








ニュース
西川善司の3DGE:チーフアーキテクトが語った「PS5 Pro」の秘密とは? レイトレーシングの強化点や超解像機能に注目だ
 |
非常に興味深い内容であったので,本稿で深掘りしてみよう。なお,筆者によるPS5 Proの実機評価や技術的側面の考察については,前回の記事を参照してほしい。
PS5 ProのGPUがRDNA 3を採用しなかった理由とは?
動画の冒頭でCerny氏は,「PS5 Proでは,ゲーム体験を変えるつもりはなかった」「PS5 Proで変えたかったのは,ゲームグラフィックスだけ」「ゲーム体験を変えるのは次世代機で」という,「プレイステーションにおけるProモデルの設計思想」について,改めて言及した。そのうえで,動画冒頭においてCerny氏が語ったことのうち,最も興味深かったのは,PS5 ProのGPUでRDNA 3アーキテクチャを採用しなかった理由を説明した部分だ。
 |
 |
このパートでCerny氏は,RDNA 2とRDNA 3では,シェーダプログラムのネイティブコード(※Cerny氏はバイナリコードと呼んだ)に互換性がなく,既存のPS5用ゲームがそのまま動作しないことを,大きな理由として挙げていた。
 |
知る人も多いと思うが,現在のゲームグラフィックスは,2000年頃から始まった「プログラマブルシェーダアーキテクチャ」によって成り立っている。ポリゴンレベルの座標演算処理や,ピクセルレベルのライティング,シェーディングなどは,GPUのハードウェアロジックで実行するのではなく,GPU内に多数実装された「プログラマブルシェーダユニット」上で動作するソフトウェア,すなわちシェーダプログラムで処理するのだ。
シェーダプログラムをざっくり言えば,ゲームタイトル上に登場する,3Dモデルや材質表現,特殊効果(たとえばボケや光りのきらめきなどのエフェクト),そのほかの描画要素(たとえば影や霧)といった要素ごとに存在する。そのため今どきの大作ゲームになると,その数は数万を優に超えるほどだ。
ゲーム機の場合,シェーダプログラムはすべて,開発段階でコンパイル(変換)されており,GPUが直接実行できるネイティブコードの形で製品パッケージに収録されている(物理メディアもオンライン配信も同様)。
一方,PCゲームの場合,DirectXなどのグラフィックスAPI上で表現する中間コードで表現されており,GPUドライバーがゲーム進行時にネイティブコードに変換するか,あるいはゲームの初回実行時に,まとめてネイティブコードに変換したうえで,ネイティブコードをシステム側でキャッシュする仕組みが採用されている。ただ,ゲーム進行時に変換する方法では,変換中に一時停止することが多いため,最近の大作ゲームでは,後者の手法を採用するタイトルが一般的だ。
いずれにせよ,この仕組みのおかげで,PCゲームは,さまざまなGPU上で一貫性のある(という前提の)ゲームグラフィックスを実現している。
PS5 ProでRDNA 3を採用した場合,PCゲームのように,ゲームの初回起動時にネイティブコードへコンパイルすれば,何の問題もない。しかし,ゲーム初回起動時に,シェーダコンパイルが終わるまで長い時間待たされてしまう。PCゲーマーなら慣れたものだろうが,ゲーム機での体験としては許されなかった,ということだろう。
ところで,「RDNA 2とRDNA 3では,ネイティブコードを変更するほどのアーキテクチャ変更があったのか」という疑問が湧いた人もいるかもしれない。これについては「変更があっても不自然ではない」というのが,筆者の所感である。
RDNA 3では,GPUコアである「Compute Unit」(以下,CU)1基あたりの演算器構成がRDNA 2と異なるので,スケジューラの仕様に合わせたコード設計を変える必要があるだろう。またRDNA 3では,ジオメトリパイプライン自体にも深い手が入れられている(関連記事)。もともとPCの世界では,先述したような中間言語の仕組みがあるため,ネイティブコードの互換性が問題になることはあまりない。AMDだけでなくNVIDIAも,カジュアルにネイティブコードはGPU世代ごとに変えている。ゲーム機の世界では,ネイティブコードの変更を重視してRDNA 2のままにした,というのはある程度納得できる話だろう。
 |
そこで疑問が浮かぶのは,RDNA 2より先の世代を採用できるであろう次世代のPlayStationで,PS5以前のゲームとの互換性をどう確保するのかだ。そもそもRDNA世代よりも前,それこそネイティブコードの互換性がないはずのGCN世代GPUを搭載したPS4/PS4 Proのゲームを,PS5/PS5 Proは実行できる。であれば,RDNA 2世代に留まった理由が,ネイティブコードの互換性だけのはずはないと思う。
なお,ハードウェア製造コスト面からRDNA 2世代を採用した理由を考察した記事は,こちらを参照してほしい。
関連記事



西川善司の3DGE:PS5 Proのスペック詳細と実機でのゲームプレイから見えてきた実情。レイトレの強化はゲーム体験も拡張する?
PS5シリーズ初の高性能モデル「PlayStation 5 Pro」。筆者もレビュー機材を使って,さまざまな実験をしている。そこで本稿では,PS5 Pro発表時点には明らかになっていなかった事実を整理しつつ,ゲームを動作させて見えてきたその実情を考察していきたい。
レイトレーシング性能が2〜3倍になるカラクリ。BVH8への対応
2024年9月にPS5 Proが発表されたとき,「PS5 Proのレイトレーシング性能は,最良ケースでPS5の2〜3倍に達する」という説明は,かなりの謎を残した。それがテクニカルセミナーの動画で,詳しい説明が行われたことで,かなり明らかになったのだ。
なお,レイトレーシングの基本については,以下の記事で説明しているので,未見,あるいは改めて理解したい人は参照してほしい。
関連記事
レイトレーシング処理の効率化に欠かせないBVH構造体だが,現在,ゲーム向けのリアルタイムレイトレーシングで活用事例が多いのは,「BVH4」と「BVH8」である。
BVH4とは,最上位階層(親ノード)のひとつ下の階層(子ノード)に,直方体が4つある構成のBVH構造体のことだ。一方のBVH8は,子ノードの直方体が8つになったBVH構造体のこと。どちらも,親ノードにぶら下がる子ノードが,「2x2」や「4x4」のように整然と列んでいる必要はない。
MicrosoftのDirectXは,BVH4とBVH8の両方に対応しているが,どちらかを奨励しているというわけではない。ただ,BVH4とBVH8とでは,それぞれに長所と短所がある。
BVH4は,1ノードがカバーできる子ノードが4つなので,カバー範囲は狭い。しかし,構造としてはシンプルになるので,メモリ消費量を節約できるメリットがある。また,1ノードのカバー範囲が狭いということは,比較的,狭いシーンと相性が良く,細かいジオメトリが密集するような複雑度の高いジオメトリを多く含んだシーンとも,相性が良いとされる。
それに対してBVH8は,1ノードでカバーできる子ノードが8つに広がるので,1ノードで広範囲をカバーできるようになるが,子ノードが8つも必要ない3Dモデルがたくさんあったときにはメモリ消費量は大きくなる。しかし,1ノードのカバー範囲が広いため,BVH4が苦手とする大規模なシーンとは相性が良い。逆に言えば,1ノードのカバー範囲が広いことで,複数のポリゴン(=ジオメトリ)を重複してカバーしてしまうケースも多くなるため,細かいポリゴンが密集するような複雑度の高いモデルを多く含んだシーンとは,相性が悪くなりがちだ。
レイの推進と衝突判定は,BVH構造体に対する探索プロセスとなるので,GPU側のレイトレーシングユニットが,どの形式のBVHに対して最適化されているかが重要になってくる。もちろん,現行のレイトレーシング対応GPUは,BVH4とBVH8の両方に対応できている。DirectXで,両方が使えることになっているのだから当然だ。しかし,GPU内のレイトレーシングユニットが,ハードウェアレベルのアクセラレーションを効かせながらBVH8に対応できているのは,本稿執筆時点でGeForce RTX 50/40/30シリーズのみ。Intelの「Arc A」シリーズやAMDの「RDNA 3」シリーズの場合,レイトレーシングユニットがハードウェアレベルのアクセラレーションで対応できるのは,BVH4までだ。
さて,そこでPS5に話を戻すと,PS5はRDNA 2ベースなので,BVH4までの対応となる。それではPS5 Proも同様なのかというと,なんと,BVH8に対してもハードウェアアクセラレーションが対応するのだ。
 |
PS5 Pro発表時点で,Cerny氏が述べていた「PS5 ProのGPUが未来のレイトレーシング機能に対応している」とは,この部分を指していたわけである。つまりPS5 ProのGPUは,AMDの次世代GPU「Radeon RX 9000」シリーズのレイトレーシング機能「BVH8アクセラレーション」に対応しているようだ。
Cerny氏によると,PS5 Pro GPUのレイトレーシングユニットは,1クロックでBVH8構造体の1ノード,すなわち8個分の直方体を探索でき,探索工程(Intersection)において,2つのポリゴンに対しての衝突判定も行えるという。
 |
というわけで,PS5 Proでは,理論上BVH4に対して最大で2倍の速度で処理できるわけだ。多くのPS5向けゲームは,BVH4ベースのレイトレーシングになっているが,これをPS5 Proに最適化するには,BVH4とBVH8を表現対象に応じて使い分ける選択が,ゲーム開発者には求められる。
そもそもPS5において,レイトレーシングの活用は限定的だったので,ゲームをPS5 Proに最適化させるときに,レイトレーシングユニット向けプログラムをBVH4用とBVH8用でそれぞれ作ることになったとしても,それらは数個で済むことになる。この個別対応にかかる開発者の負担は,Cerny氏としても許容範囲ということなのだろう。
あるいは,PS5と同じBVH4のままであっても,PS5 ProのGPUならば理論上はBVH4を最大で2倍並みの速さで処理できる。つまり,相応に高いレイトレーシング性能を,自動で得られる理屈だ。
なお,BVH4とBVH8の使い分けは,基本的にレイトレーシングの品質には影響しない。基本的には,レイトレーシング対象シーンに最適なBVHを使い分けることで,性能面の利点を高める技術と理解していい。
ハードウェアスタック管理の導入でもレイトレーシング性能を向上
レイトレーシングにおいて,3Dシーン向けてに放たれるレイは,ポリゴンに衝突したあとで複数のレイに分岐したり,反射して別の方向に向きを変えたりすることもある。この場合,新たに生成したレイ(子レイ)は,それぞれの方向に推進を開始する。
子レイも,いずれは推進した先で,別のポリゴンに衝突することがあるだろう。そうしたら,新たに孫レイが放たれることもある。そうした子レイや孫レイの処理が終わると,親元のレイの処理に戻るわけだ。
一時的に処理を中断した親レイや,新たに生成された子レイの情報は,スタックポインタのような仕組みで各GPUコア(Compute Unit,CU)内の共有メモリ領域(おそらくLocal Data Share,LDS領域)に保存されていく。RDNA 3世代のGPUには,こうしたスタック処理を専用ハードウェアで管理,最適化するメカニズムを搭載するのだが,その発展形がPS5 ProのGPUにも組み込まれているようだ。
テクニカルセミナーの動画では,説明を省略していたので,詳細な処理は不明なところも多い。そのため,筆者の推測となる点も多いことを断ったうえで説明していこう。
PS5 ProのGPUにおいて,ハードウェアによるスタック処理の最適化を利用すると,レイトレーシングユニットがプログラマブルシェーダにピクセル単位の陰影処理を発注するときに,比較的,局所性の高いレイの処理を,同じデータスレッドでまとめて行うように制御するようだ。AMDがRDNA 3世代GPUに実装したハードウェアによるスタック処理の最適化機能には,そこまでの能力はなかったはず。つまり,この点もRDNA 4世代GPUの機能を先取りしたのだろう。
 |
ところでテクニカルセミナーの動画では,ここでいささか唐突に,プログラマブルシェーダユニットのSIMD(Single Instruction Multiple Data)演算器による条件分岐と,そのわずらわしさについての説明が入る。これもまた,レイトレーシングの効率化に関わる話なので,簡単に説明してみよう。
SIMD命令処理における条件分岐処理のわずらわしさとは,要約すると以下のようになる。
- 通常の場合,条件分岐付きのSIMD命令においては, IF (条件) 処理1 ELSE 処理2
- SIMD命令の処理対象となる複数のデータスレッドは,処理1と処理2両方の命令群を通ることになってしまう
のような条件分岐を実行しても,実際には分岐するわけではない
コンピュータアーキテクチャに詳しい人なら,「SIMDってそういうものだよね」と理解を示す人は多いだろう。30年以上前のDSP時代から,SIMD命令の実行とは,このように設計されているからだ。CPUが処理するプログラムにおけるジャンプ命令のように,プログラムカウンタにもとづいて分岐先命令のアドレスにジャンプするような処理は,SIMD命令の処理では行われない。条件成立の成否に応じて,対応するデータスレッドひとつひとつに対して,SIMD命令を処理するか,しないかで分けるだけだ。
SIMD命令において,条件成立時を担当するデータスレッドが処理しているときは,条件不成立となったデータスレッドは,処理の終わりをただ待つだけ。逆に,条件不成立時を担当するデータスレッドが処理中は,条件成立時用のデータスレッドは,同様に処理の終了を待つだけだ。つまり,「IF〜ELSE」が多重化して条件分岐が多段になればなるほど,SIMD命令における並列実行の利点は減ってしまう。
これを抑止する方法はシンプルで,SIMD命令実行時に条件分岐をさせないことだ。
 |
Cerny氏が,上掲のスライドで示すSIMD32命令とは,Radeon GPUにおけるプログラマブルシェーダユニットのこと。具体的にいえば,ピクセル単位の陰影処理をレイトレーシングユニットから発注されたプログラマブルシェーダユニットの状態を表している。
プログラマブルシェーダユニットにおいて,なるべく条件分岐させないためには,レイトレーシングユニットが発注する各レイからの陰影処理を,「なるべく同方向,かつ隣接するレイからの発注をひとまとめにして受けるようにすればいいかも」と,Cerny氏は仮説を述べる。なぜなら,似たようなレイならば,そこから発注される陰影処理も同条件となる可能性が高いと推測できるからだ。
やや回りくどい解説だったが,ここまでのCerny氏の話を,筆者の考察を含めてまとめると,「PS5 ProのGPUでは,RDNA 4で実装すると思われる拡張されたハードウェアによるスタック処理の最適化機能を先行搭載することで,プログラマブルシェーダユニットが,同条件の陰影処理をまとめて受注しやすくすることを狙います」ということのようだ。「風が吹けば桶屋が儲かる」ではないが,実際に効果が大きいのだろう。
 |
ここまでの解説で,ピンと来た人もいるだろう。動作原理こそ違うが,同条件に近いレイの陰影処理をまとめてプログラマブルシェーダユニットに発注するという手法は,GeForce RTX 40シリーズが採用した「Shader Execution Reordering」にかなり近いものだ。
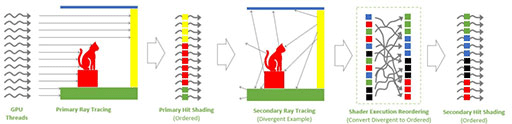 |
AMDとNVIDIAで,手法は少し違うが,レイトレーシングが抱える課題をGPU世代を刷新するタイミングで解決していく流れは,非常に興味深いものである。
PSSR用推論アクセラレータはどこにある?
PS5 Pro発表時,SIE独自のAIベース超解像技術である「PlayStation Spectral Super Resolution」(PSSR)が利用できることが明らかとなった。とはいえ,その実装手法はもちろん,PS5 Proが搭載するどのプロセッサでAI処理を行うのかについては公開されなかったのだ。
それが,テクニカルセミナーの動画で,PSSRに関するかなりの部分が明らかになった。
まずCerny氏は,「PSSRは,超解像に特化した仕組み」と説明しており,筆者の予想どおり,フレーム生成には対応しないことが明確になった。その理由について,Cerny氏は言及しなかったが,PS5 Proの考察記事で筆者が述べたことが,主な理由となっているのではないか。
また,筆者はPS5 Pro発表後の記事でも,「なぜPSSRにSpectralの単語が入っているのか」について考察したが,Cerny氏は「スペクトラルレンダリング」とは一切無関係で,「単にブランドイメージで付けた」とあっさり答えた。
PS5 Proの考察記事でも触れたように,PSSRでは,AIに同じシーンを描いた低解像度の画像と高解像度の画像の相関性をひたすら学習させた,ゲーム映像に特化した超解像学習データを用いて超解像処理を行う。そして,学習データを与えたPSSRをPS5 Proで動作させることで,GPUにとって処理負荷の低い低解像度画像を描画したうえで,PSSRを推論アクセラレータで動作させてリアルタイムで高解像度化した美しい映像を画面に表示するという運用になる。
そのうえで気になるのは,いわゆる「AI処理ユニット」や「NPU」と呼ばれる「推論アクセラレータ」を,どこに搭載したのかという点だ。これについてCerny氏は,「PS5 Proにおける推論アクセラレータは,PSSR専用で搭載する」として,グラフィックス処理とすこぶる相性が良いGPU側に搭載することを決めたそうだ。
 |
 |
PS5 Pro発表後の記事でも筆者は,GPU側に推論アクセラレータを搭載する可能性が高いと考察していた。Radeonに推論アクセラレータが統合されたのは,RDNA 3世代GPUからだ。そのため,CU数が60基のRDNA 3世代GPUによる推論アクセラレータの理論性能値を試算したことがある。簡単におさらいしてみよう。
「AI Accelerator」と呼ばれるRDNA 3世代GPUの推論アクセラレータは,CU 1基ごとに2基を搭載している。AI Acceleratorは,16bit浮動小数点データを1度に2要素取り扱える32bit SIMD積和算器(2 FLOPS)の「Wave Matrix Multiply Accumulate」(WMMA)を64基備えるので,CU 60基構成のPS5 Pro GPUがRDNA 3世代なら,演算性能はこうなる。
- 64 WMMA×2要素×2(FLOP)×2 AI Accelerator×60(CU)×2.17GHz≒67 TFLOPS ※動作クロックは公称値の2.17GHzを採用
RDNA 3の推論アクセラレータの場合,8bit整数精度時には2要素が「4」要素となるだけなので,結果は2倍となって134 TOPS(※整数なのでTFLOPSではなくTOPS)。だがこれでは,Cerny氏が目標として掲げた300 TOPSにはまったく届かない。
しかしCerny氏は,「そこで我々は,8bit時の3×3の積和算を1サイクルで実行できるように,推論アクセラレータをカスタムした」という趣旨の説明をしている。この説明からすると,RDNA 3のAI Acceleratorをベースにしてはいるものの,8bit整数をターゲットしたときに限り,積和算器については3×3,つまり9要素を一気に入力できる仕様であると推測できる。
そこで,先の式にこの条件を当てはめて計算すると,
- 64 WMMA×9要素×2(OP)×2 AI Accelerator×60 CU×2.17GHz≒300 TOPS ※8bit時は整数なのでFLOPではなくOP
ちょうど300 TOPSに到達するわけだ。
なお,テクニカルセミナーの動画でCerny氏は,以下のスライドで理論性能値を説明していた。この式ではCU単位ではなく,CU 2基で1組の「Work Group Processor」(WGP)単位で計算しているので,内容としては上述の式と同じである。
 |
300 TOPSを生かすためのメモリ空間と金縛りモード
先に述べたとおり,Cerny氏らはPSSRの実行にあたって,総処理時間を1ms以下に抑えると言う目標を掲げて,実現のために理論性能値 300 TOPSの推論アクセラレータを搭載しようと考えた。それを実現するために,乗り越えなければならない障害のひとつが,メモリバス帯域幅である。
PS5 Proのメインプロセッサと,メインメモリ兼グラフィックスメモリであるGDDR6メモリをつなぐメモリバス帯域幅は,576GB/sだ。この値を侮ることなかれ。576GB/sという帯域幅は,PC用GPUのグラフィックスメモリバス帯域幅と比べると,「GeForce RTX 4070」の504GB/sを上回り,RDNA 3世代GPUである「Radeon RX 7900 GRE」とまったく同等だ。PC用メインメモリで一般的なDDR5メモリの場合,DDR5-6000でも96GB/sしかないので,PS5 Proのメモリバスは,実に5倍以上の帯域幅にもなる。
それでも「1ms以下でPSSRの処理を終えるためには,圧倒的に性能不足だった」とCerny氏。さらに,「我々が考えるに,300 TOPSの理論性能値を持つ推論アクセラレータを最大限に生かすためには,数百TB/sの帯域幅が必要だった」(Cerny氏)という。PC業界の人間なら,ひっくりかえりそうな要求だ。
8bitデータを処理する300 TOPSの推論アクセラレータは,300TB/sでやってくるデータを処理できる能力を持つと仮定できる。もし,メモリアクセスにともなう遅延を無視して,読み出しと書き出しを1byteずつ逐次処理した場合,576GB/sのメモリバス帯域幅は半分となるので,300 TOPSの推論アクセラレータにとって1000倍も遅い理屈だ。
- 300TB/s÷(576GB/s÷2)=1042倍
 |
 |
天才は,考えることが突拍子もない。そこで,Cerny氏が率いる開発チームは,「GPU内の汎用レジスタを,PSSR動作時だけ,瞬間的に推論アクセラレータのSRAMとして使えるようにしてもらえないか,AMDに頼んでみよう」と考えた。SRAMとは,キャッシュメモリなどに用いられる超高速なメモリだ。DRAMとは比べものにならないくらい高速で,数TB/sの帯域幅を持つ。
しかし,微細化と大容量化が難しいため,プロセッサ内部のキャッシュメモリのように,本当に高速に動作させる必要があるメモリに限定して使われるのが一般的だ。実際,GPGPUに対応するGPUでは,キャッシュメモリを汎用SRAM的に活用できる特別な動作モードを備えるものもある。SRAMを使う手法なら,現実的に思える。
それでも,Cerny氏は納得しなかったようだ。「GPUのL2キャッシュ帯域幅は,たかだか数TB/s程度で物足りない。我々は数百TB/sの帯域が欲しいんだ」。こんな依頼を受けたときの,AMDのAPU/GPU開発部隊が,どんな顔を浮かべたのだろう。筆者には想像もできないが,とにかくAMD側は,Cerny氏らの要望に応えた。
AMDが実装したのは,とんでもないアクロバティックなソリューションだった。それは,プログラマブルシェーダユニットが動作するのに必要不可欠な,GPUコア内にあるすべてのSRAM製ベクターレジスタを,推論アクセラレータ用のSRAMとして動作させる変態的な動作モードだった。
PS5 ProのGPUでは,CU 2基=WGP 1基あたり容量128KB,帯域幅1.67TB/sの4セットのベクターレジスタがある。これをGPU全体で活用すれば,総容量は15MBのSRAMになる。
1セットあたりのベクターレジスタ(くどいようだがSRAMだ)は,帯域幅1.67TB/s。そして推論アクセラレータはCU 1基あたり2基あるので,WGP 1基あたり4基になる,このベクターレジスタも4セットあるので,すべて並列に動かせる。総メモリバス帯域幅を計算すると,
- 1.67TB/s×4×30 WGP=200.4TB/s
となるので,約200TB/sの帯域幅を持つSRAM空間として,推論アクセラレータから利用できるわけだ。300TB/sには及ばないが,これでCerny氏らは妥協したわけである。
 |
なお,PSSRの処理は,入力画像を最大で30のタイルに分割して,それぞれのタイルに対するPSSR処理を,30基のWGP(=CU 60基)に並列発注する。つまり,GPUが実際に描画した画像は,30個に分割されたうえで30基のWGP内にあるSRAMに送られるわけだ。そのうえで,SRAM内の画像に対して120基(=CU 60基×2 AI Accelerator)の推論アクセラレータが,それぞれPSSRを適用していくのである。
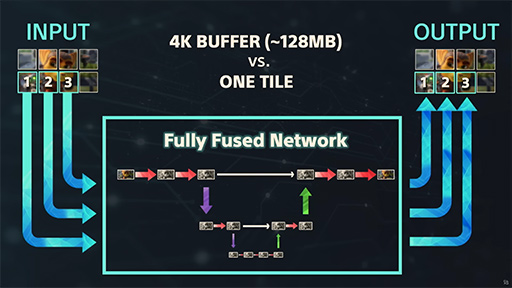 |
ただ,「素晴らしい,なんというコロンブスの卵的な発想だ!」と,喜ぶのは早い。PSSRを処理中は,当然ながらGPUコア内のベクターレジスタが使用不可となるため,事実上,GPUのプログラマブルシェーダユニットは動作できないのだ。GPU全体が動作できないわけではないが,描画関連のスレッドは動作不能になるため,人間に例えると,意識はあるのだが動けないような金縛り状態になる。
余談気味だが,この金縛りモードのことを,SIEは「TAKE OVER MODE」と呼んでいる。
とはいえ,この金縛り状態は,PSSR処理時間となるわずか1ms以下で終わる。おそらく,マイクロ秒単位の金縛りなのだろう。200TB/sの帯域幅で推論アクセラレータにデータを入れて,それを滞りなく処理できると仮定すると,解像度3840×2160ドットのHDR10映像を,1秒間に600万枚処理できるほどの能力がある。1枚あたりの処理にかかる時間は,概算でわずか160ns(ナノセカンド,ナノ秒)程度。60fpsにおける1フレーム分の時間は約16.67ms(ミリセカンド,ミリ秒)であるが,160nsは0.00016msにしかならない。
実際には多段のニューラルネットワークを通すので,PSSRの処理時間は,nsよりも長いμs(マイクロセカンド,マイクロ秒)の単位にはなりそうだが,それでもすごい機能である。
SIEとAMDが共同でゲーム向けAI活用に取り組む「Amethyst」
 |
PS5 Pro開発の過程で,AMDとSIEは,「AIがコンピュータゲームに貢献できることはいろいろあるに違いない」という確信を持ったという。そこで,ゲーム向けの次世代AI技術を想定した新しいハードウェア技術を開発するプロジェクト「Amethyst」(アメジスト)を立ち上げることに合意したのだそうだ。
アメジストは「紫水晶」のことだが,これは,Radeonのイメージカラーである赤と,PlayStationのイメージカラーである青を混ぜた色が紫であることから付けられたプロジェクト名だそうだ。AMDは,SIEチームのPSSRの取り組みに感銘を受けて,一方のSIEは,無理難題に近い要望に答えてくれたAMDの技術力に感銘を受けたのかもしれない。
いずれにせよ,Amethystの成果物は,次世代PlayStationに搭載されるに違いない。
 |
Mark Cerny氏によるテクニカルセミナーの動画
PlayStation公式WebサイトのPS5 Pro製品情報ページ
- 関連タイトル:PS5本体
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー