









ニュース
次世代のノートPC向けCPU「Meteor Lake」の詳細が明らかに。メインのCPUコアを使わずに動画を再生できる!?
Intelは,ノートPC向けの次世代プロセッサとなる開発コードネーム「Meteor Lake」を,2023年後半に市場へ投入する。Meteor Lakeは,すでに量産に入っており,その様子を4Gamerでもレポート済みだ。
Meteor LakeについてIntelは,「過去40年において,もっとも大きなアーキテクチャ上の変革である」と,繰り返しアピールしている。現在のx86系CPUの基礎となったIA-32命令セットを実装した初のプロセッサ「Intel 80386DX」が1985年,つまり今から37年前に誕生しているので,それ以来の変革といった意味だろうか。
そんなMeteor Lakeに詰め込まれている新しい技術の概要を,Intelは,米国時間2023年9月19日からカリフォルニア州サンノゼでスタートした独自イベント「Intel Innovation」に合わせて公開した。ただ,製品名や製品構成(いわゆるSKU),具体的な性能といったことはまだ明らかになっていない。
そこで本稿では,Meteor Lakeに投入された技術についてまとめてみよう。
Intelが過去40年における最大の変革というように,Meteor LakeはこれまでのIntel製CPUとは大きく異なる製品となっている。最大の特徴は,CPUが4つのチップで構成されている点だ。
IntelのノートPC向けCPUは,第5世代Coreプロセッサ(開発コードネーム:Broadwell)以降,CPUやGPU,メモリコントローラなどを実装したチップと,USBなど周辺I/Oを集積したPlatform Controller Hub(PCH)と呼ばれるチップを,ベース基板上に載せたMulti-Chip Module(MCM)構成を採用してきている。
だが,Meteor Lakeでは,Intelが長年にわたって研究開発を続けてきた,チップ間を超高速かつ低消費電力で結ぶ「Embedded Multi-die Interconnect Bridge」(EMIB)技術と,チップを積層させるパッケージング技術「Foveros」(フォベロス)を融合させてチップ間を密に結合することで,従来とは大きく異なるチップの分割を行っている。ここがMeteor Lakeにおけるまったく新しい点と考えていいだろう。
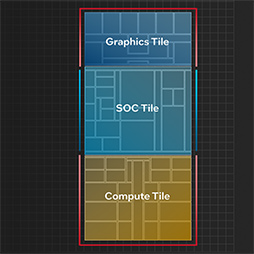
実際のMeteor Lakeは,CPUコア群を集積した「Compute tile」,GPUを集積した「Graphics tile」,「Uncore」と呼ばれてきた周辺機能のうち,メモリコントローラやAI処理向けアクセラレータ,無線LAN機能などを集積する「SoC tile」,そしてPCI Express(以下,PCIe)やThunderboltのインタフェースを集積した「IO tile」という4種類のチップで構成される。
ちなみにAMDは,第2世代RyzenのZen+アーキテクチャ以降,CPUを集積したCPU Complex Die(CCD)と,メモリコントローラやI/Oを集積したIO Die(IOD)という2種類のチップをひとつのパッケージに搭載している。AMDは,複数のチップ(Chiplet)で構成する設計を,チップレットアーキテクチャと呼んでいる。
だがIntelは,チップのことをタイル(tile)と呼び,タイルアーキテクチャ(tile Architecture)と呼んでおり,チップレットという言葉は使っていない。
AMDは,RyzenをCCDとIODという2つで構成しているのに対して,Meteor Lakeでは細分化を進め,4つに分割しているのが大きな特徴といえるだろう。Meteor Lakeでなぜこの4つにチップを分割したのか,Intelは詳しく解説している。
次のスライドは,第13世代Coreプロセッサ(開発コードネーム:Raptor Lake)まで採用してきたIntelプロセッサのざっくりとした構成を示したものだ。
Intelのプロセッサは,第5世代あたりからスライドのような構成を取ってきているのだが,いろいろな課題が出ていたそうだ。たとえば,ディスプレイの高解像度化やPCIeおよびUSBの高速化により,「IO Fabric」に要求される帯域性能が拡大している。しかし,これまでのアーキテクチャでは,IO Fabricの帯域拡大が難しくなっていたと,Intelは述べている。
また,メディア再生に関わる電力消費も,問題のひとつであったそうだ。従来のアーキテクチャでは,GPU側にメディアのエンコードとデコードを行う機能を配置していた。そのため,メディア再生時には,CPUとGPUを相互に接続している「Ring Fabric」を駆動する必要があり,無駄な電力を消費する結果になっていたという。
メディア再生のように,特定ワークロードを実行するために必要な電力を最小化するためには,プロセッサ全体の再設計が必要だったと,Intelは主張する。その再設計にあたって,SoCの拡張性(スケーラビリティ)も重視したとのことだ。というのも,従来の設計は,スケーラビリティも限界に達しつつあったからである。
というわけで,Meteor Lakeでは前出の4つのタイルに分割されたわけだ。次のスライドは,Meteor Lakeのブロック図だ。
ここで重要なのは,従来はGPUに組み込まれていたメディアブロックが,SoC tileに移動したことだ。これにより,消費電力を抑えづらいCPUやGPUのブロックをメディア再生時にあまり使わないようにできるので,電力効率が向上するという。
さらにSoC tileでは,新たな要素としてAIアクセラレータである「Neural network Processing Unit」(NPU)と,省電力プロセッサコア「E-core」が2基(LP E-core)組み込まれている点も大きな特徴だ。
また,SoC tileの内部には,2つの大きな内部バス(ファブリック)がある。「Network-On-Chip Fabric」(NOCファブリック)は,広い帯域幅を必要とする機能ブロックを結ぶ,一種の高速道路のようなものだ。
Intelによると,NOCファブリックは,「システムメモリと同じ帯域幅を持つスケーラブルなファブリック」だそうだ。帯域幅と同時にキャッシュコヒーレンシを維持するための機能などを持っているという。
たとえば,ある機能ブロックが読み取りのリクエストを発行すると,それをNOCファブリック内のエージェントが受け取り,Meteor Lakeを構成するブロックのどこかにデータがキャッシュされていればそれを読み,キャッシュされていなければメモリコントローラを駆動してメモリから読む,といった動作を一手に引き受ける。
一方,PCIeやUSB,ストレージといったI/Oは,NOCファブリックから「IO Controller」(IOC)という機能ブロックを介して,I/Oを束ねるIO Fabricに含まれている。一見すると,Meteor LakeではI/Oがボトルネックになりそうだが,Intelによると,IOCがI/Oに対するリクエストの順序付けなどを行うことで,効率的なI/O利用が可能になっているそうだ。
Meteor Lakeでは,なぜIO tileが独立しているのかと疑問に思う読者もいるかもしれない。「PCIeやThunderboltインタフェースは,SoC tileに組み込めばいいのでは」と思うだろう。Intelによると,IO tileを独立させた理由は,主に2つあるそうだ。ひとつは,単純にスペース上の問題。SoC tileにI/Oを集約して3つのタイルにすると,PCIeを引き出すスペースが取れないという問題があるという。
もうひとつ,IO tileを独立させると,SKUに応じてその規模を変えられるという利点があるそうだ。つまりMeteor Lakeでは,PCIeやThunderboltのレーン数を減らしたSKUとして,異なるIO tileを使う製品が登場する可能性が高いだろう。
ところで,Meteor Lakeで気がかりなのは,4つのタイルに分割したことによるオーバーヘッドの増加ではないだろうか。この点を補強するのが,Meteor Lakeで初めてコンシューマー向けのCPUに応用される3Dパッケージング技術Foverosだ。
Foverosでは,シリコンで形成した回路基板(Si Interposer)上にチップ――Meteor Lakeではtile――を取り付けてプロセッサを構成する。各タイルとSi Interposerを結合するバンプ(端子)ピッチは,36μmと極めて高密度で,1bitあたり0.3pJ(ピコジュール)という極めて小さな電力で,超高速なインタフェースを形成できるそうだ。
それでもタイル間のインタフェースによるオーバーヘッドはあるが,IntelによるとMeteor Lakeの性能に占めるオーバーヘッドの割合は,「わずか1%に留まる」そうだ。したがって,タイルに分割するメリットのほうが大きいという。
なお,4つのタイルのうちCompute tileは,初採用となる新開発のプロセス技術「Intel 4」で製造される。Intel 4は,TSMCの製造プロセスでいうとTSMC N4クラスの製造技術のようで,おおむねノード長は4〜5nmの製造プロセスだ。Intelとして初めてEUV(極紫外線)を用いるのが,Intel 4の特徴である。
Intelによると,Intel 4の製造は順調に立ち上がっており,極めて優れた特性を実現できているという。EUVの利用により,現在主力のIntel 7に比べて製造工数を大幅に削減できているほか,面積効率は最大2倍,プロセッサの電力効率は最大20%の向上を見せたと,Intelはアピールしている。
Meteor LakeにおいてIntelが製造するタイルは,Compute tileのみ。残る3つのタイルは,TSMCが製造するそうだ。Graphics tileは「TSMC N5」,IO tileとSoC tileは「TSMC N6」で製造されるとのことだった。
RyzenでChiplet Architectureを採用したときに,AMDが述べていたように,タイルごとに必要とされるトランジスタの特性や動作電圧域は異なるので,それぞれに適した製造プロセスが利用できるというのも,チップを分割する利点であると,Intelも主張している。Graphics tileやIO tile,SoC tileにTSMCの製造プロセスを活用するのも,それぞれに適したプロセスを選択した結果ということだろう。
Meteor Lakeでまず目を惹くのが,SoC tile内に2基のLP E-coreが実装されたことではないだろうか。
Meteor Lakeでは,Compute tileに実装されている高性能なP-coreと省電力のE-coreに加えて,SoC tile内にもっとも省電力なCPUコアとなるLP E-coreがあるという3段階のCPUコア構成になっている。これをIntelは,「3D Performance Hybrid Architecture」と呼ぶ。
P-coreとE-coreのCPUアーキテクチャも,Raptor Lakeから更新された。Meteor LakeのP-coreには「Redwood Cove」が使用され,E-coreには「Crestmont」が使用されるという。
Redwood Coveは,Raptor LakeのP-coreで採用された「Raptor Cove」の改良版だ。帯域幅の改善や電力性能の向上が図られた。ただ,Redwood Coveの性能面について,具体的な情報は明らかになっていない。
一方のCrestmontは,Raptor Lake世代のE-coreである「Gracemont」から大きく改良されており,AI向けの「Vector Neural Network Instruction」(VNNI)命令などの性能の向上が図られたとのこと。これにより,Gracemontと比較してクロックあたりの性能が4〜6%向上しているそうだ。
SoC tileに集積されている2コアのE-coreも,Crestmontアーキテクチャだが,Compute tileのE-coreに比べ動作クロックが抑えられているなど,より低消費電力に振った設計になっている。そのためIntelは,SoC tileのE-coreをLP(Low Power) E-coreと呼んでいるわけだ。
IntelはMeteor Lakeで,OSに対してCPUコアの状況を通知してスレッドのスケジューリングを行うヒントをフィードバックする「Thread Director」を改良し,CPUパワーを必要としないバックグラウンドタスクをできるだけLP E-coreに割り当てるよう,OSのスケジューラに情報を渡すことで低消費電力化を図っている。
Thread Directorには「クラス」という概念があり,「Class 3」がCPUを最も必要としない状態だ。Class 3に分類されたスレッドは,Meteor LakeではLP E-coreに割り当てられる。
Raptor Lakeでは,まずP-coreにスレッドを割り当て,高いCPU性能を必要としないようならE-coreに移して,定期的にP-coreに移して負荷状況を調節する。つまりP-coreをできるだけ使う設計だ。一方,Meteor Lakeでは,まずLP E-coreにスレッドを割り当て,必要に応じてCompute tile側のE-coreかP-coreへ移すという動作になるそうだ
ワークロードによっては,Compute tileをまったく必要としないケースもあるだろう。実際にIntelは,SoC tileだけで動画を再生するというデモを披露している。メディアブロックをGPUからSoC tileに移しているので,動画の再生程度ならCompute tileだけでなく,Graphics tileも必要としないわけだ。
Intelは,Microsoftと協力して,Windows 11のMeteor Lake対応を進めているとのこと。SoC tileのLP E-coreを活用した低消費電力化や,ノートPCにおけるACアダプターとバッテリー動作の最適化が,すでに行われているそうだ。3D Performance Hybrid Architectureによって,どの程度の省電力化が実現できるかは実際の製品が登場しないとはっきりしないが,Meteor Lakeの新たな要素として覚えておこう。
Meteor Lakeにおける新要素のひとつに,NPUがある。
Intelは,これまでもXeアーキテクチャのGPUがサポートする符号付き整数の行列積和算命令「DP4a」や,Alder Lake以降のCPUで対応したAI向けの整数積和命令セット「VNNI」といった,AI向けの改良を行ってきた。だが,AI専用アクセラレータをCPU製品に組み込むのは,Meteor LakeにおけるNPUが初めてだ。
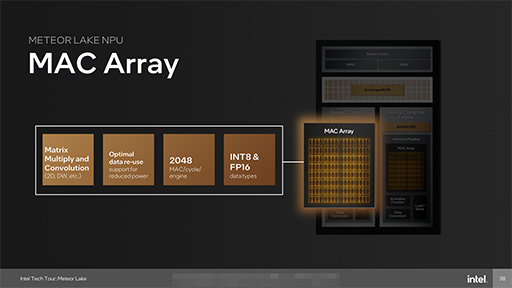
Meteor LakeのNPUには,2基の「Neural Compute Engine」が組み込まれており,大まかな構成は以下のスライドのとおり。
Neural Compute Engineで,最も大きな部分を構成するのが「MAC Array」という演算器のクラスタだ。ニューラルネットワーク向け演算のほとんどは,行列の乗算で構成されるので,MAC Arrayはそれを処理する演算器のクラスタと理解していい。
IntelによるとMAC Arrayと活性化関数(Activation Function)および畳み込み(Convolution)のアクセラレータによりAIの推論パイプラインを構成できるという。
2基のNeural Compute Engineは,DMAでアクセス可能な高速なSRAMからなるスクラッチパッドメモリ(Scratchpad RAM)とデータをやり取り可能だ。ニューラルネットワークの処理にかかる時間は,NPUにAIモデルをコンパイルする時点で計算できる。そこで,スクラッチパッドメモリとのやり取りをDMAを使ってバックエンドで行えるように,あらかじめスケジュールを決めることで,ニューラルネットワーク処理を高速に実行できるわけだ。これは,AMDのAIアクセラレータにも見られる仕様である。
ちなみに,NPUのベースとなっているのは,「Movidius Myriad Vision Processing Unit」(以下,Myriad VPU)だそうだ。これは,AI向けアクセラレータを手がけていたアイルランドのベンチャー企業であるMovidius(モビディウス)が開発したものだ。
2016年にIntelがMovidiusを買収したのち,Myriad VPUのアーキテクチャを受け継ぐAI向けのアクセラレータ製品は,Intelが発売していた(関連記事)。そんなVPUの最新版が,Meteor LakeにNPUという形で組み込まれたと理解していい。
各Neural Compute Engineは「SHAVE DSP」という演算器を備えている。これもMyriad VPUが備えていたSHAVEプロセッサと同じ働きをする演算器で,センサーや画像の処理に利用できる。
NPUの性能指標,たとえば何TOPSであるとかいうような指標は,Intelが明言していないのだが,興味深い利用例を提示している。画像生成AIの「Stable Diffusion」において,GPUのみを使用するよりも,NPUとGPUを併用したほうが電力効率と性能が大幅に向上するという。
Stable Diffusionは,ノイズからそれっぽい画像を引き出す「UNet+」というAIモデルと,粗い画像を綺麗な画像を仕上げる「Variable Auto Decoder」(VAE),そしてテキストを解釈する「Text Encoder」という複数のAIモデルを組み合わせて画像を生成している。Intelによると,それぞれのモデルをNPU,GPU,CPUに分散させることで性能と電力効率を向上させられるそうだ。
NPUは,Windowsにおいては「Windows Machine Learning」(WinML)や「DirectML」,「ONNX Runtime」(ONNX RT)といった業界標準のライブラリやAPIをサポートするほか,Intelが地道に開発を続けていた独自ライブラリ「OpenVINO」をサポートするそうだ。OpenVINOは地味に続いていたので,Meteor Lakeとともにメジャーデビューするとなれば,いろいろな意味で感慨深い。
Intelは,このNPUによって「AIを民主化する」とアピールしている。クラウドで実行するのが当たり前だったAI処理を,クライアント側で高いセキュリティを保ったまま利用できるようにすると約束している。そのため,Meteor Lakeが市場に登場するまでに間に合うように,多数のAIモデルをNPUに移植しているそうだ。
移植しているAIモデルの中には,Metaが公開している大規模言語モデル「LLaMA v2」など,これまでは多量のメモリを積んだGPUがないと利用するのが難しいAIモデルもリストアップされているので,期待したいところだ。
Meteor LakeのNPUや,AMDがAPU製品に組み込んだ「Ryzen AI」といった,新登場のAIアクセラレータは,WinMLやDirectMLに代表される標準的なライブラリやAPIを活用する。AI処理を用いるWindows用アプリケーションは,これらのライブラリやAPIを利用するのが標準になっていくだろう。
これまでは,AIを利用するならCUDAに対応するNVIDIA製のGPUが必要という状況だったのだが,少なくともクライアントPC上でAIの推論を利用するアプリに限れば,NVIDIA製のGPUは必ずしも必要ないという方向になるかもしれない。Meteor Lakeの「AIを民主化」に期待したいところだ。
Meteor Lakeにおけるそれ以外のポイントも,簡単に押さえておこう。
Graphics tileのGPUは,現行世代の統合型グラフィックス機能(以下,iGPU)である「Iris Xe Graphics」で使われた「Xe LP」から,Meteor Lakeで「Xe LPE」に刷新される。
Xe LPEは,「Intel Arc A」シリーズGPUに実装されているXe-HPGに近いアーキテクチャを採用しており,2基のRender Sliceで構成されているそうだ。ひとつのRender Sliceは,4基のXe Coreで構成され,演算ユニットであるVector Engineの総数は128基となる。これは現行のXe LP比で,1.33倍の規模だ。
新GPUでは高い性能が期待できるだけでなく,Xe HPGと同様のレイトレーシングユニットを8基内蔵しているため,「DirectX 12 Ultimate」に完全に対応できるGPUになると,Intelは予告している。現行のXe LPでも,グラフィックス負荷の軽いゲームならフルHD解像度でプレイ可能と言われているので,Meteor Lakeならば,快適にプレイできるゲームがさらに増えるはずだ。
メディアブロックやディスプレイブロックは,すでに述べたようにSoC tile側に移されているが,これらにもXeの名称が与えられている。メディアブロックが「Xe Media Engine」,ディスプレイブロックは「Xe Display Engine」だ。また,これまでのXe Media Engineと同様に,Meteor Lakeでも「AV1」コーデックのハードウェアデコードおよびハードウェアエンコードに対応するという。
SoC tileに,「Wi-Fi 7」対応の無線LAN機能が統合されるのもポイントだ。
Wi-Fi 7は,Wi-Fi 6で160MHzだった帯域を,最大320MHzと倍増させることで広帯域化を計る新しい無線LANの規格である。また,マルチリンク機能によって,ゲームで重要なレイテンシも最大60%低減可能など,ゲーマーにとっても期待できる規格だ。
残念ながら,日本では法規制の関係でWi-Fi 7の認可がすぐに行える状況になく,2024年中に使えるかどうか,という状況らしい。そのため,Meteor Lake搭載ノートPCが2023年に登場しても,Wi-Fi 7がすぐに使えるようにはならない。とはいえ,将来的には使えるようになる可能性もあるので,Meteor LakeがWi-Fi 7に対応しているということは,覚えておくといいだろう。
今回明らかにならなかったMeteor Lakeの性能に関しては,製品のリリースまでに,新たな情報を公開するとIntelは予告している。続報にも期待したい。
 |
Meteor LakeについてIntelは,「過去40年において,もっとも大きなアーキテクチャ上の変革である」と,繰り返しアピールしている。現在のx86系CPUの基礎となったIA-32命令セットを実装した初のプロセッサ「Intel 80386DX」が1985年,つまり今から37年前に誕生しているので,それ以来の変革といった意味だろうか。
そんなMeteor Lakeに詰め込まれている新しい技術の概要を,Intelは,米国時間2023年9月19日からカリフォルニア州サンノゼでスタートした独自イベント「Intel Innovation」に合わせて公開した。ただ,製品名や製品構成(いわゆるSKU),具体的な性能といったことはまだ明らかになっていない。
そこで本稿では,Meteor Lakeに投入された技術についてまとめてみよう。
1つのプロセッサを4つのシリコンダイで構成するMeteor Lake
Intelが過去40年における最大の変革というように,Meteor LakeはこれまでのIntel製CPUとは大きく異なる製品となっている。最大の特徴は,CPUが4つのチップで構成されている点だ。
 |
IntelのノートPC向けCPUは,第5世代Coreプロセッサ(開発コードネーム:Broadwell)以降,CPUやGPU,メモリコントローラなどを実装したチップと,USBなど周辺I/Oを集積したPlatform Controller Hub(PCH)と呼ばれるチップを,ベース基板上に載せたMulti-Chip Module(MCM)構成を採用してきている。
だが,Meteor Lakeでは,Intelが長年にわたって研究開発を続けてきた,チップ間を超高速かつ低消費電力で結ぶ「Embedded Multi-die Interconnect Bridge」(EMIB)技術と,チップを積層させるパッケージング技術「Foveros」(フォベロス)を融合させてチップ間を密に結合することで,従来とは大きく異なるチップの分割を行っている。ここがMeteor Lakeにおけるまったく新しい点と考えていいだろう。
実際のMeteor Lakeは,CPUコア群を集積した「Compute tile」,GPUを集積した「Graphics tile」,「Uncore」と呼ばれてきた周辺機能のうち,メモリコントローラやAI処理向けアクセラレータ,無線LAN機能などを集積する「SoC tile」,そしてPCI Express(以下,PCIe)やThunderboltのインタフェースを集積した「IO tile」という4種類のチップで構成される。
 |
 |
 |
 |
ちなみにAMDは,第2世代RyzenのZen+アーキテクチャ以降,CPUを集積したCPU Complex Die(CCD)と,メモリコントローラやI/Oを集積したIO Die(IOD)という2種類のチップをひとつのパッケージに搭載している。AMDは,複数のチップ(Chiplet)で構成する設計を,チップレットアーキテクチャと呼んでいる。
だがIntelは,チップのことをタイル(tile)と呼び,タイルアーキテクチャ(tile Architecture)と呼んでおり,チップレットという言葉は使っていない。
AMDは,RyzenをCCDとIODという2つで構成しているのに対して,Meteor Lakeでは細分化を進め,4つに分割しているのが大きな特徴といえるだろう。Meteor Lakeでなぜこの4つにチップを分割したのか,Intelは詳しく解説している。
次のスライドは,第13世代Coreプロセッサ(開発コードネーム:Raptor Lake)まで採用してきたIntelプロセッサのざっくりとした構成を示したものだ。
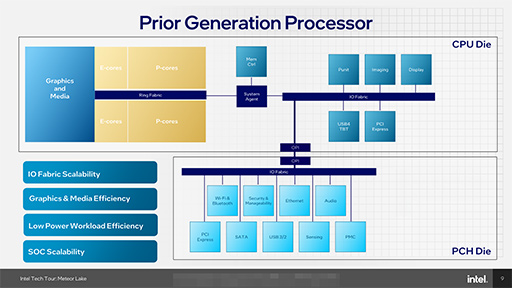 |
Intelのプロセッサは,第5世代あたりからスライドのような構成を取ってきているのだが,いろいろな課題が出ていたそうだ。たとえば,ディスプレイの高解像度化やPCIeおよびUSBの高速化により,「IO Fabric」に要求される帯域性能が拡大している。しかし,これまでのアーキテクチャでは,IO Fabricの帯域拡大が難しくなっていたと,Intelは述べている。
また,メディア再生に関わる電力消費も,問題のひとつであったそうだ。従来のアーキテクチャでは,GPU側にメディアのエンコードとデコードを行う機能を配置していた。そのため,メディア再生時には,CPUとGPUを相互に接続している「Ring Fabric」を駆動する必要があり,無駄な電力を消費する結果になっていたという。
メディア再生のように,特定ワークロードを実行するために必要な電力を最小化するためには,プロセッサ全体の再設計が必要だったと,Intelは主張する。その再設計にあたって,SoCの拡張性(スケーラビリティ)も重視したとのことだ。というのも,従来の設計は,スケーラビリティも限界に達しつつあったからである。
というわけで,Meteor Lakeでは前出の4つのタイルに分割されたわけだ。次のスライドは,Meteor Lakeのブロック図だ。
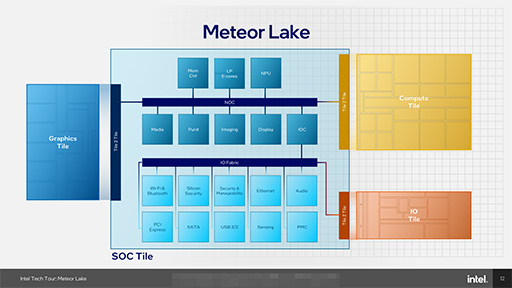 |
ここで重要なのは,従来はGPUに組み込まれていたメディアブロックが,SoC tileに移動したことだ。これにより,消費電力を抑えづらいCPUやGPUのブロックをメディア再生時にあまり使わないようにできるので,電力効率が向上するという。
さらにSoC tileでは,新たな要素としてAIアクセラレータである「Neural network Processing Unit」(NPU)と,省電力プロセッサコア「E-core」が2基(LP E-core)組み込まれている点も大きな特徴だ。
また,SoC tileの内部には,2つの大きな内部バス(ファブリック)がある。「Network-On-Chip Fabric」(NOCファブリック)は,広い帯域幅を必要とする機能ブロックを結ぶ,一種の高速道路のようなものだ。
Intelによると,NOCファブリックは,「システムメモリと同じ帯域幅を持つスケーラブルなファブリック」だそうだ。帯域幅と同時にキャッシュコヒーレンシを維持するための機能などを持っているという。
たとえば,ある機能ブロックが読み取りのリクエストを発行すると,それをNOCファブリック内のエージェントが受け取り,Meteor Lakeを構成するブロックのどこかにデータがキャッシュされていればそれを読み,キャッシュされていなければメモリコントローラを駆動してメモリから読む,といった動作を一手に引き受ける。
一方,PCIeやUSB,ストレージといったI/Oは,NOCファブリックから「IO Controller」(IOC)という機能ブロックを介して,I/Oを束ねるIO Fabricに含まれている。一見すると,Meteor LakeではI/Oがボトルネックになりそうだが,Intelによると,IOCがI/Oに対するリクエストの順序付けなどを行うことで,効率的なI/O利用が可能になっているそうだ。
Meteor Lakeでは,なぜIO tileが独立しているのかと疑問に思う読者もいるかもしれない。「PCIeやThunderboltインタフェースは,SoC tileに組み込めばいいのでは」と思うだろう。Intelによると,IO tileを独立させた理由は,主に2つあるそうだ。ひとつは,単純にスペース上の問題。SoC tileにI/Oを集約して3つのタイルにすると,PCIeを引き出すスペースが取れないという問題があるという。
 |
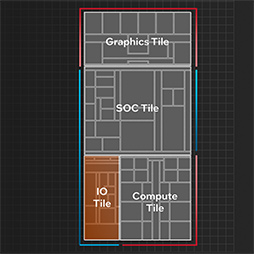 |
もうひとつ,IO tileを独立させると,SKUに応じてその規模を変えられるという利点があるそうだ。つまりMeteor Lakeでは,PCIeやThunderboltのレーン数を減らしたSKUとして,異なるIO tileを使う製品が登場する可能性が高いだろう。
 |
ところで,Meteor Lakeで気がかりなのは,4つのタイルに分割したことによるオーバーヘッドの増加ではないだろうか。この点を補強するのが,Meteor Lakeで初めてコンシューマー向けのCPUに応用される3Dパッケージング技術Foverosだ。
Foverosでは,シリコンで形成した回路基板(Si Interposer)上にチップ――Meteor Lakeではtile――を取り付けてプロセッサを構成する。各タイルとSi Interposerを結合するバンプ(端子)ピッチは,36μmと極めて高密度で,1bitあたり0.3pJ(ピコジュール)という極めて小さな電力で,超高速なインタフェースを形成できるそうだ。
 |
それでもタイル間のインタフェースによるオーバーヘッドはあるが,IntelによるとMeteor Lakeの性能に占めるオーバーヘッドの割合は,「わずか1%に留まる」そうだ。したがって,タイルに分割するメリットのほうが大きいという。
なお,4つのタイルのうちCompute tileは,初採用となる新開発のプロセス技術「Intel 4」で製造される。Intel 4は,TSMCの製造プロセスでいうとTSMC N4クラスの製造技術のようで,おおむねノード長は4〜5nmの製造プロセスだ。Intelとして初めてEUV(極紫外線)を用いるのが,Intel 4の特徴である。
Intelによると,Intel 4の製造は順調に立ち上がっており,極めて優れた特性を実現できているという。EUVの利用により,現在主力のIntel 7に比べて製造工数を大幅に削減できているほか,面積効率は最大2倍,プロセッサの電力効率は最大20%の向上を見せたと,Intelはアピールしている。
 |
Meteor LakeにおいてIntelが製造するタイルは,Compute tileのみ。残る3つのタイルは,TSMCが製造するそうだ。Graphics tileは「TSMC N5」,IO tileとSoC tileは「TSMC N6」で製造されるとのことだった。
RyzenでChiplet Architectureを採用したときに,AMDが述べていたように,タイルごとに必要とされるトランジスタの特性や動作電圧域は異なるので,それぞれに適した製造プロセスが利用できるというのも,チップを分割する利点であると,Intelも主張している。Graphics tileやIO tile,SoC tileにTSMCの製造プロセスを活用するのも,それぞれに適したプロセスを選択した結果ということだろう。
SoC tileのLP E-coreを活用して電力性能を大幅に引き上げる
Meteor Lakeでまず目を惹くのが,SoC tile内に2基のLP E-coreが実装されたことではないだろうか。
 |
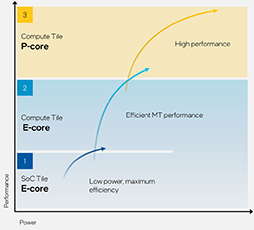 |
P-coreとE-coreのCPUアーキテクチャも,Raptor Lakeから更新された。Meteor LakeのP-coreには「Redwood Cove」が使用され,E-coreには「Crestmont」が使用されるという。
Redwood Coveは,Raptor LakeのP-coreで採用された「Raptor Cove」の改良版だ。帯域幅の改善や電力性能の向上が図られた。ただ,Redwood Coveの性能面について,具体的な情報は明らかになっていない。
 |
一方のCrestmontは,Raptor Lake世代のE-coreである「Gracemont」から大きく改良されており,AI向けの「Vector Neural Network Instruction」(VNNI)命令などの性能の向上が図られたとのこと。これにより,Gracemontと比較してクロックあたりの性能が4〜6%向上しているそうだ。
 |
SoC tileに集積されている2コアのE-coreも,Crestmontアーキテクチャだが,Compute tileのE-coreに比べ動作クロックが抑えられているなど,より低消費電力に振った設計になっている。そのためIntelは,SoC tileのE-coreをLP(Low Power) E-coreと呼んでいるわけだ。
IntelはMeteor Lakeで,OSに対してCPUコアの状況を通知してスレッドのスケジューリングを行うヒントをフィードバックする「Thread Director」を改良し,CPUパワーを必要としないバックグラウンドタスクをできるだけLP E-coreに割り当てるよう,OSのスケジューラに情報を渡すことで低消費電力化を図っている。
Thread Directorには「クラス」という概念があり,「Class 3」がCPUを最も必要としない状態だ。Class 3に分類されたスレッドは,Meteor LakeではLP E-coreに割り当てられる。
Raptor Lakeでは,まずP-coreにスレッドを割り当て,高いCPU性能を必要としないようならE-coreに移して,定期的にP-coreに移して負荷状況を調節する。つまりP-coreをできるだけ使う設計だ。一方,Meteor Lakeでは,まずLP E-coreにスレッドを割り当て,必要に応じてCompute tile側のE-coreかP-coreへ移すという動作になるそうだ
 |
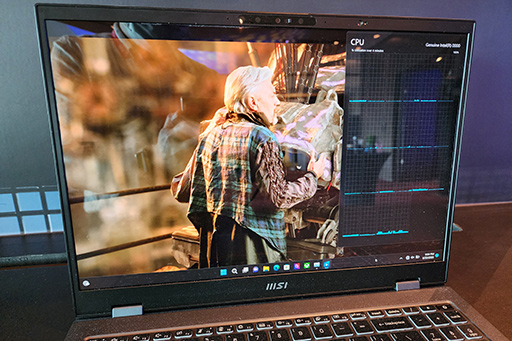
ワークロードによっては,Compute tileをまったく必要としないケースもあるだろう。実際にIntelは,SoC tileだけで動画を再生するというデモを披露している。メディアブロックをGPUからSoC tileに移しているので,動画の再生程度ならCompute tileだけでなく,Graphics tileも必要としないわけだ。
 |
Intelは,Microsoftと協力して,Windows 11のMeteor Lake対応を進めているとのこと。SoC tileのLP E-coreを活用した低消費電力化や,ノートPCにおけるACアダプターとバッテリー動作の最適化が,すでに行われているそうだ。3D Performance Hybrid Architectureによって,どの程度の省電力化が実現できるかは実際の製品が登場しないとはっきりしないが,Meteor Lakeの新たな要素として覚えておこう。
ノートPCで生成AIが使えるようになる? Meteor LakeのNPU
 |
Intelは,これまでもXeアーキテクチャのGPUがサポートする符号付き整数の行列積和算命令「DP4a」や,Alder Lake以降のCPUで対応したAI向けの整数積和命令セット「VNNI」といった,AI向けの改良を行ってきた。だが,AI専用アクセラレータをCPU製品に組み込むのは,Meteor LakeにおけるNPUが初めてだ。
Meteor LakeのNPUには,2基の「Neural Compute Engine」が組み込まれており,大まかな構成は以下のスライドのとおり。
 |
Neural Compute Engineで,最も大きな部分を構成するのが「MAC Array」という演算器のクラスタだ。ニューラルネットワーク向け演算のほとんどは,行列の乗算で構成されるので,MAC Arrayはそれを処理する演算器のクラスタと理解していい。
IntelによるとMAC Arrayと活性化関数(Activation Function)および畳み込み(Convolution)のアクセラレータによりAIの推論パイプラインを構成できるという。
 |
2基のNeural Compute Engineは,DMAでアクセス可能な高速なSRAMからなるスクラッチパッドメモリ(Scratchpad RAM)とデータをやり取り可能だ。ニューラルネットワークの処理にかかる時間は,NPUにAIモデルをコンパイルする時点で計算できる。そこで,スクラッチパッドメモリとのやり取りをDMAを使ってバックエンドで行えるように,あらかじめスケジュールを決めることで,ニューラルネットワーク処理を高速に実行できるわけだ。これは,AMDのAIアクセラレータにも見られる仕様である。
 |
ちなみに,NPUのベースとなっているのは,「Movidius Myriad Vision Processing Unit」(以下,Myriad VPU)だそうだ。これは,AI向けアクセラレータを手がけていたアイルランドのベンチャー企業であるMovidius(モビディウス)が開発したものだ。
2016年にIntelがMovidiusを買収したのち,Myriad VPUのアーキテクチャを受け継ぐAI向けのアクセラレータ製品は,Intelが発売していた(関連記事)。そんなVPUの最新版が,Meteor LakeにNPUという形で組み込まれたと理解していい。
各Neural Compute Engineは「SHAVE DSP」という演算器を備えている。これもMyriad VPUが備えていたSHAVEプロセッサと同じ働きをする演算器で,センサーや画像の処理に利用できる。
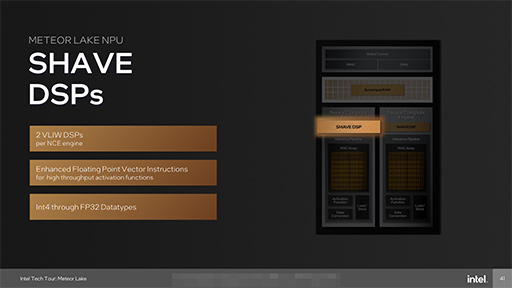 |
NPUの性能指標,たとえば何TOPSであるとかいうような指標は,Intelが明言していないのだが,興味深い利用例を提示している。画像生成AIの「Stable Diffusion」において,GPUのみを使用するよりも,NPUとGPUを併用したほうが電力効率と性能が大幅に向上するという。
Stable Diffusionは,ノイズからそれっぽい画像を引き出す「UNet+」というAIモデルと,粗い画像を綺麗な画像を仕上げる「Variable Auto Decoder」(VAE),そしてテキストを解釈する「Text Encoder」という複数のAIモデルを組み合わせて画像を生成している。Intelによると,それぞれのモデルをNPU,GPU,CPUに分散させることで性能と電力効率を向上させられるそうだ。
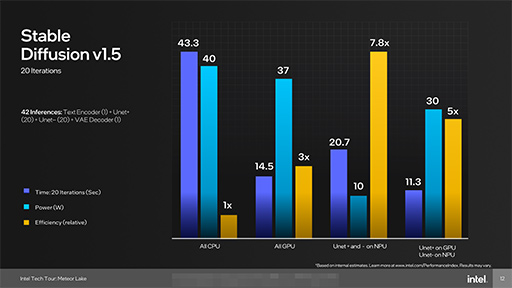 |
NPUは,Windowsにおいては「Windows Machine Learning」(WinML)や「DirectML」,「ONNX Runtime」(ONNX RT)といった業界標準のライブラリやAPIをサポートするほか,Intelが地道に開発を続けていた独自ライブラリ「OpenVINO」をサポートするそうだ。OpenVINOは地味に続いていたので,Meteor Lakeとともにメジャーデビューするとなれば,いろいろな意味で感慨深い。
 |
Intelは,このNPUによって「AIを民主化する」とアピールしている。クラウドで実行するのが当たり前だったAI処理を,クライアント側で高いセキュリティを保ったまま利用できるようにすると約束している。そのため,Meteor Lakeが市場に登場するまでに間に合うように,多数のAIモデルをNPUに移植しているそうだ。
移植しているAIモデルの中には,Metaが公開している大規模言語モデル「LLaMA v2」など,これまでは多量のメモリを積んだGPUがないと利用するのが難しいAIモデルもリストアップされているので,期待したいところだ。
 |
Meteor LakeのNPUや,AMDがAPU製品に組み込んだ「Ryzen AI」といった,新登場のAIアクセラレータは,WinMLやDirectMLに代表される標準的なライブラリやAPIを活用する。AI処理を用いるWindows用アプリケーションは,これらのライブラリやAPIを利用するのが標準になっていくだろう。
これまでは,AIを利用するならCUDAに対応するNVIDIA製のGPUが必要という状況だったのだが,少なくともクライアントPC上でAIの推論を利用するアプリに限れば,NVIDIA製のGPUは必ずしも必要ないという方向になるかもしれない。Meteor Lakeの「AIを民主化」に期待したいところだ。
「Xe LPG」はDirectX 12 Ultimateに完全対応
Meteor Lakeにおけるそれ以外のポイントも,簡単に押さえておこう。
Graphics tileのGPUは,現行世代の統合型グラフィックス機能(以下,iGPU)である「Iris Xe Graphics」で使われた「Xe LP」から,Meteor Lakeで「Xe LPE」に刷新される。
Xe LPEは,「Intel Arc A」シリーズGPUに実装されているXe-HPGに近いアーキテクチャを採用しており,2基のRender Sliceで構成されているそうだ。ひとつのRender Sliceは,4基のXe Coreで構成され,演算ユニットであるVector Engineの総数は128基となる。これは現行のXe LP比で,1.33倍の規模だ。
 |
新GPUでは高い性能が期待できるだけでなく,Xe HPGと同様のレイトレーシングユニットを8基内蔵しているため,「DirectX 12 Ultimate」に完全に対応できるGPUになると,Intelは予告している。現行のXe LPでも,グラフィックス負荷の軽いゲームならフルHD解像度でプレイ可能と言われているので,Meteor Lakeならば,快適にプレイできるゲームがさらに増えるはずだ。
メディアブロックやディスプレイブロックは,すでに述べたようにSoC tile側に移されているが,これらにもXeの名称が与えられている。メディアブロックが「Xe Media Engine」,ディスプレイブロックは「Xe Display Engine」だ。また,これまでのXe Media Engineと同様に,Meteor Lakeでも「AV1」コーデックのハードウェアデコードおよびハードウェアエンコードに対応するという。
 |
SoC tileに,「Wi-Fi 7」対応の無線LAN機能が統合されるのもポイントだ。
Wi-Fi 7は,Wi-Fi 6で160MHzだった帯域を,最大320MHzと倍増させることで広帯域化を計る新しい無線LANの規格である。また,マルチリンク機能によって,ゲームで重要なレイテンシも最大60%低減可能など,ゲーマーにとっても期待できる規格だ。
残念ながら,日本では法規制の関係でWi-Fi 7の認可がすぐに行える状況になく,2024年中に使えるかどうか,という状況らしい。そのため,Meteor Lake搭載ノートPCが2023年に登場しても,Wi-Fi 7がすぐに使えるようにはならない。とはいえ,将来的には使えるようになる可能性もあるので,Meteor LakeがWi-Fi 7に対応しているということは,覚えておくといいだろう。
今回明らかにならなかったMeteor Lakeの性能に関しては,製品のリリースまでに,新たな情報を公開するとIntelは予告している。続報にも期待したい。
Intel公式Webサイト
- 関連タイトル:
 Intel Core Ultra(Meteor Lake)
Intel Core Ultra(Meteor Lake)
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー