









ニュース
NVIDIAの新機軸を理解する(3):クラウドGPUソリューションとGPU仮想化技術の核心に迫る
Keplerアーキテクチャに合わせてNVIDIAが打ち出した方向性を確認するシリーズ第3回,最終回。第1回で紹介した「GeForce GRID」の企業向け版といえる「VGX」を解説しつつ,NVIDIAのクラウドGPUソリューションがどういうものなのか,課題と将来性はどこにあるのかを整理してみよう。
 |
 |
最近だと「スーパーフォンからスーパーカーまで」「スーパーフォンからスーパーコンピュータまで」といったメッセージを,自社プレゼンテーションの最初や最後に企業スローガンとしてよく用いている。
実際,同社がスーパーフォンと位置づける高性能スマートフォンや,タブレット,AV関連機器,車載機器などといった,いわゆる組み込み系にはTegra,PCにはGeForce,ワークステーションにはQuadro,スーパーコンピュータにはTeslaといった具合に,各セグメントに向けて製品が用意されている。4Gamerはゲームメディアなのでゲーム機についても触れておくと,PlayStation 3のGPU「RSX」はGeForce 7000シリーズがベースとなっているので,ゲーム機にもNVIDIAハードウェアが入っていることになる。
「すべての機器にGPUを」の先にあるもの
とはいえ,すべての機器に最高性能のGPUを搭載するのは難しい。なぜなら,それぞれの機器には大きさや質量といった物理的制限や,消費電力的な限界などがあるためだ。現時点での話をするならば,携帯電話に「GeForce GTX 680」を搭載することは現実的でない。というかほとんど不可能である。
それともう1つ。現代人の我々は,スマートフォンやタブレット,PCといった機器でメールを見たり,Webを見たり,SNSやblogを楽しんだり,写真や動画を編集したりといったIT活動を行えるが,すべての機器で同じことができるわけではない。メールや写真といった基本的なデータなら,GmailやらDropboxやらといったサービスを使うことで複数機器間で同期させながら利用できるものの,高度なグラフィックスを必要とするアプリケーションだとそうはいかないのである。
データは共有できても,当該データを利用するための環境が限定されてしまうというのは,よくある話だ。
 |
そうしたニーズに対してNVIDIAが2012年から新たに打ち出してきたのが,「GPUs in the Cloud」(GPUをクラウドへ)という戦略である。
 |
2012年になってNVIDIAが掲げだしたGPUs in the Cloud戦略は,その意味でクラウド戦略の第2段階とでもいうべきもので,あえて言い換えるなら,「グラフィックスレンダリングをクラウドへ」というものになる。
この第2フェーズにおいてNVIDIAは,2つのソリューションを打ち出している。1つが本シリーズ第1回でお伝えした「GeForce GRID」,もう1つが「VGX」だ。
GeForce GRIDの解説記事と根幹技術が共通しているので,以下,一部の話は被るが,VGXは「高度なリアルタイムグラフィックスレンダリング機能を持った仮想マシンをクラウド上に実現する」というものになる。
仮想マシンとは,実体の存在しないPCやワークステーションのこと。ユーザーは,スマートフォンやタブレット,最低限の性能を持ったPCといった手持ちの端末から,仮想マシンを,自分のPCやワークステーションのように使うことができる。
そして,「仮想マシンをクラウドから提供しよう」という話は,ビジネスの現場だと,近年,かなり身近なものになってきている。Citrix(シトリックス)やVMWare(ヴイエムウェア)といった企業が,実際にプロセッサの仮想化を実現した商用サービスを提供していたりもする。
立ち遅れていたGPUの仮想化
プロセッサにおける仮想化技術とは何か。
端的に言えば「プロセッサの実体は1つでも,それを複数個あるように見せかける技術」であり,同時に「使い手から見ると,それが自分専用のプロセッサとして使える技術」ということにもなる。
最も身近な仮想化技術はCPUのものだろう。Intelの「Intel Virtualization Technology」(Intel VT)やAMDの「AMD Virtualization」(AMD-V)を連想する読者も多いだろうが,もっと低級(low level)な話で仮想化に近いものがある。それはCPUのマルチスレッディング動作だ。
マルチスレッディングに対応したCPUは,シングルコアCPUであっても,複数のスレッドを同時に動作させることができる。そしてそのとき,当該システム上で動作しているアプリケーションソフトウェアからすれば,“自分”だけのメモリ空間が与えられ,あたかも“自分”だけがCPUを占有して動作しているかのように実行できる。
複数のプログラムが走っていても,他のプログラムの機嫌を取らずとも,アプリケーション自体のプログラム進行だけをまっとうできる。これは仮想化というよりもコンテクストスイッチング寄りの話題かもしれないが,基本要素としては共通する部分が多い。
それほどまでにCPUでは仮想化という概念が古くから存在していたのだが,対するGPUの仮想化はこれまでまったく手がつけられていなかった。
ついでながら付け加えると,GPUはコンテクストスイッチングでも進化が遅れている。これはシリーズ第2回の記事でも紹介したことだが,GPUではグラフィックスレンダリングとGPGPUのタスクをオーバーラップさせることができない。動作モードを完全に切り替えなくてはならないのだ。また,グラフィックスとGPGPUの動作モードを問わず,同一種類のタスクであっても,複数アプリケーションの処理をタイムスライス(=処理が1タスクに偏らないよう,1タスクがプロセッサを利用できる時間を区切ること)するのも不可能である。
仮想化において,GPUは完全に立ち後れているのだ。
ソフトウェア実装によるGPU仮想化技術
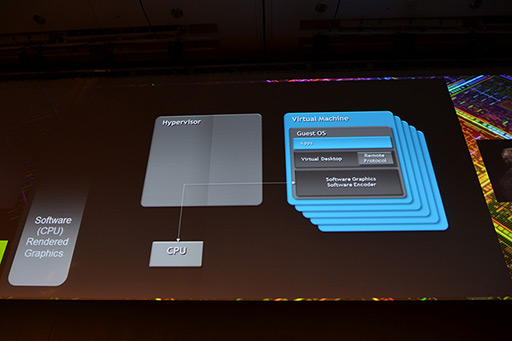
GPUの仮想化がまったく行われてこなかったこともあり,実在する仮想マシン上のグラフィックスレンダリングはCPUベースのフルソフトウェアエミュレーションが主流だ。たとえばCitrixが提供する仮想マシンだと,グラフィックス描画は100%,CPUによって行われているため,当然のことながら遅い。
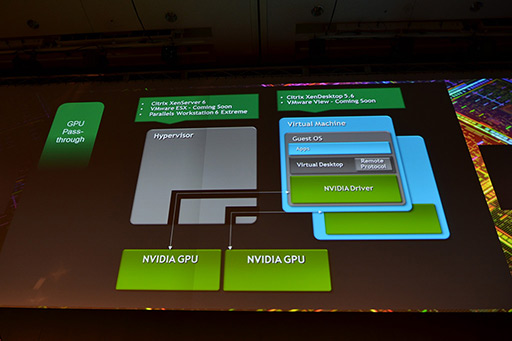
ちなみにCitrixでは「コストを度外視して最大のグラフィックス性能を得たい」というニーズに対しては,仮想マシンごとに専用のGPUを与えるソリューションを提供中だ。
 |
 |
一方,グラフィックスレンダリング自体は実体のあるGPUで行い,仮想化プロセスをソフトウェアで実装するという,コストパフォーマンス重視のアプローチも生まれている。
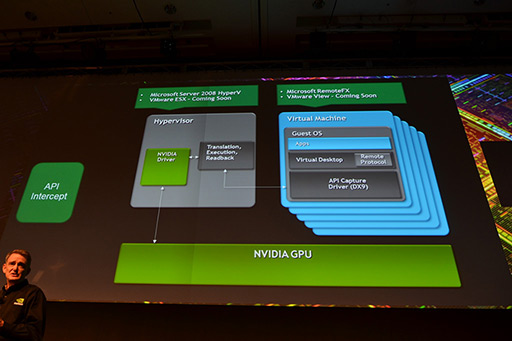
それが,MicrosoftのWindows Server 2008向けに用意される仮想化システム「Hyper-V」用のデスクトップ仮想化システム「RemoteFX」である。RemoteFXを採用したシステムでは,「グラフィックスレンダリング用APIコールだけを集約したドライバシステム」を仮想マシンにインストールしておき,回収されたAPIコールを,ハイパーバイザ(hypervisor,仮想化を実現するための制御プログラム)側で実際にソフトウェア実装したスケジューラでスケジューリングしながらGPUに発注していく。そしてハイパーバイザはGPU側での実行結果を回収して,実際にAPIコールを行った仮想マシンに返すのだ。
こういったアプローチは,フルCPUエミュレーションと比べると性能面で明確に優れ,かつ,仮想マシンごとに専用GPUを用意するのに比べるとコスト面で明確に優れている。だが,各処理プロセスに介入するソフトウェア処理のオーバーヘッドが大きいため,GPUが持つ最大パフォーマンスを得にくい。また,現状ではこのAPIコールを回収するドライバの対応状況があまり芳しくなく,DirectX 9レベルやOpenGL 2.x程度までに留まっているため,仮想マシンで動作させられるグラフィックスアプリケーションの機能に制限が出てしまっているという問題もある。
 |
KeplerのGPU仮想化技術
その意味で大きな一歩といえるのが,Keplerアーキテクチャで初めて採用されたハードウェアレベルの仮想化技術,VGXだ。
 |
2つめは,各仮想マシンごとに確立できる専用チャネル(Per-VM Dedicated Channels)だ。
仮想マシンがグラフィックス描画の発注を行うと,これを受けたハイパーバイザは仮想GPUマネージャを介して実体GPUにレンダリングタスクの立ち上げを命じる。ここまではソフトウェアによるGPU仮想化と同じで,違ってくるのはここから先だ。
実体GPUは,GPU MMUを利用して必要なメモリを確保し,さらにそのレンダリングタスクを発注した仮想マシンとの専用チャネルを割り当てる。仮想マシンはそれ以降,当該仮想マシン専用に割り当てられた仮想GPU(=仮想マシンから見ると自分だけが専用に使えるGPU)を,ハイパーバイザを通さず,この専用チャネル経由でグラフィックス描画を直接発注できるようになる。
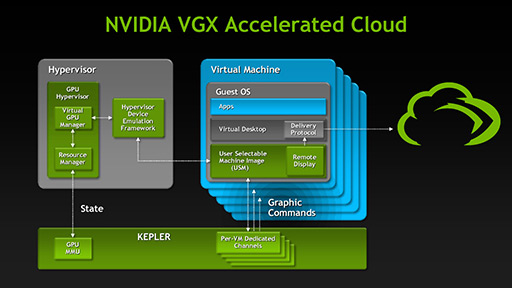 |
仮想マシン用の専用チャネルを実現するうえでポイントとなるのが,上の図で「USM」(User Selectable Machine)と書かれているドライバだ。もっともUSMはドライバというよりも,当該仮想マシンに組み込まれる「GPU関連処理専用のミニハイパーバイザ」のようなもので,グラフィックスレンダリングを行うときに,システム全体の様子伺いをして,うまく仮想GPUが確保できれば,それ以降は仮想化されたGPUを直接叩いてもらうといったことを実現させる。
USMの存在によって,ソフトウェア実装のGPU仮想化よりもオーバーヘッドを極めて小さくできるうえ,GPU側ではグラフィックスメモリ管理をハードウェアで行えるため,高い描画性能も発揮できるようになるのだ。
またUSMは,実行形態こそ特殊ながら,GPUドライバとしてのフル機能を持ってもいるため,最新のDirectXやOpenGLの機能をすべて利用でき,さらにCUDAの利用までも行える。仮想マシン上で動作させられるグラフィックスアプリケーションの制限がほとんどなくなるのだ。
リモートデスクトップはビデオストリームで
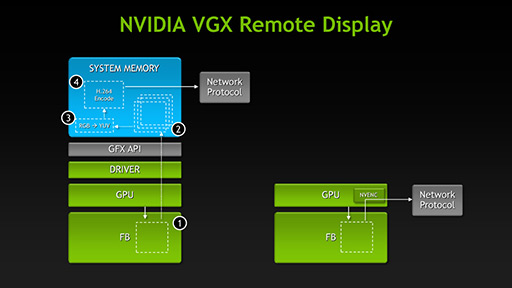
クラウド側に置かれた仮想マシンは,インターネットの向こうにいるユーザーに対し,当該仮想マシンのデスクトップやそのほかのグラフィックスレンダリング結果を,ビデオストリームの形で伝送する必要がある。
GUIベースのOSを走らせ,高度なグラフィックスアプリケーションを利用できることを保証する仮想マシンサービスにとって,ビデオストリームをどう伝送するかも重要な機能要素だ。
KeplerコアのGPUでは専用H.264エンコーダ「NVENC」搭載しているため,これを利用することで,連続したレンダリング結果(やデスクトップ)を極めて短い所要時間でビデオストリーム化できるようになっている。
NVENCはH.264(MPEG-4 AVC)エンコーダで,NVIDIAによれば,(出力映像の画質にも左右されるが)リアルタイムのおよそ4〜8倍速相当でエンコードできるとのことだ。これにより,ビデオストリームの伝送までにかかる時間を可能な限り短縮しているのである。
 |
まだ進化の余地が残るKeplerのGPU仮想化技術
仮想化されたGPU内部で,仮想マシンからのレンダリングタスクは実際にどう実行されているのかだが,結論めいたことから述べると,実行途中にあるレンダリングタスクに対してコンテクストスイッチングは行われない。
そしてそれはKeplerも当てはまる。たとえば仮想マシン1から発注されたレンダリング処理の最中に,仮想マシン2からのレンダリング発注があっても,Keplerは取りかかっている「仮想マシン1からの発注」を中断せず,その処理を終えてから仮想マシン2の発注に取りかかる。
さらに踏み込んでいえば,仮想マシン1からの発注が3Dグラフィックスのフルフレームレンダリングだった場合,その1フレームを描ききるまで,仮想マシン2からの発注には取りかからない。
というか,「取りかからない」のではなく「取りかかれない」のだ。
これは,Kepler世代のGPUのコンテクストスイッチングが,(依然として)「プリエンプション」(Preemption,優先処理)に対応していないためである。これはつまり「Kepler世代のGPUではまだ,いま取りかかっているタスクが終わるまで,次のタスクが積まれていることを知る術がない」ということでもある。
この解決には,割り込みによるプリエンプションを行う機構と,高速なコンテクストスイッチングの機構が必要になる。
ちなみに,この2つの機構が搭載されると,グラフィックスレンダリングとGPGPUの並行実行や,異なる複数アプリケーションに向けたググラフィックスレンダリングのオーバーラップ実行なども可能になる。
その意味でVGXはGPUの仮想化においてまだまだ初期段階であり,進化の余地はまだかなり残されていると言えるのだ。
VGXとGeForce GRIDの違い
 GTC Japan 2012でWill Wade氏はVGX Boardを掲げてみせた |
 これがその実機 |
そういう位置づけなので,さまざまな実装形態が考えられるが,GTC Japan 2012の時点では,KeplerコアのGPUを4基と,GPUあたり容量4GBのグラフィックスメモリを搭載する製品の存在が公表されている。接続インタフェースはPCI Express x16だ。
 |
実際のVGX Boad搭載サーバー製品としては,Dellの「PowerEdge R720」を皮切りに,数社から登場が予定されているとのこと。また,従来型のサーバーであっても,Teslaを搭載可能な製品であれば,VGX Boardの搭載も行えるとのことだった。
 |
 |
 |
GeForce GRIDについてはシリーズ第1回でお伝えしているが,ではVGXとGeForce GRIDの決定的な違いは何かというと,それはGPUの性能と数だ。VGXは一般的なPC作業を想定しているのに対し,GeForce GRIDはゲームプレイを想定したものなので,搭載するGPUのスペックや,1枚の専用カードに搭載されるGPUの数が異なってくるのだ。
NVIDIAによれば,VGXボードではカード1枚で約100ユーザー分――発表済みの4 GPU仕様ならGPU 1基あたり25ユーザー分――の仮想マシン用仮想GPUが提供されるが,GeForce GRIDでは1枚あたり4〜8ユーザー,GPU当たり2〜4ユーザーが想定されているとのこと。それだけGeForce GRIDのほうがGPU要求が大きいのである。
VGXが想定する一般的なPC作業で,GPU負荷がゲームほどは高くなることはまずない。それこそプログラマブルシェーダユニットを数基起用すれば事足りるケースが大半になる。また,クラウド上の仮想マシンからネットワーク上のユーザーの端末に向けて配信されるビデオストリームも,フレームレートが低くても,それほど頻繁に画面が書き換えられるわけではないから問題ない。これはすなわち,ビデオストリームを生成するためのH.264エンコーダへの負荷も低いことを意味する。
しかし,ゲームの場合はそうもいかず,グラフィックスのレンダリング結果はそれこそ毎秒30コマ〜毎秒60コマでコンスタントにユーザーの端末側に伝送してやらなければならない。すなわちNVENCはフル稼動状態になりやすい。そして,そのグラフィックスレンダリングのためのプログラマブルシェーダーユニットの活用は,相当に高負荷なものになる,というわけである。
そうした理由のため,VGXとGPU GRIDでは,技術的に似たソリューションでありながら,別々の専用カードが提供されるのだ。
GPU仮想化技術の進化がもたらすもの
……このように,まだまだ課題を残しているものの,NVIDIAは,GPUの仮想化技術に対して積極的に取り組み始め,それをクラウド技術に応用してきた。
なおNVIDIAは,「現在,我々のGPU仮想化技術はグラフィックスレンダリングのためのものであり,GPGPU用途に使えるものではない」と述べており,さらに「GPGPU用途に使えるGPU仮想化を実現するためには,プリエンプション機構の搭載が不可欠だ」とも述べている。
リアルタイムレンダリングでは,それこそミリ秒のオーダーで描画が終了して次のレンダリングタスクに取りかかれるので,プリエンプションの仕組みがなくても,別の仮想マシンからのレンダリング発注にミリ秒のオーダーで切り換えられることになるが,GPGPU用途では,1タスクの所要時間が長くなると想定されるため,そうも言っていられなくなる。NVIDIAもそのことは課題として把握しているというわけで,次世代以降のGPUでは,この部分に対して手を入れてくるのではないかと思われる。
ところで,VGXに代表されるクラウド向けのGPU仮想化技術は,仮想マシンのための技術である。せっかくこういう技術があるなら,今後は,この仮想化技術を一般ユーザーにとって身近なものにしてほしいところだ。
たとえば,GPUをPCやホームサーバー上でも仮想化できるようにして,ハイエンドのグラフィックスカードが持つ3D性能やGPGPU性能を,ユーザーが所有するさまざまな端末から利用できるようになったりすれば面白いだろう。
あるいは,プリエンプション機構に対応した仮想化を実現したタイミングで,PC上のGPU 1基を2基に見せかけるようにするのもアリだと思う。これが実現できれば,グラフィックスレンダリングとGPGPU(≒CUDA)処理とをタイムスライスで同時に実行させられるようになり,GPUの多目的かつ有効な活用が可能になる。これはPCゲーマーにとっても嬉しい仮想化技術になるはずだ。
今後は,GPUの進化において,実装される仮想化技術の動向も注意深く見ていく必要があるのではなかろうか。
NVIDIAの新機軸を理解する(1):GeForce GRIDが描く「ゲームスタジオが独自のゲームプラットフォームを描く時代」
NVIDIAの新機軸を理解する(2):DirectXの進化が止まったいま,ゲームグラフィックスはもうGPGPUに頼るしかない!?
- 関連タイトル:
 CUDA
CUDA
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー