









ニュース
Intelが2022年に投入するゲーマー向けGPU「Xe HPG」は,レイトレ&超解像機能搭載でミドルクラス並みの性能か
2021年8月に,Intelが開催した独自のオンラインイベント「Intel
主なテーマは,CPUであったがIntelが開発した独自アーキテクチャのGPU「Intel Xe
2022年第1四半期に登場する予定という新GPUについて,分かったことをまとめてみたい。
以前からIntelは,ゲーマー向け市場に向けて自社のCPUをアピールしてきたが,ゲーム性能の大部分を左右するのは,言うまでもなくGPUである。しかしIntelは,ゲーム用途に十分な性能を有するGPUを持たなかった。
だが2022年になれば,その状況が変わるかもしれない。Intelは2022年第1四半期に,「Intel DG2」と呼ばれていたグラフィックス製品を投入する計画があるからだ。この製品は,開発コードネーム「Alchemist」として呼ばれていたもので,Intel Xeの高性能版であるXe HPG(High Performance Gaming)を搭載する。
そもそもIntelのGPUは,「Execution Unit」(以下,EU)と呼ばれるシェーダユニットを最小単位として,それをクラスター化したユニットを「Slice」(スライス)と呼ぶ構成を採用してきた。Xe HPGも,その構成を踏襲してはいるものの,各部の呼び名は変わっている。
まず,Xe HPGでは,16基のベクタ演算エンジン「Vector Engine」と,16基のマトリックス演算器「Matrix Engine」,それにロードストアユニットやL1キャッシュをひとまとめにしたものを「Xe-core」という基本単位にしているそうだ。
Vector Engineは256bit長の演算器とのことで,従来のEUに相当するユニットと考えていいだろう。従来のEUは,128bit長のベクタ演算器×2,つまり256bitで構成されていたので,Xe HPGのVector Engineも,おおよそそれに似たようなユニットだろうと推測できる。
既存のEUと異なるのは,Vector Engineと同数のMatrix Engineを備える点だ。Matrix Engineは,1024bitの行列計算機で,AIの計算などに用いる。
Xe HPGでは,4基のXe-coreを束ねて,それに4基のレイトレーシング用演算ユニット「Ray Tracing Unit」と4基のサンプラー,ラスタライザーなどを束ねて「Render Slice」を構成する。これが従来で言うところのSliceに相当するわけだ。
Xe-core 1基あたり,16基のVector Engineを備えているので,Render Sliceには16×4=64基のVector Engineを含むことになる。
Xe HPGでは,8基のRender SliceをL2キャッシュを介してクラスター化した構成を取るそうである。
8基のRender Sliceということは,Vector Engineの総数は計512基だ。規模感が分かりにくいと思うので簡単に比較しておくと,ノートPC向けの第11世代Coreプロセッサ(Tiger Lake)に組み込まれたGPU「Intel Xe Graphics」は,EU数が96基なので,その5倍強の規模にあたる。
Xeシリーズ同士での比較では分かりにくいと思うので,ゲーマーにも馴染みがある他社製のGPUと比較してみよう。
たとえば,NVIDIA製GPUのシェーダコアである「CUDA Core」は,32bit浮動小数点(FP32)の積和演算機を持ち,1クロック(サイクル)でFP32の積和算を1回できる。
一方,Xe HPGのVector Engineは,FP32だと8つの積和演算を1クロックで実行できるため,NVIDIA製GPUのシェーダコア8基分に相当すると考えていい。つまり,Xe HPGは,他社製GPUでいうなら4096基のシェーダコアを持つGPUに相当するわけだ。
たとえば,NVIDIAの「GeForce RTX 3060」は,3584基のCUDA Coreを搭載しているので,単純比較であれば「Xe HPGは,GeForce RTX 3060より規模が大きい」と言えそうだが,これはかなり乱暴な表現だ。シェーダコアが多いからと言って,GeForce RTX 3060より性能も高いと言う理屈にはならない。規模的には,ミドルクラス市場向けGPU並みかそれ以上の性能が得られるだろう,と予想できる程度に過ぎない。
なお,Xe HPGの製造はTSMCが担い,プロセス技術には6nmクラスの「TSMC N6」が使われるそうである。
数多くの半導体製造工場を持つIntelが,なぜXe HPGの製造にTSMCを使うのかは推測の域を出ないが,GPUにはCPUなどと異なるプロセス技術のカスタマイズが必要と言われている。TSMCは,NVIDIAのGeForceシリーズやAMDのRadeonシリーズの製造を手かけてきた実績があるので,製造を委託することにしたのかもしれない。
Xe HPGのゲームにおける性能は,実際の製品が出てみないことには分からないが,Intelにとって久しぶり,1998年登場の「Intel 740」以来とすると24年ぶりのゲーマー向けGPUだ。楽しみにしておくといいのではないかと思う。
NVIDIAの「Deep Leaning Super Sampling」(以下,DLSS)に続いて,AMDも「FidelityFX Super Resolution」(以下,FSR)という超解像技術を実装したことで,今後の単体GPUには,超解像技術が必須になってきている。
その理由の1つには,リアルタイムレイトレーシング技術と4K解像度のような高解像度表示の両立が,現在のGPUでは難しいためだ。そこでレンダリング解像度を下げて高いフレームレートを得ながら,超解像技術によって見かけの解像度を引き上げて高解像度映像を作るという手法が使われ始めているためだ。
レイトレーシングをハードウェアでサポートするXe HPGも,もちろん事情は同じであるから,超解像技術は有用だ。そこで,IntelがXe HPGに導入したのが「Xe Super Sampling」(Xe SS)である。
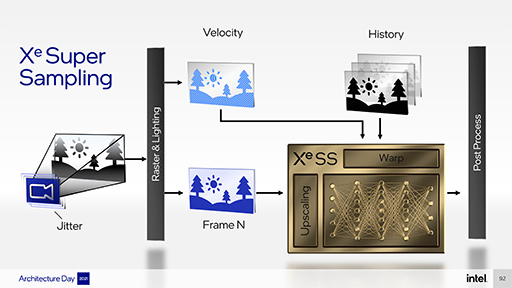
Xe SSの特徴は,NVIDIAのDLSSと同様に,超解像度処理に深層学習ベースの技術を利用する点だ。次のスライドは,Xe SSのおおよその仕組みを示したもので,ラスタおよびライティングの情報と前フレームの情報,オブジェクトの移動量などをもとに,ニューラルネットワークを使って解像度を上げた画像を得るというもののようである。
Intelによると,Xe SSにおける深層学習の処理には,Xe HPGのMatrix Engineがサポートする「XMX」命令を利用する。それだけでなく,Tiger Lakeがサポートしている「Intel Deep Learning Boost」命令(Intel DL Boost,DP4a)で実行することも可能とのことだ。
つまり,Tiger Lakeが搭載する統合型グラフィックス機能(以下,統合GPU)でも,Xe SSを使った解像度の引き上げが(理論的には)可能になるわけだ。統合GPUの場合,1920×1080ドットでさえ,ゲームを快適にプレイできるフレームレートが出せないタイトルも多い。そのため4K解像度ではなく,1920×1080ドットの解像度での快適な表示を得るために,Xe SSを使うといった展開もありえるかもしれない。それが可能なら応用の幅が広がりそうだ。
Xe SSを用いたソフトウェア開発キット(SDK)は,近日中にリリース予定とのこと。SDKには,あらゆるゲームに対応が可能なDeep Learningの学習済みモデルも付属するそうで,すぐにゲームなどに組み込むことができるという。
Xe SSは,広く普及しているIntelの統合GPUでも使えるので,今後の展開に期待したい。
Intelは,ゲーマー向けのXe HPGだけでなく,スーパーコンピュータ向けの「Xe HPC」(High Performance Computing)の情報も明らかにしている。
ゲーマーにはほとんど関係ないGPUであるが,Intelが本格的にNVIDIA製GPUと戦おうという意図が表れた製品なので,ごく簡単に概要をまとめておこう。
Intelによると,Xe-coreの特徴に,命令セットに合わせて内部の構成を柔軟に変えられる(※製品の用途に合わせて構成を変えられる)点があるそうだ。スーパーコンピュータ向けのXe HPCには,ゲーマー向けのXe HPGとは異なる命令セットが求められ,それに対応できるのがXe-coreというわけだ。
なぜそのような特徴を採用したのかというと,おそらくNVIDIA製GPUが「CUDA」に拘束されているためだろう。NVIDIA製GPUは,CUDAの命令セットを実行可能でなければならないために,CUDA Coreの基本機能は改良されているものの,基本構造は長らく変わっていない。
一方でIntelは,「oneAPI」という高レベルのツールキットを提供して,その上で互換性を保つ戦略を採用した。そのため,命令セットレベルでの互換性を保つ必要がない。そのため,必要な命令セットに合わせて内部構成を柔軟に変えられる仕組みを取り入れた,ということだろう。
いずれにしても,Xe HPCのXe-coreは,Xe HPGのそれとはかなり異なる。具体的には,Xe HPGが16基のVector Engineと16基のMatrix Engineを集積していたのに対して,Xe HPCではVector Engine,Matrix Engineともに8基を集積する構成となった。
Vector Engineは512bit長で,FP32およびFP64の演算なら,1クロックあたり256回の演算が可能という。一方のMatrix Engineも,4096bit長とワイド化されている。
このXe coreを16基束ねて,「Xe Slice」を構成しており,さらに4基のXe Sliceを束ねることで,「Xe Stack」という単位を構成するという。Xe Stackは,積層メモリ技術「HBM2e」に対応するメモリコントローラや,他のXe Stackと通信を行うインターコネクト「Xe Link」のインタフェースなどを備えるという。
そして,2基のXe Stackを接続したものが,1基のXe HPCとなる。Xe HPCの実機となる「Ponte Vecchio」(ポンテベッキオ,開発コードネーム)が,試作レベルの「A0シリコン」で動作しているそうだが,これがなかなかとんでもないものだ。Intelのマルチチップ技術「Intel EMIB」(Embedded Multi-die Bridge)と3D積層技術「Foveros」を駆使して,複数のシリコンチップ――Intelは「Tile」と呼んでいる――をひとつのパッケージにまとめているのだ。
パッケージに実装するTileは,製造企業が異なっており,たとえばXe HPCの中核を担う「Compute Tile」は,TSMCの「TSMC 5N」プロセスで製造しており,「Xe Base Tile」は「Intel 7」で製造という具合で,異なるプロセスで製造されたTileを1パッケージにまとめるという複雑ぶりだ。
Ponte VecchioのA0シリコン実動機における性能も公表された。FP32で45 TFLOPS以上とされているが,これがいかにすごいかというと,たとえばNVIDIAのスーパーコンピュータ向けGPU「NVIDIA A100」は,FP32の演算性能が19.5TFLOPSである。つまりPonte Vecchioは,試作チップ段階でNVIDIA A100の2倍を超える性能を持つわけだ。
スライドにはないが,XMXを使用するAI向けのTF32形式※だとFP32の8倍の性能が得られる理屈なので,360 TFLOPS以上となる。NVIDIA A100は同156 TFLOPSなので,AI向けのマトリックス計算でもPonte Vecchioはライバルの2倍以上の性能を持つことになるだろう。
※符号ビットは1bit,仮数項は半精度浮動小数点にならった10bitとして,指数項を8bitとした計19bitの数値表現形式。関連記事
ちなみに,Ponte Vecchioは,米国アルゴンヌ国立研究所が計画しているスーパーコンピュータ「Aurora」が採用することが決まっている。Auroraは2022年に稼働開始予定なので,民生向けのPonte Vecchioも2022年中に登場する可能性もある。
ゲーマー向けGPUであるXe HPGは,ミドルクラス市場向け程度の性能になりそうな規模だが,Ponte Vecchioに関しては,ライバルのNVIDIAを凌駕する性能を実現してくる可能性が高い。GPUの分野でトップを走ってきたNVIDIAだが,Intelの猛追が始まりそうだ。
 |
2022年第1四半期に登場する予定という新GPUについて,分かったことをまとめてみたい。
ゲーマー向けGPUに本腰を入れるIntel
Xe HPGの構造
以前からIntelは,ゲーマー向け市場に向けて自社のCPUをアピールしてきたが,ゲーム性能の大部分を左右するのは,言うまでもなくGPUである。しかしIntelは,ゲーム用途に十分な性能を有するGPUを持たなかった。
だが2022年になれば,その状況が変わるかもしれない。Intelは2022年第1四半期に,「Intel DG2」と呼ばれていたグラフィックス製品を投入する計画があるからだ。この製品は,開発コードネーム「Alchemist」として呼ばれていたもので,Intel Xeの高性能版であるXe HPG(High Performance Gaming)を搭載する。
そもそもIntelのGPUは,「Execution Unit」(以下,EU)と呼ばれるシェーダユニットを最小単位として,それをクラスター化したユニットを「Slice」(スライス)と呼ぶ構成を採用してきた。Xe HPGも,その構成を踏襲してはいるものの,各部の呼び名は変わっている。
まず,Xe HPGでは,16基のベクタ演算エンジン「Vector Engine」と,16基のマトリックス演算器「Matrix Engine」,それにロードストアユニットやL1キャッシュをひとまとめにしたものを「Xe-core」という基本単位にしているそうだ。
 |
Vector Engineは256bit長の演算器とのことで,従来のEUに相当するユニットと考えていいだろう。従来のEUは,128bit長のベクタ演算器×2,つまり256bitで構成されていたので,Xe HPGのVector Engineも,おおよそそれに似たようなユニットだろうと推測できる。
既存のEUと異なるのは,Vector Engineと同数のMatrix Engineを備える点だ。Matrix Engineは,1024bitの行列計算機で,AIの計算などに用いる。
Xe HPGでは,4基のXe-coreを束ねて,それに4基のレイトレーシング用演算ユニット「Ray Tracing Unit」と4基のサンプラー,ラスタライザーなどを束ねて「Render Slice」を構成する。これが従来で言うところのSliceに相当するわけだ。
Xe-core 1基あたり,16基のVector Engineを備えているので,Render Sliceには16×4=64基のVector Engineを含むことになる。
 |
 |
 |
Xe HPGでは,8基のRender SliceをL2キャッシュを介してクラスター化した構成を取るそうである。
 |
8基のRender Sliceということは,Vector Engineの総数は計512基だ。規模感が分かりにくいと思うので簡単に比較しておくと,ノートPC向けの第11世代Coreプロセッサ(Tiger Lake)に組み込まれたGPU「Intel Xe Graphics」は,EU数が96基なので,その5倍強の規模にあたる。
Xeシリーズ同士での比較では分かりにくいと思うので,ゲーマーにも馴染みがある他社製のGPUと比較してみよう。
たとえば,NVIDIA製GPUのシェーダコアである「CUDA Core」は,32bit浮動小数点(FP32)の積和演算機を持ち,1クロック(サイクル)でFP32の積和算を1回できる。
一方,Xe HPGのVector Engineは,FP32だと8つの積和演算を1クロックで実行できるため,NVIDIA製GPUのシェーダコア8基分に相当すると考えていい。つまり,Xe HPGは,他社製GPUでいうなら4096基のシェーダコアを持つGPUに相当するわけだ。
たとえば,NVIDIAの「GeForce RTX 3060」は,3584基のCUDA Coreを搭載しているので,単純比較であれば「Xe HPGは,GeForce RTX 3060より規模が大きい」と言えそうだが,これはかなり乱暴な表現だ。シェーダコアが多いからと言って,GeForce RTX 3060より性能も高いと言う理屈にはならない。規模的には,ミドルクラス市場向けGPU並みかそれ以上の性能が得られるだろう,と予想できる程度に過ぎない。
なお,Xe HPGの製造はTSMCが担い,プロセス技術には6nmクラスの「TSMC N6」が使われるそうである。
数多くの半導体製造工場を持つIntelが,なぜXe HPGの製造にTSMCを使うのかは推測の域を出ないが,GPUにはCPUなどと異なるプロセス技術のカスタマイズが必要と言われている。TSMCは,NVIDIAのGeForceシリーズやAMDのRadeonシリーズの製造を手かけてきた実績があるので,製造を委託することにしたのかもしれない。
Xe HPGのゲームにおける性能は,実際の製品が出てみないことには分からないが,Intelにとって久しぶり,1998年登場の「Intel 740」以来とすると24年ぶりのゲーマー向けGPUだ。楽しみにしておくといいのではないかと思う。
統合GPUも対応可能な超解像技術
Xe Super Sampling
NVIDIAの「Deep Leaning Super Sampling」(以下,DLSS)に続いて,AMDも「FidelityFX Super Resolution」(以下,FSR)という超解像技術を実装したことで,今後の単体GPUには,超解像技術が必須になってきている。
その理由の1つには,リアルタイムレイトレーシング技術と4K解像度のような高解像度表示の両立が,現在のGPUでは難しいためだ。そこでレンダリング解像度を下げて高いフレームレートを得ながら,超解像技術によって見かけの解像度を引き上げて高解像度映像を作るという手法が使われ始めているためだ。
レイトレーシングをハードウェアでサポートするXe HPGも,もちろん事情は同じであるから,超解像技術は有用だ。そこで,IntelがXe HPGに導入したのが「Xe Super Sampling」(Xe SS)である。
Xe SSの特徴は,NVIDIAのDLSSと同様に,超解像度処理に深層学習ベースの技術を利用する点だ。次のスライドは,Xe SSのおおよその仕組みを示したもので,ラスタおよびライティングの情報と前フレームの情報,オブジェクトの移動量などをもとに,ニューラルネットワークを使って解像度を上げた画像を得るというもののようである。
 |
Intelによると,Xe SSにおける深層学習の処理には,Xe HPGのMatrix Engineがサポートする「XMX」命令を利用する。それだけでなく,Tiger Lakeがサポートしている「Intel Deep Learning Boost」命令(Intel DL Boost,DP4a)で実行することも可能とのことだ。
つまり,Tiger Lakeが搭載する統合型グラフィックス機能(以下,統合GPU)でも,Xe SSを使った解像度の引き上げが(理論的には)可能になるわけだ。統合GPUの場合,1920×1080ドットでさえ,ゲームを快適にプレイできるフレームレートが出せないタイトルも多い。そのため4K解像度ではなく,1920×1080ドットの解像度での快適な表示を得るために,Xe SSを使うといった展開もありえるかもしれない。それが可能なら応用の幅が広がりそうだ。
 |
Xe SSを用いたソフトウェア開発キット(SDK)は,近日中にリリース予定とのこと。SDKには,あらゆるゲームに対応が可能なDeep Learningの学習済みモデルも付属するそうで,すぐにゲームなどに組み込むことができるという。
Xe SSは,広く普及しているIntelの統合GPUでも使えるので,今後の展開に期待したい。
スーパーコンピュータ向け
Xe HPCの概要も公開
Intelは,ゲーマー向けのXe HPGだけでなく,スーパーコンピュータ向けの「Xe HPC」(High Performance Computing)の情報も明らかにしている。
ゲーマーにはほとんど関係ないGPUであるが,Intelが本格的にNVIDIA製GPUと戦おうという意図が表れた製品なので,ごく簡単に概要をまとめておこう。
Intelによると,Xe-coreの特徴に,命令セットに合わせて内部の構成を柔軟に変えられる(※製品の用途に合わせて構成を変えられる)点があるそうだ。スーパーコンピュータ向けのXe HPCには,ゲーマー向けのXe HPGとは異なる命令セットが求められ,それに対応できるのがXe-coreというわけだ。
なぜそのような特徴を採用したのかというと,おそらくNVIDIA製GPUが「CUDA」に拘束されているためだろう。NVIDIA製GPUは,CUDAの命令セットを実行可能でなければならないために,CUDA Coreの基本機能は改良されているものの,基本構造は長らく変わっていない。
一方でIntelは,「oneAPI」という高レベルのツールキットを提供して,その上で互換性を保つ戦略を採用した。そのため,命令セットレベルでの互換性を保つ必要がない。そのため,必要な命令セットに合わせて内部構成を柔軟に変えられる仕組みを取り入れた,ということだろう。
いずれにしても,Xe HPCのXe-coreは,Xe HPGのそれとはかなり異なる。具体的には,Xe HPGが16基のVector Engineと16基のMatrix Engineを集積していたのに対して,Xe HPCではVector Engine,Matrix Engineともに8基を集積する構成となった。
Vector Engineは512bit長で,FP32およびFP64の演算なら,1クロックあたり256回の演算が可能という。一方のMatrix Engineも,4096bit長とワイド化されている。
 |
このXe coreを16基束ねて,「Xe Slice」を構成しており,さらに4基のXe Sliceを束ねることで,「Xe Stack」という単位を構成するという。Xe Stackは,積層メモリ技術「HBM2e」に対応するメモリコントローラや,他のXe Stackと通信を行うインターコネクト「Xe Link」のインタフェースなどを備えるという。
 |
そして,2基のXe Stackを接続したものが,1基のXe HPCとなる。Xe HPCの実機となる「Ponte Vecchio」(ポンテベッキオ,開発コードネーム)が,試作レベルの「A0シリコン」で動作しているそうだが,これがなかなかとんでもないものだ。Intelのマルチチップ技術「Intel EMIB」(Embedded Multi-die Bridge)と3D積層技術「Foveros」を駆使して,複数のシリコンチップ――Intelは「Tile」と呼んでいる――をひとつのパッケージにまとめているのだ。
パッケージに実装するTileは,製造企業が異なっており,たとえばXe HPCの中核を担う「Compute Tile」は,TSMCの「TSMC 5N」プロセスで製造しており,「Xe Base Tile」は「Intel 7」で製造という具合で,異なるプロセスで製造されたTileを1パッケージにまとめるという複雑ぶりだ。
 |
Ponte VecchioのA0シリコン実動機における性能も公表された。FP32で45 TFLOPS以上とされているが,これがいかにすごいかというと,たとえばNVIDIAのスーパーコンピュータ向けGPU「NVIDIA A100」は,FP32の演算性能が19.5TFLOPSである。つまりPonte Vecchioは,試作チップ段階でNVIDIA A100の2倍を超える性能を持つわけだ。
 |
スライドにはないが,XMXを使用するAI向けのTF32形式※だとFP32の8倍の性能が得られる理屈なので,360 TFLOPS以上となる。NVIDIA A100は同156 TFLOPSなので,AI向けのマトリックス計算でもPonte Vecchioはライバルの2倍以上の性能を持つことになるだろう。
※符号ビットは1bit,仮数項は半精度浮動小数点にならった10bitとして,指数項を8bitとした計19bitの数値表現形式。関連記事
ちなみに,Ponte Vecchioは,米国アルゴンヌ国立研究所が計画しているスーパーコンピュータ「Aurora」が採用することが決まっている。Auroraは2022年に稼働開始予定なので,民生向けのPonte Vecchioも2022年中に登場する可能性もある。
ゲーマー向けGPUであるXe HPGは,ミドルクラス市場向け程度の性能になりそうな規模だが,Ponte Vecchioに関しては,ライバルのNVIDIAを凌駕する性能を実現してくる可能性が高い。GPUの分野でトップを走ってきたNVIDIAだが,Intelの猛追が始まりそうだ。
IntelのIntel Arc製品情報ページ(英語)
IntelのArchitecture Day 2021特設Webページ
- 関連タイトル:
 Intel Arc(Intel Xe)
Intel Arc(Intel Xe)
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー