









連載
西川善司の3DGE:GeForce RTX 50完全解説後編 GPUにAI処理で大きな変革をもたらす「ニューラルシェーダ」とは何か?
 |
GeForce RTX 50完全解説の前編は,GeForce RTX 50シリーズのラインナップ整理と,Blackwellアーキテクチャにおける先進的機能のひとつ「Mega Geometry」を中心に解説した。後編では,もうひとつの先進的機能である「Neural Shader」(ニューラルシェーダ)を中心に解説していこう。
なお,前編を読んでいる読者を対象とした記事であるため,未読の人は,まず前編を参照してほしい。
関連記事



西川善司の3DGE:GeForce RTX 50完全解説前編 Blackwell世代の構造とレイトレーシングにおける革新
Blackwell世代のGPU「GeForce RTX 50」シリーズは,製造プロセスこそ前世代と変わらないが,内部はゲームの性能にも関わるさまざまな改良が施されていた。NVIDIAが明らかにした詳細情報をもとに,前後編でGeForce RTX 50シリーズの全貌に迫ってみよう。
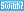
「ニューラルシェーダ」が誕生した背景
ニューラルシェーダの概念を理解するには,大前提として「プログラマブルシェーダアーキテクチャとは何か」と,なぜニューラルシェーダが必要になったのかを理解しておく必要がある。手短に解説したい。
1990年代,ゲームグラフィックスにおける表現能力の強化は,GPUの機種ごとにハードウェアで実装された特殊な表現の機能を活用する必要があった。今でこそ,シェーダプログラムのありふれたサンプルである微細な凹凸を表現する「法線マッピング」(バンプマッピング)も,プログラマブルシェーダ技術が誕生する以前の「GeForce 2」シリーズ時代までは,GPUのハードウェア機能で実現していたものだ。
1990年代当時,「3Dアクセラレータ」などと呼ばれていたGPUは,数多くの半導体メーカーが製造しており,各メーカーは新GPUをリリースするたびに,そのGPUでしか利用できない表現機能を搭載していた。だが,それら機能のほとんどは,ゲーム開発者に使われなかった。今ほどPCゲームが一般化していなかった時代に,GPU固有の表現機能に対応するほどの開発コストをゲーム開発者がかけられなかったのだ。そのため当時のPCゲームは,すべてのGPUで動作する,非常にベーシックな表現に対応するだけなのが通例だった。
そこに登場したのが,プログラマブルシェーダという概念だ。
 |
アプリケーションをインストールして,PCやスマートフォンに新たな機能を与えるように,コンピュータグラフィックスを実現するさまざまな要素をソフトウェアで実現しようとする概念が,プログラマブルシェーダアーキテクチャである。NVIDIAが2000年にリリースした「GeForce 3」が,プログラマブルシェーダに対応した世界初のGPUだ。
その後のGPUの進化は,事実上,プログラマブルシェーダアーキテクチャの進化に等しい。複雑な命令セットを使った長いシェーダプログラムを実行できるようになり,扱える数値表現の種類も増えた。「ジオメトリシェーダ」や「テッセレーションステージ」といった新しい頂点パイプラインの追加も,プログラマブルシェーダにおける進化の一環と言えよう。
プログラマブルシェーダアーキテクチャは急速に広がり,近代ゲームグラフィックスのほぼすべてが,これを土台に作られた。据え置き型ゲーム機においても,2001年登場の初代Xboxからプログラマブルシェーダアーキテクチャの導入が始まり,2006年登場のPlayStation 3の頃には移行が完了した。スマートフォンでは,2009年登場の「iPhone 3GS」あたりから移行が進んだと記憶している。
プログラマブルシェーダアーキテクチャによって急速な普及と進化を遂げたGPUのプログラマビリティは,2010年前後には,CPUと比較しても遜色ないものに到達した。こうして,今では高度な材質表現まで可能になったプログラマブルシェーダだが,リアルタイムの描画で表現できる材質には,すでに限界が見えていた。
事前計算や近似手法を活用した,巧妙な疑似表現技術もある。しかし,「GPU負荷に対して,得られる表現力がいまひとつ」なのが正直なところだ。たとえば,以下に挙げる要素は,表現難度,つまり疑似手法でもGPU負荷が高い。
- 微細な凹凸と反射がある布や金属,フィルム
- 表面下散乱をともなう人肌や植物,ゴムやシリコン
- ゼリーのような半透明材質
間接照明(大局照明)も面倒なテーマだ。レイトレーシングで行うのが理想的だが,演算負荷は高い。そのため,今でもレイトレーシングは使わずに,事前計算ベースの「Precomputed Radiance Transfer」(PRT)法や,Radiance Volume(ライトプローブ)法を使って,擬似的に表現することが多い。
現行のプログラマブルシェーダアーキテクチャは,限界に近づいているわけだ。
進化の限界を迎えつつあるプログラマブルシェーダアーキテクチャに対して,近年では以下のような要望が寄せられるようになった。
- レイトレーシングほどの正確さは求めない
- レイトレーシングほどのGPU負荷はかけたくはない
- 事前計算ベースやそのほかの近似的,疑似的手法よりも説得力のある表現が欲しい
- それでいて,3Dシーンの複雑さに依存しない安定した処理性能も必要だ
こうした要望に対して,GPU業界側は,「GPUに推論アクセラレータを載せているのだから,AI活用で対応していきましょう」という方向性に進みつつある。プログラマブルシェーダからAI機能を利用可能にすることで,シェーダプログラム内でAIの推論処理を利用できる仕組みがニューラルシェーダというわけだ。
 |
なお,ニューラルシェーダに語感のよく似たキーワードに「ニューラルレンダリング」があるが,これについても解説しておこう。
ニューラルレンダリングとは,AI処理を活用してCGを描画する概念全般を広義的に指すようだ。そのため,ニューラルシェーダを活用してCGを描画することは,当然ニューラルレンダリングになる。また,NVIDIAのAIベースの超解像(+アンチエイリアス)技術の「Deep Learning Super Sampling」(DLSS)も,ニューラルレンダリングの一種と言える。
どちらかと言えば,最初期のニューラルレンダリングは,2D画像から3Dシーンを再構築する「Neural Radiance Field」(NeRF)技術のようなコンピュータビジョン系業界で盛り上がっていた印象がある。一方のニューラルシェーダは,「ニューラルBRDF」や「ニューラルBSDF」といった後段で紹介する「ニューラルマテリアル」系の技術の台頭が盛り上がりのきっかけとなった感じだ。
 |
ニューラルシェーダの例 1
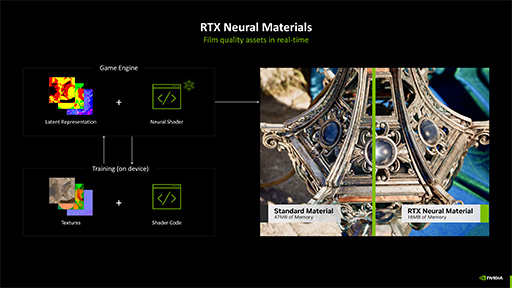
ニューラルマテリアル
では,ニューラルシェーダ技術で,一体どんなことができるようになるのかを具体的に見ていくとしよう。ひとつめは「ニューラルマテリアル」(Neural Materials)だ。
本稿執筆時点で主流のゲームグラフィックスでは,「物理ベースレンダリング」(Physically Based Rendering,PBR)という概念がよく使われている。材質を表現するときに,光を当てたときの反射特性を現実世界の材質に近くなるようにしたレンダリング技法だ。表現したい材質において,全方位からの入射光に対する出射光の応答特性をデータ化したテクスチャを用いて行うことが一般的だ。入射光に対する出射光の総和が等しくなるように,エネルギー保存則に従うこともルールである。
PBRにおいては,入射光に対してどんな出射光を返すかという「双方向反射率分布関数」(Bidirectional Reflectance Distribution Function,BRDF)を表現するために,その材質のBRDF構成パラメータとして,以下の要素に分解したテクスチャマップを用いることが多い。
- アルベド:ベースカラー。拡散反射要素
- メタリック:金属性。特定の色になりやすい要素
- ラフネス:面の粗さ。鏡面反射要素
- 法線ベクトル:微細凹凸の向き
テクスチャマップといっても,画像テクスチャではなく,2次元のデータテーブルのようなイメージだ。実際の材質表現を行う場合,複数枚からなるBRDFの構成要素をまとめたテクスチャを参照して,BRDFの解を求めなければならない。
とても複雑な陰影を返す材質については,事前生成した「BRDFテクスチャ」を用いて,ライティングやシェーディングすることもある。BRDFテクスチャとは,入射光と出射光の関係性を,半球状(2軸180度)の全方位に渡ってあらかじめ測定して,測定結果をまとめたテクスチャマップ(ルックアップテーブル的なデータ配列)のことだ。だが,そうした測定値ベースのBRDFテクスチャを用いても,リアルな表現には限界がある場合もある。
こうした事情を背景に,「PBRの材質表現において,とくに複雑な材質の表現にAIの力を借りてはどうか?」という発想で誕生したのが,ニューラルマテリアルである。
複数枚のテクスチャを使って行っていたライティングやシェーディング演算を,単一の学習データ(テクスチャ)を用いた推論処理で代替できるかもしれない。また,従来手法では説得力の足りなかった複雑な陰影がある材質の表現を,向上できるかもしれない。すべての材質表現で用いる必要はないものの,こういった理由でAIベースのニューラルマテリアルは期待されているのだ。
 |
とくに,これまでの手法では,ライティングやシェーディングの演算に影響を与えるのが難しかった要素を盛り込める可能性が,ニューラルマテリアルにはある。この点に対する期待も大きい。
たとえば顔の肌は,表情筋の伸縮に応じて厚みが変化する。そのため照明条件が同じでも,口を開けたときと閉じたときで頬の色は変化するものだ。正確な表現を目指そうとすれば,どんな表情をしているかの情報と連動した陰影変化を求めなければならず,難度が高い。
しかし,AIベースのニューラルマテリアルによる人肌表現であれば,一般的な光学パラメータや幾何学パラメータ以外に,表現すべきキャラクターの顔の位置,表情や感情といったパラメータも加えて学習データを作成すれば,より高度な材質表現が可能になるだろう。
ニューラルシェーダの例 2
ニューラルテクスチャ圧縮
Blackwellの発表に合わせてNVIDIAは,ニューラルマテリアルを下支えする技術として,「ニューラルテクスチャ圧縮」(Neural Texture Compression,NTC)技術を発表している。
これまでのテクスチャ圧縮は,圧縮前データを適当なブロックに分解した上で,各ブロック単位で構成テクセルの色情報を正規化してから,損失(誤差)を許容する量子化を行っていた。これを「Block Compression」(BC)方式と呼ぶ。
解像度が異なるテクスチャのバリエーションについては,実際に縦横を半分にして面積比で4分の1ずつに縮小したテクスチャを,同じように圧縮して階層的に持つ構造とした。いわゆるMIP-MAP構造だ。こうした現行のテクスチャ圧縮方式は,それなりの圧縮率と品質を有するうえに,GPUコアがテクスチャに素早くアクセスできるメリットがある。
だがニューラルテクスチャ圧縮では,圧縮の概念がまったく異なるのだ。ニューラルテクスチャ圧縮は,テクスチャデータを「横解像度(W)×縦解像度(H)×チャンネル数(C)」の次元を持つテンソルと見なし,より低次元な特徴データ(Latent Vector,潜在ベクトル)へと変換することで圧縮していく技術である。
潜在ベクトルへの変換には,一般的なAI系画像圧縮で用いられるオートエンコーダ(自己符号化器)は使わない。圧縮アルゴリズムについての詳細は,NVIDIAが公開しているこちらの論文を参照してほしい。
W×Hは本来,テクスチャの縦解像度と横解像度に相当するが,本稿執筆時点のニューラルテクスチャ圧縮では,WとHは同一の値と決まっている。一方のCは,たとえば画像テクスチャなら,RGBの3原色で3チャンネルになる。とはいえニューラルテクスチャ圧縮では,値の意味そのものはとくに不問だという。たとえば法線マップテクスチャであれば,法線ベクトルの(x,y,z)値になるが,RGB値を扱う場合と区別はしない。「あらかじめテクスチャ種別に合わせた圧縮ができるように,学習データをトレーニングしている」と,NVIDIAは説明していた。
次のスライドは,ニューラルテクスチャ圧縮で圧縮した事例になる。
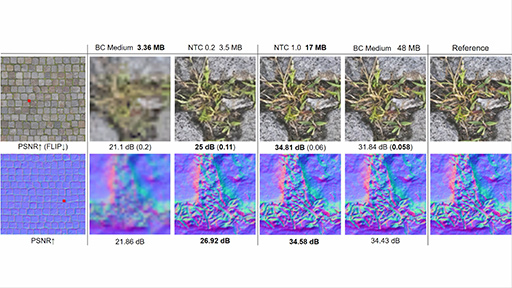 |
上側はアルベド(拡散反射)テクスチャで,下側は法線ベクトルテクスチャ(法線マップ)だ。右端の「Reference」は無圧縮画像で,「BC〜」はDirectXで標準的なテクスチャ圧縮方式を用いて圧縮した例。「NTC〜」がニューラルテクスチャ圧縮の例だ。dB値は画質を表し,高い値ほど画質が良い。それぞれの方式で圧縮した画像から,近い容量同士で画質を比較すれば,ニューラルテクスチャ圧縮の品質の高さは一目瞭然だ。
また,複数枚からなるPBR用のBRDFテクスチャを,まとめて圧縮して使うことも可能だという。
たとえば,1024×1024テクセルのテクスチャの場合,MIP-MAPレベルの0から3までは,256×256と128×128の潜在ベクトルのペアで表現できる。なぜ2組のデータで構成するのかというと,解像度の高いものは解像度情報を,低い側は勾配(グラデーション)情報を担当するためだ。
肝心の圧縮率はどうなのか。従来方式では最も高画質な「BC7」法が,6分の1程度の圧縮率となる。それに対してニューラルテクスチャ圧縮では,同等の画質を16分の1程度で実現できるという。「現在主流の『BCx』法と比べると,同品質では平均約3倍の圧縮率を実現できる」と,NVIDIAはアピールしていた。
 |
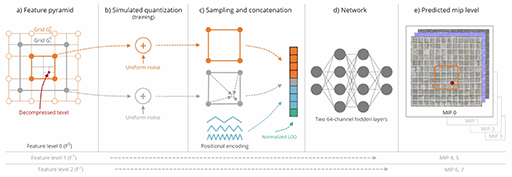
なかなか魅力的なニューラルテクスチャ圧縮だが,課題もある。テクスチャフィルタリング処理がソフトウェアベース(=シェーダプログラムベース)となるので,処理負荷がそれなりに高いのだ。またニューラルテクスチャ圧縮では,テクスチャアクセスのたびにTensor Coreで展開してからサンプリングとなる。ゲームで扱うすべてのテクスチャをこの方法で扱うのは,現実的には難しそうだ。Tensor Coreをテクスチャアクセス専用にすると割り切れば,別の話だが……。
すべてのテクスチャをニューラルテクスチャ圧縮に置き換えるには,GPU側のテクスチャユニットが,ハードウェアレベルで直接ニューラルテクスチャにアクセスできて,なおかつ,テクスチャフィルタリングもハードウェアレベルで実現されるようになってからではないだろうか。
 |
ニューラルシェーダの例 3
ニューラルラディアンスキャッシュ
NVIDIAが,大局照明を実現するためのニューラルシェーダとして紹介した「ニューラルラディアンスキャッシュ」(NRC)は,2021年に同社がSIGGRAPH 2021で発表した論文「Real-time Neural Radiance Caching for Path Tracing」がもとになっている。筆者によるレポートでも簡単に紹介したが,改めてもう少し詳しく解説したい。
現在のゲームグラフィックスにおいて大局照明を実現するには,レイトレーシング法でまじめに描画する方法が,まず思い浮かぶ。しかし,処理負荷がかなり高いので,PlayStation 4時代から使われている事前計算ベースの方法を用ることは,今でも多い。そのひとつが,先にも名前を挙げたPrecomputed Radiance Transfer(以下,PRT)法だ。
PRT法は,3Dシーンにおける光の伝搬ネットワークを事前に計算しておき,そのネットワークに対して動的に配置した光源情報を入力して要所要所の間接照明を計算しておくテクニックである。
より積極的に事前計算を進めた「Radiance Volume」(ライトプローブ)法も,今でも使われる手法だ。これは,あらかじめ静的な光源を配置した3Dシーンにおいて,その空間内の要所における間接照明が,全方位に向けてどんな色の光を放射するのかという情報である「放射輝度」(Radiance)として事前に計算しておく方法だ。
PRT法は,描画時の演算量が多くなるものの,動的光源との整合性が高くなるメリットがある。それに対してRadiance Volume法は,描画時の演算量が少ない代わりに,描画品質はやや劣る。また,どちらの手法も動的キャラクターへの間接照明は行えるものの,静的な光源の出現や消失,3Dシーンそのものの破壊といった3Dシーンの更新には対応できない。動的キャラクターが3Dシーンに影響を与える間接照明も表現できない。
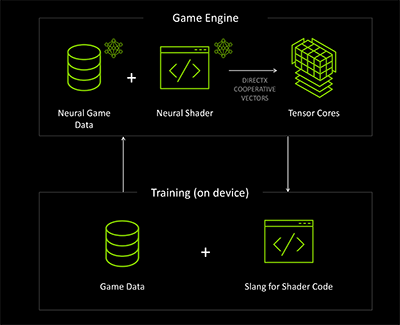
それに対して,新概念のニューラルラディアンスキャッシュは,事前計算が不要で,動的光源の出現や消失といった3Dシーンの更新,動的キャラクターによる間接光への影響にすら対応できる,ある意味では夢のようなテクニックだ。とはいえ,当然課題はあるのだが,それは後述するとして,まずは説明を続ける。
ニューラルラディアンスキャッシュの概念を,超簡単に説明しよう。
 |
基本的な描画方針は,レイトレーシング(パストレーシング)と変わらない。しかし,レイが何度か(※現時点は1回)衝突して定義した中断条件を満たしたら,レイトレーシングを中断するのだ。中断条件は,衝突した材質の特性やノイズ許容度,GPU性能などによって調整する。
そして,中断時点で求められた放射輝度情報と,そのほかの付随情報――たとえば衝突した座標やレイの向き,衝突面の法線ベクトル,材質情報など――を,ニューラルネットワークに入力していく。これが学習に相当する。
イメージ的には,最初は直接光に近い,正確性の高いライティングやシェーディングで学習が進められていく。
ニューラルラディアンスキャッシュにおける実際の描画プロセスはどうなるか。まず,描画中のレイトレーシングが途中で処理を中断した場合,中断時点でレイがまだ3Dシーン内にあって,レイトレーシング工程が続くと仮定する。その場合,中断までの学習データを活用して,AIによる推論を行う。推論によって,レイトレーシングを続けた場合に得られるであろう放射輝度の値を計算するわけだ。あとは,学習と推論を同時に進めながら,描画を継続していく。
学習データ自体が,描画を進めることで更新され,より洗練されていくのがポイントである。
固定的な学習データを用いて推論するAI処理系の性能と比べると,ニューラルラディアンスキャッシュの性能は,メモリバス帯域幅に依存してしまう。ただ,ニューラルラディアンスキャッシュにおけるニューラルキャッシュ自体は,グラフィックスメモリ上に確保できるので,容量はそこそこ大きく取れるようである。
以下に,ニューラルラディアンスキャッシュの品質を比較したサンプル画像を示す。クリックして拡大画像を見てほしい。なお,これらサンプル画像は,あえてデノイザ(ノイズ低減フィルタ)を使っていない。しかし,過去フレームの状態や周辺ピクセルを参照して,パストレーシングの品質を上げる技術「Reservoir-based Spatio-Temporal Importance Resampling」(ReSTIR)は使っている。
 |
 |
 |
 |
ニューラルラディアンスキャッシュを適用するほうが,描画品質はたしかに高い。注目すべきは,画像左端にある姿見に写った鏡像だ。ざらつきはあるが,ニューラルラディアンスキャッシュのほうが鮮明に描かれている。これにデノイザを組み合わせれば,1ピクセルあたり1レイでも,間接光表現としては,十分に見るに堪えるものになりそうだ。
ニューラルラディアンスキャッシュ技術のユニークな点は,ゲーム進行中に,次々に算出される3Dシーン構造と放射輝度の相関情報を学習していくことで,推論の品質,つまりは描画の品質を高められるのだ。
「Unreal Engine 5」の「Lumen」や,「CryEngine 3」が実装して世界を驚かせた「Light Propagation Volume」などもそうだが,時間方向に演算を分散していく間接照明技術は多い。ニューラルラディアンスキャッシュも,その一種である。そのため,初期状態では誤差が多く,ノイズの多い画像になりがちだ。それを踏まえると,ゲームのグラフィックスエンジンにニューラルラディアンスキャッシュを実装するには,デノイザも実行したり,通常のラスタライズ法で描画した画像と適宜合成したりして,ノイズを目立ちにくくする必要はあるだろう。
しかし,事前計算が不要で,ゲームシーンのリアルタイムでダイナミックな破壊や更新にも対応できる点は,ゲームグラフィックス向けの技術だと言える。また,GPUの性能が上がれば上がるほど,ニューラルラディアンスキャッシュの品質が短時間で向上するのも利点だ。
 |
ニューラルシェーダの例
RTX SkinとRTX Neural Faces
「RTX Skin」については,あまり詳しい情報が公開されていない。NVIDIAの説明によると,人肌のような半透明材質を積層した素材に対する照明現象である「表面下散乱」(SubSurface Scattering,SSS)を,レイトレーシングで実現するためのライブラリとのことだ。
これまで人肌のようなSSS材質は,人肌に当てた白色レーザー光が,照射点からどのくらい離れたらどのような色の光が出てくるか」を測定した「反射率拡散プロファイル」(Reflectance Diffusion Profile,RDP)を使って,近似的にSSSを演算する手法が主流だった。
 |
 |
それに対してRTX Skinは,逆光状態を含めた全方位からの光を受けた人肌のSSSを計算できると,NVIDIAはアピールしている。レイトレーシングの処理時に,レイを描画対象の3Dオブジェクト内に潜り込ませるのか,あるいは,AI支援によってBRDFを実現するのかは不明だが,とにかく全方位のSSS表現に対応しているようだ。
 |
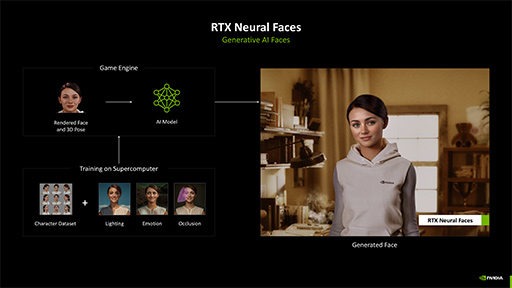
「RTX Neural Faces」という新技術も,人肌というか,顔の表現をAI支援で行うニューラルシェーダ技術として発表されたものである。この技術は独特すぎるため,本稿執筆時点での筆者は,「はたして本当にゲームに使えるのか」と半信半疑である。ただ,技術としては面白すぎるので,解説しておこう。
RTX Skinは,人肌表現に特化したものだったが,RTX Neural Facesでは,CGで描画したキャラクターの顔の表現力を高めるための,いわばポストプロセス的な処理だ。
まずは顔の肌を,SSSのような表現は使わずに,それこそPlayStation 2時代に先祖返りしたような拡散反射だけのシェーディングで描画する。ただ,口や頬の動き,そのほかの感情表現などは,なるべく今どきの表現を盛り込んでおく。
 |
この,いわばすっぴん状態の顔をRTX Neural Facesに入力すると,画像生成系AI技術によって,最もリアルに見える状態に顔を化粧したものを出力する。落書きを清書するようなAIアプリのように,画像生成系AI技術を使って,古くさい顔のCGをリアルに加工するわけだ。
 |
RTX Neural Facesでは,顔のCGと,各表情に対応する人間の顔写真の相関性を学習させたデータを用意しており,出力品質は学習データに依存する。学習と推論時に入力する顔CGには凹凸の情報もあるので,人肌の質感表現だけでなく,しわの表現や,凹凸に現れる陰影の出方も表現できる。
 |
おそらく,RTX Neural Facesの学習データも,ゲーム開発側で製作したりチューニングできたりするのであろう。語弊があるかもしれないが,生成系AIを使った顔専用のDLSSと言えなくもない。学習データを工夫すれば,古くさい顔のCGから,アニメ調の顔を生成することもできそうだ。
まじめに顔や肌を表現しつつ描画するのと,低負荷に描画した顔をAIで化粧するのとでは,どちらが処理負荷が軽いのか。ゲーム開発者やアーティストが狙った感情や表情による演技表現ができるのか。ゲーム開発に採用するには,このあたりも大きな判断基準になるだろう。
なお,RTX SkinやRTX Neural Faceについては,NVIDIAが提供するニューラルレンダリングライブラリである「NVIDIA RTX Kit」に含まれる予定だ。
ニューラルシェーダはGeForce RTX全シリーズで利用可能に
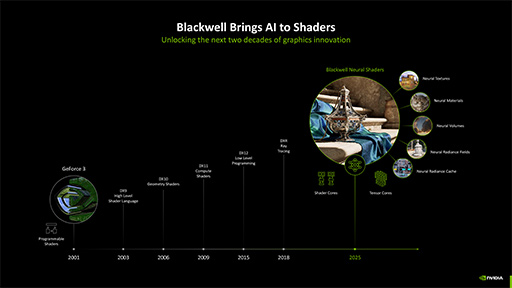
NVIDIAは,どのようにして現在のプログラマブルシェーダアーキテクチャに,ニューラルシェーダの推論処理を統合したのだろうか。
開発者視点からすればシンプルで,推論アクセラレーション処理を組み込んだ(呼び出せる)シェーダプログラムを書けるというものだ。
プログラマブルシェーダ言語における業界標準としては,DirectXで使う「High Level shading language」(HLSL)と,OpenGL系の「OpenGL Shading Languag」(GLSL)が有名だ。こうした既存のシェーダ言語は,当然ながらニューラルシェーダに対応してはいない。しかし,対応に向けた動きは,すでに始まっている。
Microsoftは,NVIDIAによるGeForce RTX 50シリーズの発表直後に,公式の開発者向けBlogで,「DirectXでニューラルシェーダ技術に対応していく」と表明した。もともとHLSLは,NVIDIAが先行して開発,提唱したプログラマブルシェーダ言語「Cg」をベースとしたものだ。ニューラルシェーダについても,NVIDIAがリーダーシップを取って業界標準を決めていく流れが見え始めている。
 |
Slangは,「Shader Language Next Generation」(※諸説あり)と呼ばれる新しいプログラマブルシェーダ言語だ。基本的にはHLSLをベースに拡張したもので,シェーダプログラムのモジュール化や,C++的なテンプレートや「型」に対応している。
もとはと言えばSlangは,SIGGRAPH 2018でNVIDIAが発表したものだ。それが2024年に,オープンスタンダード化を目指して,各種APIの標準化を担当する業界団体であるKhronos Groupと協力して,標準化に乗り出したという経緯がある。2024年には,Slangの公式サイトもオープンした。
ニューラルシェーダ対応に向けた言語仕様の策定も進んでいて,おそらくDirectXやOpenGL系のAPIも,事実上,Slang仕様を取り込んでいくのではないか。
ちなみに,DirectXのHLSLチームは,HLSLに「協調ベクトル命令」(Cooperative Vectors)の対応を追加する計画を立ち上げた。そして,標準化とクロスプラットフォーム対応に向けて,DirectX協賛企業のAMD,Intel,NVIDIA,Qualcommと「協議を進めている」と,Microsoftの開発者向けBlogで発表している。協調ベクトル命令の対応とは,行列演算命令への対応のことであり,推論アクセラレータをシェーダプログラムから利用可能にするのと同じこと,と理解していい。
その実行メカニズムはどうなるのかなのだが,基本的には,プログラマブルシェーダユニット(GeForceではCUDA Core)が,直接そうした命令を実行するのではなく,GPU内の推論アクセラレータに発注する方式になるらしい。GeForce系で言えば,推論処理についてはCUDA CoreからTensor Coreに発注するメカニズムのようだ。
筆者がNVIDIAに確認したところ,推論アクセラレータを搭載するGeForce RTXシリーズであれば,最新のBlackwellでなくてもニューラルシェーダは利用できるとのことだった。
 |
ニューラルシェーダは,推論アクセラレータ搭載のGPUで動作するので,DirectXが対応すれば,GeForce RTXだけでなく,IntelやAMDのGPUでも利用可能になるだろう。一方で,推論アクセラレータを搭載しない旧世代GPUでは,代替命令によるソフトウェアの互換性確保は理論上可能だろうが,性能面で実用には適さないと考えられる。
ニューラルシェーダの支援機能 1
SER 2.0
Ada世代で導入された「Shader Execution Reordering」(SER,以下 SER 1.0)が,Blackwellではニューラルシェーダの実行効率を上げるために,第2世代版の「SER 2.0」へと進化した。
Ada世代のSER 1.0は,レイトレーシング時に,レイトレーシング実行ユニットであるRT Coreから,CUDA Coreへ発注したライティングやシェーディング処理スレッドを,なるべく高い並列度で処理できるように実行順序を制御する仕組みだ。
それがBlackwellのSER 2.0では,CUDA Coreのスレッド実行制御だけでなく,CUDA CoreがTensor Coreへ発注したニューラルシェーダ処理スレッドの実行順序も制御できるようになったわけだ。
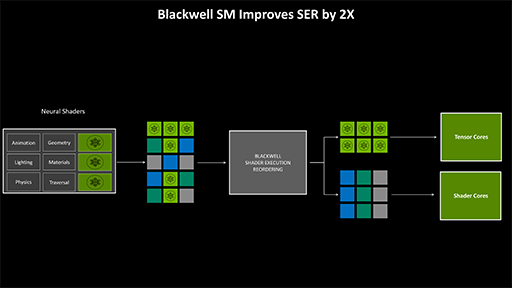 |
これまでにゲームグラフィックス処理系において,Tensor Coreは,ほぼDLSS実行時にしか使われていなかった。DLSSを使わない場合,Tensor Coreはゲームの実行中,ほとんど何もしていない。しかし,Blackwellアーキテクチャをフル活用するニューラルシェーダ時代のゲームグラフィックスにおいては,Tensor Coreの使用頻度が爆上がりする。それこそ,DLSS処理スレッドとニューラルシェーダ処理スレッドが,Tensor Coreを奪い合うようなことも出てくるのだ。
そこで,複数の処理スレッドによるコンフリクト(衝突)を起こさないように,うまく交通整理を行って並列度を上げるためのメカニズムとして,SER 2.0が導入されたのである。
もちろんAda世代のSER 1.0と同様に,SER 2.0も開発者側が専用のAPIを通じて動作を制御してやる必要がある。しかしNVIDIAによれば,すでにSER 1.0を活用したゲームやアプリケーションは,SER 1.0を使っていない場合と比べて,SER 2.0の恩恵をある程度で自動で受けられるそうだ。
ニューラルシェーダの動作支援機能 2
AMP
今どきのGPUは,PC上でさまざまな仕事をこなしている。GPUの本業であるグラフィックス処理も,現在プレイしているゲーム映像の描画と,背後で動いている動画のトランスコード処理のどちらを優先するのがユーザーのためになるかを考えるべきだ。一般的には,リアルタイム性の高いゲーム映像を優先させるべき,というのは想像できると思う。動画のトランスコード速度が10秒遅くなったところで,ユーザーにとってそれほど大きな支障はないからだ。
同様に,NVIDIAが2024年に発表したゲーム向けAI技術「Project G-Assist」のような,AIアシスタントと会話しながらゲームをプレイしているときに,ゲームエンジン側では,グラフィックス処理でニューラルシェーダやDLSS関連を処理していたとする。
どちらもTensor Coreを使った処理系だが,リアルタイム性が高いニューラルシェーダやDLSSの処理に多くのTensor Coreを割り当てるほうが,トータルでのユーザー体験は良くなるはずだ。
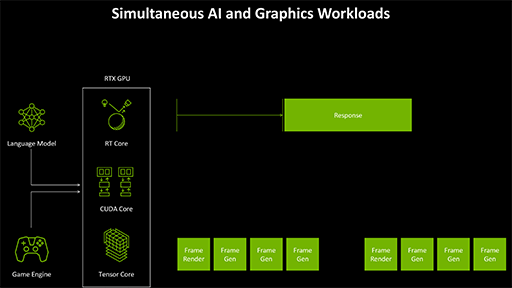
このように,OS上で動作しているさまざまなGPUが処理すべきタスクの交通整理を,GPU内部に組み込んだ「RISC-V」ベースのサブCPUで行う仕組みが,「AI Management Processor」(AMP)である。
 |
 |
SER 2.0と似た機能に思えるが,SER 2.0が担当するのは,GPU内部におけるスレッド実行の交通整理である。一方のAMPは,もう少しシステム側に近い,処理種別やアプリケーション別の交通整理を担当するものだ。
Windowsの場合,Windows 10(バージョン2004)にて,GPUのタスクスケジューリング機構「Hardware-Accelerated GPU Scheduling」(HAGS)が導入された。GeForce系では,Turing世代からGPU内部の専用スケジューラで,HAGSに基づいたスケジューリングを行っていたのだ。しかしHAGSが担当するのは,あくまでもグラフィックス処理系のタスクスケジューリングだけだった。
しかしBlackwellになると,ニューラルシェーダの導入によってTensor Coreを使う曲面が増える。そこで,推論アクセラレータの交通整理が行える独自のGPUタスクスケジューラとして,AMPを実装したのだろう。
ポイントは,AMPがSER 2.0よりも上流で働くという点だ。こうした二段階の交通整理があることで,以下のように緻密な制御が可能になる。
- AMPは,AIアシスタントの会話処理よりも,リアルタイム性の高いゲーム用AIタスクを優先してGPUに入力する
- ゲーム開発者は,SER 2.0を制御して,DLSSのスレッドよりもニューラルシェーダスレッドを優先的にTensor Coreに割り当てる
NVIDIAは,ニューラルシェーダ技術の実現によって,これまで以上にTensor Coreの活用が広がると考えている。ニューラルシェーダ時代に優れた処理効率を維持するためには,こうした高度な実行順制御システムが必要というわけだ。
AIメカニクスをCNNモデルからTransformerモデルへと転換したDLSS
Turing世代のGeForce RTX 20シリーズが登場し,推論アクセラレータであるTensor Coreを活用して超解像処理を行うDLSS技術が登場して以来,瞬く間に多くのPCゲームがこれを用いるようになった。GeForceが,GeForce RTX 30,GeForce RTX 40と世代を改めるごとに,DLSSも,DLSS 2→DLSS 3として進化してきたわけだが,GeForce RTX 50シリーズ登場のタイミングで,新たに発表されたのが「DLSS 4」だ。
DLSS 4の注目すべきポイントを解説していこう。
Turing世代の初代DLSSで処理の根幹となるAIモデルは,開発当時の画像処理系AIで採用事例の多かった「畳み込みニューラルネットワーク」(Convolutional Neural Network,CNN)モデルを採用していた。ところが,AI業界に衝撃をもたらした伝説的な論文「Attention Is All You Need」を,Googleが2017年に発表したことで,業界の方向性は一変する。「Transformer」モデルの登場だ。
その後,Transformerモデルの研究は,AI業界で一気に進み,2020年には,Transformerモデルを採用する大規模言語モデルの代表例となった「ChatGPT 3」が登場した。その後はCG業界でも,ニューラルレンダリング技術においてTransformer技術の応用が進んでいる。
NVIDIAは,Hopper世代のサーバー向けGPU「GH100」で,Transformer技術と相性の良い8bit浮動小数点数(FP8,関連記事)演算が可能な「Transformer Engine」を,Tensor Coreに搭載した。Transformer Engineは,サーバー向けGPUだけでなく,GeForce RTX 40シリーズ以降にも導入済みだ。
このようなAI技術のトレンド変化を踏まえて,NVIDIAは,Blackwellにおいて,DLSSのAIコアをTransformerモデルに刷新した。なぜNVIDIAは,TransformerモデルをDLSSに採用したのだろうか。
Transformerモデルの特徴は,論文のタイトルにもある「Self Attention」(自己注意)にある。Transformerモデルでは,処理対象のコンテキスト全体の中で,注意すべき要素それぞれに重点を置いて,さらに,コンテキストの全体を理解しているように振る舞う性質があるのだ。
 |
この性質が,映像や音声といったコンテンツを処理するのに向いていることも分かってきたため,ChatGPTの開発元であるOpenAIの画像生成系AI「DALL-E」や,楽曲生成系AI「Jukebox」など,コンテンツ生成系AIでの採用が進んだ。とくに画像処理系では,処理対象に含まれる細いものや,塊の識別,動体の前後関係などを,おおむね適切に処理できるので,NVIDIAも「DLSSに採用するしかない」と考えたのであろう。
 |
ほかにも,DLSS以前では時間方向で見ると破線になったり,点滅することも多かった電柱をつなぐ電線,降り注ぐ雨や金網越しの遠景,風に揺らぐ葦(アシ)のような細い葉といった表現も,高品質かつ安定して超解像処理できるようになったそうだ。
 |
TransformerモデルのDLSS 4は,Blackwell専用ではない。「すべてのGeForce RTXシリーズで利用可能になる」と,NVIDIAは述べている。
ただ,Transformerモデルの画像処理系においては,処理速度やグラフィックスメモリの利用効率で,FP8の活用が大きくプラスに働く。そのため,「Transformer Engineを備えるGeForce RTX 40シリーズ以降でこそ,最高の性能を発揮することは間違いない」(NVIDIA)そうだ。
DLSS 4の機能で最も知られているのが,「DLSS Super Resolution」(DLSS SR)で,そのほかにも「Deep Learning Anti-Aliasing」(DLAA)や「DLSS Ray Reconstruction」(DLSS RR)といった機能がある。ゲーム開発者は,DLAAやDLSS RRを,GPUで描画したゲーム映像に適用できる仕組みだ。
 |
DLAAは,処理の根幹はDLSS SRと同じだが,解像度変換(アップスケール)よりも,ネイティブ解像度における時間方向のチラツキや,ジャギーの低減に特化した働きをさせるものへと進化している。
DLSS RRは,ノイズが多く発生したレイトレーシング映像に適用するデノイザの役割を果たす。
拡散反射系の材質に対してレイトレーシングを行うときに,描画した映像のノイズが多く生じることがある。たとえば,1ピクセルあたりに生成したレイの数が不足気味なときや,分岐したレイのトレースが不十分なときに発生しがちだ。DLSS RRは,こうしたノイズを低減できる。
もともと,NVIDIAは,AIベースのデノイザ技術として「NVIDIA OptiX AI-Accelerated Denoiser」を提供済みだが,どちらかと言えばオフラインレンダリング向けのものだった。
一方で,ゲームグラフィックス向けのリアルタイムレイトレーシング向けデノイザとしては,NVIDIAのゲーム開発者向けライブラリ「GameWorks」で「NVIDIA Real-Time Denoisers」(NRD)を提供している。だがこれも,信号処理系アルゴリズムである「Cross Bilateral Filter」(クロスバイラテラルフィルタ)を基盤としたデノイザであり,AI処理とは無関係だ(関連記事)。
DLSS RRは,NVIDIA OptiX AI-Accelerated Denoiserをゲームグラフィックス向けにチューニングして,リアルタイム用途に適したデノイザに改良したものである。
 |
マルチフレーム生成と「Blackwell Flip Metering」の利点
NVIDIAは,GeForce RTX 40シリーズで,GPUで実際に描画するフレームとフレーム(以降,実描画フレーム)の間に,AI処理で中間フレームを生成して疑似的にフレームレートを向上させる技術「DLSS Frame Generation」(DLSSフレーム生成)を導入した。
DLSSフレーム生成は,補間フレーム生成に2つの情報を用いている。
ひとつは,グラフィックスエンジン側が把握している深度情報と,各ポリゴンの動きベクトルを1ピクセル単位に展開した「ベロシティバッファ」(本来はモーションブラーの表現に使う)だ。
もうひとつは,2D映像における1ピクセル単位の動きベクトル「Optical Flow」(オプティカルフロー)である。なお,オプティカルフローは,GeForce GPU内蔵のビデオエンコーダ「NVENC」のサブユニットである「Optical Flow Accelerator」(OFA)で生成するものだ(関連記事)。
 |
DLSS 4では,DLSSフレーム生成アルゴリズムを拡張し,1枚だけだった補間フレームを最大3枚へと増やせるようになった。これにより,フレームレートを疑似的に4倍まで引き上げられるわけだ。これを「DLSS Multi Frame Generation」(DLSS MFG)と呼ぶ。
 |
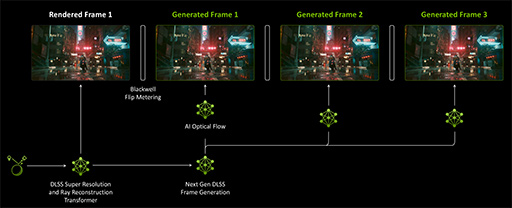 |
DLSS MFGでは,フレーム生成に用いるAIモデルを,Transformerモデルへと変更している。また,生成するフレーム数を3倍にも増やせたのは,Blackwell世代でオプティカルフローの生成をOFAではなく,AI処理系に置き換えたためだ。その結果,Blackwell世代におけるDLSS MFGのフレーム生成レートは,Ada世代に対して40%も速く,メモリ使用量も30%少なくなったという。
2025年2月27日18時頃追記:掲載当初,オプティカルフローの生成に関する説明が誤っていたため,修正いたしました。
DLSS MFGの表示メカニズムには,Blackwellの新機能「Blackwell Flip Metering」が関わっている。
Blackwellでは,DLSS MFGで生成した3枚の補間フレームの表示は,ディスプレイエンジン側にオフロードできるようになった。CPU側で映像表示の指示(フリップ指示)を出す必要はない。DLSS MFGが3枚の補間フレームを生成すると,GPUが実描画フレームを描画にかかった時間(フレームタイム)を4等分した間隔で,ディスプレイエンジン側が,ほぼ自律的に順次表示してくれるわけだ。
 |
この仕組みにより,表示先ディスプレイ側の垂直同期に同期して,補間フレームを表示させることも可能である。
また,フレームレートが乱高下する状況では,せっかく生成した補間フレームのいくつかを表示しきれない場合も出てきそうだ。そうした状況下では,Blackwell Flip Meteringが,表示に間に合わないフレームを破棄すると思われる。
 |
DLSSを間接支援する「Reflex 2」
DLSS系のフレーム生成は,フレームレートを増やせるものの,ゲーム側の処理ループにおけるユーザーの入力を増やすことはない。あくまでも増えるのは映像,しかも補間フレームだけだからだ。
ここで厄介なのは,フレーム生成がゲームプレイにおける操作の遅延を増加させてしまうこと。
とくに深刻な問題は,ゲームにおける視点移動である。プレイヤーが視点を動かす操作をしても,その操作が映像に反映されるのは,次の実描画フレームのタイミングだ。DLSS MFGなどで生成する補間フレームは,あくまでも過去の実描画フレームと最新の実描画フレームまでの間を,滑らかにつないだように見えるように,AIが生成した補間フレームにすぎないからだ。プレイヤーの操作を予測して描画するわけではない。
ある瞬間に視点を動かしても,プレイヤーは,操作が反映された実描画フレームが表示されるまで,AIが生成した補間フレームを見続けているだけだ。
 |
そこで,NVIDIAは,VRゲームにおける遅延感低減に使う技術「タイムワープ処理」(Temporal Reprojection)を,NVIDIA独自の遅延低減技術「NVIDIA Reflex」に導入することで,改善に挑戦した。それが新機能の「NVIDIA Reflex 2」だ。
Reflex 2とは,最新の映像を表示する前に,視点の操作を反映させるメカニズムである。とはいえ,映像そのものはGPUで描画済みなので,最新の視点操作を反映するには,描画済みフレームをスクロールさせて行う。まさに,VRゲームの映像におけるタイムワープ処理(NVIDIAは「フレームワープ」と称する)と同じだ。
次に示す左のスライドは,ある瞬間における頭部の位置をもとに描画した映像だ。しかし,映像描画中にプレイヤーの顔が右に動き続けると,視界は右にずれていく。そこで右のスライドにあるように,動きに合わせて映像をやや左側にスクロールさせて描画する。これがタイムワープの基本だ。移動にともなうスクロール量や,視点移動にともなう投影変換の歪みは,きちんと画像加工により補正する。
 |
 |
この例だと,表示前に映像を左側にスクロールさせたことで,映像の右端には何も表示されない(右スライドで映像がない部分)。一般的なVRゲームにおけるタイムワープ処理では,ここを黒で塗りつぶしてしまうことが多い。VRの場合,映像パネルの外側も黒なので塗りつぶしても目立たないのだが,直視型のディスプレイでは,不自然な表示になってしまう。
そこでReflex 2では,過去フレームやその深度情報などを活用して,スクロールアウトした映像外領域の映像を推測して算術合成する。そして,合成映像で映像外領域を塗りつぶすのだ。NVIDIAは,この処理系を「Inpaint」プロセスと命名している。Inpaintとは,絵画の補修工程を指す英単語だが,言い得て妙な表現である。
 |
 |
 |
なお,映像外領域を埋める推測画像は,AIで生成するのではなく,過去フレームと深度バッファ,ベロシティバッファなどから演算で合成するものだ。実は,2Dゲームや2D映画を,3D立体視映像に変換するときに必要な遮蔽領域の推測では,Inpaintとまったく同じアプローチの技術を採用していた。いうなれば,ロストテクノロジーの再利用といったところか。
Reflex 2のタイムワープ処理とInpaint技術の組み合わせによって,「体感上の遅延を4分の1に減らせる」とNVIDIAは主張している。なかなかすごい効果だ。しかし,あくまでもこの技術で遅延を減らせるのは,視点移動のみ。攻撃操作や,ジャストガード(パリィ)操作などの遅延は,改善できない。
こうした補間フレーム系技術は,30fps未満のゲームに適用してもゲームプレイ感覚の改善にはならない。映像の見た目はスムーズになっても,操作感の遅延は30分の1秒以下のままだからだ。とくにアクションゲームでは,操作の反映が継続的に遅れるような感覚に陥るので,「ゲームが下手になった?」と感じることもあるほど。
逆に,60fps以上で安定的に動いているゲームにおいては,積極的に活用するといいだろう。操作の入力サイクルが安定して60分の1秒以上のサイクルで処理されるので,補間フレーム挿入によって極端な高フレームレートになったとしても,入力は適切に反映されるためだ。
Blackwellのビデオプロセッサとディスプレイエンジン
Blackwellでは,内蔵ビデオプロセッサ,具体的にはエンコーダの「NVENC」とデコーダの「NVDEC」がともに強化された。
まず,ビデオプロセッサのユニット数が増えている。これは,とくに映像制作系クリエイターにはありがたいスペック強化といえよう。Ampere世代以降のGPUにおけるビデオプロセッサの世代と数を表で示そう。
| NVENC | NVDEC | |
|---|---|---|
| GeForce RTX 3090/3080/3070 Ti/3070 | 第7世代×1 | 第5世代×1 |
| GeForce RTX 4090/4080/4070 Ti | 第8世代×2 | 第5世代×1 |
| GeForce RTX 4070 | 第8世代×1 | 第5世代×1 |
| GeForce RTX 5090 | 第9世代×3 | 第6世代×2 |
| GeForce RTX 5080 | 第9世代×2 | 第6世代×2 |
| GeForce RTX 5070 Ti | 第9世代×2 | 第6世代×1 |
| GeForce RTX 5070 | 第9世代×1 | 第6世代×1 |
Blackwellで第9世代となったNVENCは,対応するカラーフォーマットに,YUV422方式が加わった。PCの画面やゲームグラフィックスは,RGB方式のカラーフォーマットで表現することがほとんどだが,カメラで撮影するビデオ映像(≒実写映像)は,歴史的に輝度(Y)と2値からなる色差(青差と赤差)で表現する「YUV」(またはYPbPr)方式を採用する傾向にある。
YUV方式は,人間の視覚システムが敏感な輝度情報をフル解像度で表現して,逆に鈍感なUV(PbPr)を間引いてデータ量を削減しよう,という目的で設計された信号形式だ。YUV422は,輝度情報はフル解像度だが,色情報は2分の1に間引く方式で,プロシューマー系カメラ機器での採用が多いカラーフォーマットである。
BlackwellのNVENCでは,画質とデータ量のバランスが良いYUV422フォーマットを,H.264とH.265のコーデックで使ってエンコードできるようになったわけだ。
また,Ada世代で導入した第8世代NVENCから,「AV1」コーデックでのエンコードには対応していたが,Blackwellの第9世代NVENCでは,AV1の高画質モードである「Ultra High Quality」(UHQ)でのエンコードにも対応した。エンコード速度も速くなり,GeForce RTX 5090のNVENCの性能は,GeForce RTX 3090と比べて4倍も高速になったそうだ。
 |
デコーダであるNVDECも,Blackwellでは第6世代へと進化している。YUV422映像へのデコードに対応しているのはもちろん,H.264のデコード速度が,先代比で2倍も速くなったという。
映像を出力するディスプレイエンジン部は,HDMI 2.1bに加えて,DisplayPort 2.1bに対応したのも見どころだ。
DisplayPort 2.1bは,業界初の1レーンあたり20GbpsのUltra-High Bit Rateモード(UHBR20モード)に対応しており,最大80Gbpsもの伝送帯域幅を実現する。AMDのRadeon RX 7000シリーズもDisplayPort 2.1対応だったが,1レーンあたりの伝送速度は13.5Gbpsまでだったので,その最大帯域幅は54Gbpsだった。
NVIDIAによれば,GeForce RTX 50シリーズは,HDMI 2.1bとDisplayPort 2.1bのどちらも,不可逆圧縮技術の「Display Stream Compression」(DSC)を活用することで,4K解像度なら最大リフレッシュレート480Hz,8K解像度でも最大165Hzまでの映像出力が可能とのことである。
 |
Blackwellが採用したGDDR7は,なぜPAM3になったのか
Blackwell世代のGeForce RTX 50シリーズは,グラフィックスメモリにGDDR7を採用した。GeForce RTX 50シリーズを発表したCES 2025の講演で,NVIDIAのCEOであるJensen Huang(ジェンスン・フアン)氏は,GDDR7メモリとして「Micron Technology(以下,Micron)製を採用した」と述べていた。しかし,講演後に行われたQ&Aセッションでは,Samsung Electronics(以下,Samsung)製と訂正していた。
真相としては,NVIDIA純正のグラフィックスカードである「Founders Edition」には,Samsungを採用していたが,NVIDIA製以外のグラフィックスカードメーカーによっては,Micron製GDDR7メモリを採用することもある,ということのようだ。
本稿執筆時点でのGDDR7メモリは,最大32GHz相当の動作クロックを実現しており,データ転送速度は32Gbps(32GTPS)相当にもなる。このスペックにより,最上位のGeForce RTX 5090ではメモリバス帯域幅が約1.8TB/s,GeForce RTX 5080でも1TB/sに近い,メモリバス帯域幅960GB/sを達成している。
GDDR7において,30GHz前後という超高速駆動を実現できた技術的な理由は,いくつかある。とくに重要なのは,メモリセルのプロセスノードが,GeForce RTX 40シリーズで使っていたGDDR6Xよりも一段階微細になったこと。SamsungやMicronのDRAMプロセスノードの場合,「製造プロセスは何nm」といった具体的な値は公表していない。それでもGDDR6系に対して,GDDR7では20%以上も電力効率が向上して,動作クロックも10GHz前後高くできたわけだ。
GDDR7における動作クロック向上を支えた理由のひとつに,GDDR6Xの「PAM4」から「PAM3」への変更したことが挙げられる。PAMとは「Pulse Amplitude Modulation」の略だ(関連記事)。
GDDR系メモリの場合,GDDR5/GDDR5XやGDDR6では,1クロックあたりのデータ量が1bitの「PAM2」を採用していたが,GDDR6Xでは1クロック当たり2bitに増えたPAM4を採用した。しかしGDDR7では,1クロック当たり1.5bitのPAM3を採用したわけだ。
 |
なぜGDDR7でも,そのままPAM4を採用しなかったのだろうか。たしかにPAM4のほうが,データ伝送効率に優れる。しかし,動作クロックを引き上げることが目的のひとつだったGDDR7では,信号品質の維持が難しくなってしまい,ひいては信頼性が低下するのだ。
さらにPAM4は,PAM3よりも電圧レベルを1段多い形式で表現するため,PAM3よりも電圧を下げにくく,省電力の観点からも望ましくない。結局,総合的なバランスを鑑みて,PAM3の採用となったわけだ。
Blackwellにおける電力制御
Blackwell世代のGeForce RTX 50シリーズは,ゲーム実行時における消費電力(Total Graphics Power,TGP)が,GeForce RTX 40シリーズよりも増大した。ゲーマーにとっては頭の痛い話だが,プロセス世代が同じでプロセッサの規模が微増しているわりには,「よく頑張ってこの程度に抑えましたね」と賞賛する人もいる。
実際,Blackwellでは,NVIDIAのGPU史上,最も徹底した電力制御の見直しを行ったそうだ。
GPUに限らず,半導体プロセッサにおける電力制御のアプローチは,大きく分けて3種類ある。
1つめのアプローチは,GPUの機能ブロックごとに動作クロックを変える「Clock Gating」だ。2つめは,GPUの機能ブロックごとに供給電力を変える「Power Gating」である。
3つめのアプローチは,「Rail Gating」だ。GPUは,同じような機能ブロックごとに,それを動かすための電流値や電圧値が定められているが,そうした電力ドメイン(=電源レール)ごとに,電力を制御する仕組みもある。これがRail Gatingである。Power Gatingよりも広範囲で行う電力制御,というイメージだろうか。
 |
Blackwellでは,Power Gatingを高速かつ多段階に行う制御として使い,Clock Gatingでは,ごく短いアイドル時間においても低遅延に細かく制御する仕組みを導入した。
さらにBlackwellでは,たとえGPUが描画中であっても,GPU負荷に応じて動作クロックを上下させる制御も行っている。これはAda世代までは,行っていなかった制御だ。NVIDIAによれば,動作クロックの上下制御による遅延は,Ada世代までの1000分の1にまで短縮できたので,導入したという。
 |
Clock Gatingは,GDDR7メモリインタフェースにも適用しており,アイドル状態のGDDR7を低遅延で起こせるようになった。Rail Gatingも同様で,GPUとGDDR7メモリのどちらも,供給電力の制御を電源レールごとに行うように進化している。とくに,GPU内で未使用の領域があれば,個別にシャットダウンすることも可能となった。
こうした統合制御により,Blackwellでは,ディープスリープ状態への移行が,Ada世代と比較して10倍も高速になったそうだ。
 |
NVIDIAはBlackwellに,ノートPC向けGPUで使われている「Max-Q Technology」(以下,Max-Q)に相当する制御を,デスクトップPC向けGPUにも導入したとアピールしている。
Max-Qとは,想定する電力と放熱能力の範囲で,最大限の処理性能を提供するという触れ込みの,ノートPC向けGPUにおける高効率電力制御技術だ。Max-QがデスクトップGPUにも導入されたのは,興味深い。
 |
Blackwell世代のGeForce RTX 50シリーズはどんな人に向けたGPUなのか
約2年半ぶりとなるNVIDIA製GPUの刷新で,世界中のPCゲーマーから注目を集めたGeForce RTX 50シリーズ。プロセス世代が据え置かれたこともあり,プロセッサ規模や理論性能値は,先代比で30%前後といったところ。当然,ゲームにおいては,そこまでの性能差は付かない。だから同クラスのGeForce RTX 40シリーズからGeForce RTX 50シリーズへ移行しても,これまでと同じGPUの使い方をする限り,GeForce RTX 30シリーズからGeForce RTX 40シリーズへ移行したときほどの性能向上は,実感できないかもしれない。数々のベンチマークテスト結果でも,その傾向は裏付けられている。
しかし,技術的な視点では注目すべき点が非常に多い。こうして,長い解説記事を書き上げて感じたのは,GeForce RTX 50シリーズの真の実力が解放されるのは,前編で扱った「Mega Geometry」や,今回扱ったニューラルシェーダ,DLSS 4の本格的な活用が始まってからではないか,ということだ。
Mega Geometryをゲームスタジオ独自のグラフィックスエンジンへ組み込むのは,難度が高そうだ。しかし,技術的な背景を考えると,「Unreal Engine 5」へはすぐに対応してきそうなので,比較的,早いうちに恩恵を体感できるような気はしている。
だが,ニューラルシェーダの本格的な活用が始まるのは,DirectXが対応してからになるだろう。基本的にニューラルシェーダは,推論アクセラレータ搭載のGPUであれば利用できるようなので,DirectXが対応してくれれば,一部の材質表現で用いるゲームは,すぐに出てきそうではある。とはいえ,レイトレーシング並みに多くのゲームタイトルが活用するようになるのは,ゲーム機がニューラルシェーダに対応してからだろう。具体的には,次世代PlayStationや次世代Xboxの登場後だろうか。
DLSS 4は,グラフィックスエンジンへの実装難度自体に,これまでのDLSS 3と大きな違いはないようなので,既存ゲームへのアップデートを含めて,比較的,早く対応タイトルが増えてくるのではないかと予想している。
関連記事
西川善司の3DGE:GeForce RTX 50完全解説前編 Blackwell世代の構造とレイトレーシングにおける革新
Blackwell世代のGPU「GeForce RTX 50」シリーズは,製造プロセスこそ前世代と変わらないが,内部はゲームの性能にも関わるさまざまな改良が施されていた。NVIDIAが明らかにした詳細情報をもとに,前後編でGeForce RTX 50シリーズの全貌に迫ってみよう。
NVIDIAのGeForce RTX 50シリーズ製品情報ページ
- 関連タイトル:GeForce RTX 50
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー