¤Ļ¹Ō¤Ø¤Ź¤¤”£„¢„ׄź„±”¼„·„ē„ó„ģ„Ł„ė¤«¤éŹŖĶż„į„ā„ź„Ś”¼„ø¤ņĮąŗī¤¹¤ėŹżĖ”¤¬¤Ź¤¤¤«¤é¤Ē¤¢¤ė”£
””µ”²ń¤¬¤¢¤ģ¤Š”¤Ryzen Threadripper¤ĪCPU¤Ī涤ėÉń¤¤¤ņ¤ā¤¦¾Æ¤·Ä“¤Ł¤Ę¤ß¤æ¤¤¤Č»×¤¦¤¬”¤ŗ£²ó¤Ļ¤³¤³¤Ž¤Ē¤Č¤·¤æ¤¤”£
Ryzen Threadripper„ģ„ӄ唼Į°ŹŌ”£ø½»žÅĄ¤ĒĄ¤³¦ŗĒ¹ā¤Ī„Ž„ė„Į„¹„ģ„Ć„ÉĄĒ½¤ņ°ś¤Ć¤µ¤²”¤AMD¤¬„Ļ„¤„Ø„ó„É„Ē„¹„Æ„Č„Ć„×PC»Ō¾ģ¤Ų“Ō¤Ć¤Ę¤¤æ
Ryzen Threadripper 1950X¤ņ„Ń„½„³„ó„·„ē„Ć„× „¢”¼„ƤĒ¹ŲĘž¤¹¤ė
Ryzen Threadripper 1950X¤ņ„Ń„½„³„ó„·„ē„Ć„× „¢”¼„ƤĒ¹ŲĘž¤¹¤ė
Ryzen Threadripper 1950X¤ņAmazon.co.jp¤Ē¹ŲĘž¤¹¤ė”ŹAmazon„¢„½„·„Ø„¤„Č”Ė
Ryzen Threadripper 1920X¤ņAmazon.co.jp¤Ē¹ŲĘž¤¹¤ė”ŹAmazon„¢„½„·„Ø„¤„Č”Ė
AMD¤ĪRyzen ThreadripperĄ½ÉŹ¾šŹó„Ś”¼„ø
- “ŲĻ¢„愤„Č„ė”§
 Ryzen”ŹZen”¤Zen”Ü”Ė
Ryzen”ŹZen”¤Zen”Ü”Ė - ¤³¤Īµ»ö¤ĪURL”§
4Gamer.netŗĒæ·¾šŹó
„ׄé„Ć„Č„Õ„©”¼„ąŹĢæ·Ćåµ»ö
Įķ¹ēæ·Ćåµ»ö
“ė²čµ»ö
æ·ĆåĻ¢ŗÜ
æ·Ćå„ģ„ӄ唼
æ·Ć儤„ó„æ„ӄ唼